簡介
Microsoft合作夥伴,包括像自己這樣的獨立軟體供應商(ISV),可以透過許多不同的支援程式代碼和低程式碼方法來建立產生 AI 解決方案。 為了支援您在這個程式中,Microsoft為 ISV 建立指引 ,以便您更能建置這些解決方案。
由於ISV的目標是管理特製化查詢和工作,因此其產生的AI解決方案的複雜性也會增加。 這些複雜的產生 AI 解決方案需要在開發期間採取獨特的預防措施,並在整個生產環境中進行一致的監視和觀察。 藉由觀察產品的行為和輸出,您可以快速識別成長區域、及時解決風險和問題,並提升應用程式的效能。
建置和運作 Copilot 應用程式
若要瞭解可檢視性如何從解決方案生命周期開始影響您的應用程式,請務必在三個主要階段思考生命週期:思考您的使用案例、建置您的解決方案,以及在部署后將其運作。
標題為真實世界中 LLM 生命週期的影像。 它由三個圓圈組成,與箭號相連,並以標示為「管理」的較大箭號包圍。 第一個圓形標示為「Ideating/Exploring」,並包含「試用提示」、「假設」和「尋找 LLM」。 它源於業務需求箭號,並連接到第二個圓圈,並加上標示為「進階專案」的箭號。 第二個圓形標示為「建置/擴增」,由「擷取增強世代」、「例外狀況處理」、「提示工程或微調」和「評估」組成。 第二個圓形會使用「準備應用程式部署」連接到最後一個圓形。 最後一個圓形是最大的,標示為「可運作」,由「部署 LLM 應用程式/UI」、「配額和成本管理」、「內容篩選」、「安全推出/預備」和「監視」組成。 最後一個圓形會使用「傳送意見反應」連接到第二個圓圈,而第二個則使用 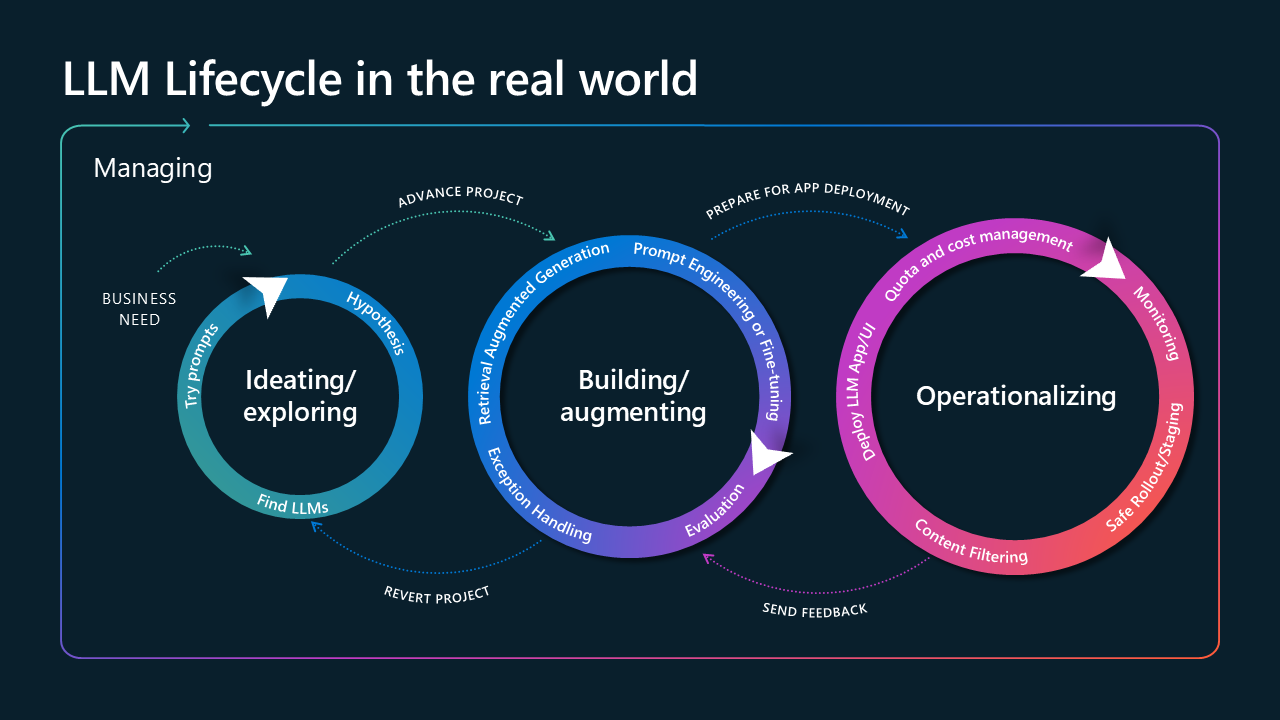
第一個階段是由識別您的使用案例和概念來建立它的技術方法所組成。 一旦您識別建置應用程式的路徑,您就會進入第二個階段,其中包含開發和評估應用程式。 將應用程式部署至生產環境之後,它會進入最後一個階段,您可以在其中觀察和更新。
從第二和第三個階段收集的可觀察性深入解析,在返回舊階段以執行更新和部署時變得至關重要。 藉由執行持續測試和擷取計量來通知先前的程式,您可以持續微調應用程式。
請務必瞭解您可以採取哪些動作來練習程式中不同點的可觀察性。 概括而言,應用程式生命週期期間會發生下列可觀察性動作:
第一階段
- 非技術性角色,例如產品經理會藉由思考其應用程式的關鍵品質來練習可觀察性。
- 項目關係人可以定義哪些計量最重要的計量來測量其應用程式的效能,例如風險和安全計量、品質計量或執行計量。
- Teams 可以定義計量的目標,例如用戶參與和成本管理。
- 技術角色著重於識別最能成功建置應用程式的平臺、工具和方法。
- 此步驟可能包括選擇要使用的模式、選擇大型語言模型 (LLM),以及識別要從中繪製的主要數據源。
第二階段
- 在這個階段中,開發人員和數據科學家可以設定其解決方案,以便輕鬆監視和查看。 若要在稍後提升可觀察性,ISV 可能會:
- 建立黃金數據集和自動化多回合對話數據集,以進行 Copilot 評估。
- 使用數據子集進行偵錯、執行及評估流程。
- 使用不同的提示建立模型評估的變化。
- 執行定價和資源優化,以符合 LLM 成本降低以逐一查看和建置。
- 開發人員著重於在開發期間執行實驗,並在將其應用程式部署到生產環境之前評