描述 Apache HBase
Apache HBase 是開放原始碼的 NoSQL 資料庫,以 Apache Hadoop 作為建置基礎。 HBase 可針對依資料行系列組織的無結構描述資料庫中的大量非結構化及半結構化資料,提供隨機存取功能和強大的一致性。 HDInsight 4.0 HBase 叢集隨附 Apache HBase 2.1.6 和 Apache Phoenix 5。
從使用者觀點來看,HBase 類似於資料庫。 資料會儲存在資料表的資料列和資料行中,而資料列中的資料會依資料行系列分組。 HBase 是一種無架構資料庫,也就是說,資料行和儲存在資料行中的資料類型都不需要定義,就能直接使用。 開放原始碼程式碼會以線性方式調整,以處理數千個節點上數 PB 的資料。
HBase 提供下列功能,因而具有獨特性
一致性的讀取和寫入
低延遲作業
自動分區化
自動區域伺服器容錯移轉
Hadoop/HDFS/MapReduce 整合
Java 用戶端 API
支援非 Java 前端的 Thrift 和 REST
封鎖快取和 Bloom 篩選
Azure HDInsight HBase 搭配 Apache Phoenix 可提供下列額外的好處
SQL 和無 SQL 介面
有彈性的容量規劃
使用 Azure 網路進行全域散發和複寫
區隔計算與儲存
與 HDInsight 企業安全性功能緊密整合
適用於超低延遲讀取和寫入的 HDInsight HBase 加速型寫入
使用 Apache Phoenix 進行類即時 SQL 查詢
搭配使用 Azure HDInsight 與 HBase,可讓您大規模地執行 NoSQL 資料庫。 身為 Contoso 的資料工程師,您必須能夠執行效能評定以了解 HDInsight HBase 的效能和規模,然後才能將平台用於任務關鍵性的生產案例。
HDInsight 上的 HBase 執行時會將計算和儲存分開。 HDInsight HBase 叢集依設定會將資料直接儲存至 Azure 儲存體中,使其在效能與成本的選擇中提供低延遲性與高度彈性。 此屬性可讓客戶建置可搭配大型資料集使用的互動式網站。 這可建置可儲存數百萬端點上之感應器和遙測資料的服務,以及使用 Hadoop 工作分析此資料。 HBase 和 Hadoop 是 Azure 中巨量資料專案的良好起點。 服務可讓即時應用程式使用大型資料集。 HDInsight HBase 實作會使用 HBase 的擴增架構,提供資料表的自動分區化功能。 此外也提供讀取和寫入的高度一致性及自動容錯移轉。 記憶體內快取可增強寫入的讀取和高輸送量串流效能。 可以在虛擬網路內建立 HBase 叢集。 如需詳細資訊,請參閱在 Azure 虛擬網路上建立 HDInsight 叢集。
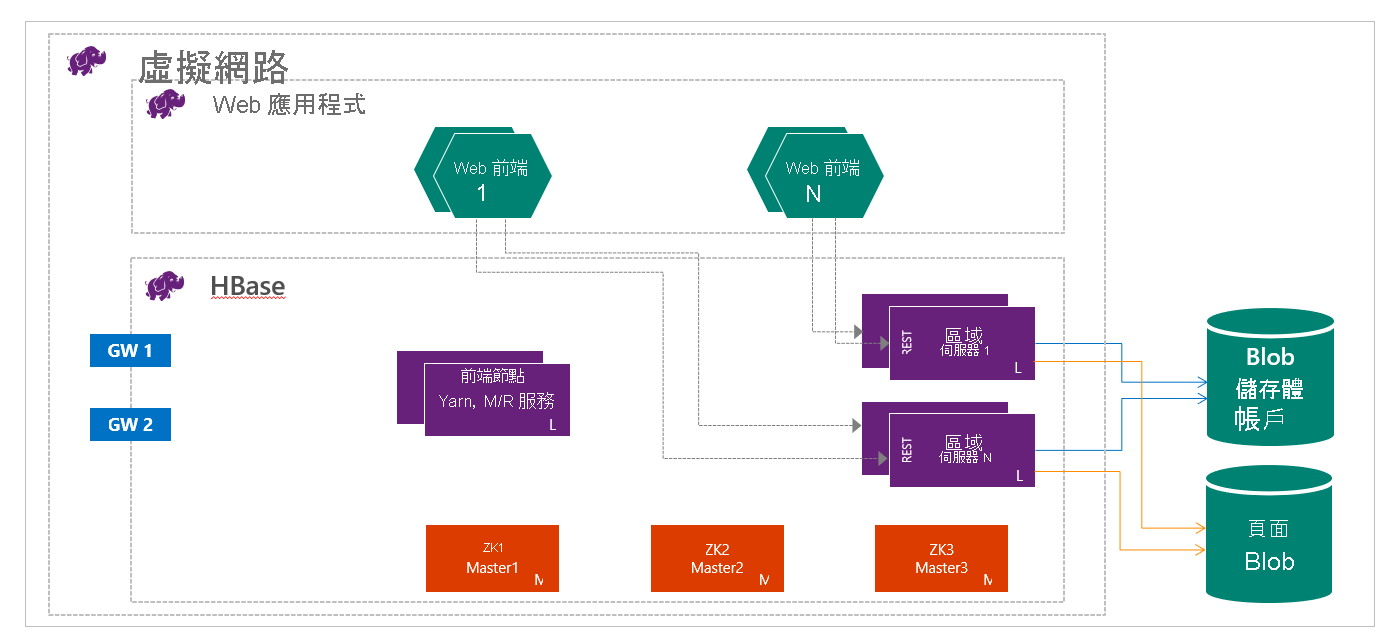
身為資料工程師,您需要決定哪種 HDInsight 叢集最適合建立,以建置您的解決方案。 您將在 HDInsight 中將 HBase 叢集用於以線性方式調整的 NoSQL 資料庫,而達到大量的輸送量,並以低廉的成本提供低延遲的讀取和不受限制的儲存。
以下是在 HDInsight 中使用 HBase 的主要案例。
機碼值存放區
HBase 通常會作為索引鍵-值存放區,也很適合用來管理訊息系統。
感應器資料
HBase 可用來從各種來源 (包括社交分析、時間序列) 擷取以累加方式收集的資料,連同趨勢和計數器將互動式儀表板保持在最新狀態,並管理稽核記錄系統。
即時查詢
Apache Phoenix 是 Apache HBase 的 SQL 查詢引擎。 其會以 JDBC 驅動程式的形式存取,而且可使用 SQL 來查詢和管理 HBase 資料表。
HBase 即平台
應用程式可以使用它作為資料存放區,在 HBase 之上執行。 範例包括 Phoenix、OpenTSDB、Kiji 和 Titan。 應用程式也可以與 HBase 整合。 範例包括 Apache Hive、Apache Pig、Solr、Apache Flume、Apache Impala、Apache Spark、Ganglia 和 Apache Drill。
在 HDInsight 中,HBase 可作為獨立應用程式使用,或與其他巨量資料分析應用程式一起部署,例如 Spark、Hadoop、Hive 或 Kafka。
HBase 資料模型會儲存具有不同資料類型、不同資料行大小和欄位大小的半結構化資料。 HBase 資料模型的配置可簡化整個叢集的資料分割和散發。 HBase 資料模型由數個邏輯元件組成 - 資料列索引鍵、資料行系列、資料表名稱、時間戳記等等。
資料列索引鍵可用來唯一識別 HBase 資料表中的資料列。 在 HDInsight 中,您可以使用多個可用的 API (例如 HBase REST、HBase RPC、Phoenix Query Server、HBase 大量載入) 直接將資料寫入至 HBase,或使用與數個巨量資料架構 (例如 Apache Spark、Hive 等) 的整合。
您可以利用 HBase 加速型寫入功能來啟用高寫入輸送量。 若要深入了解 HBase 架構和最佳做法,請參閱 Hbase 書籍。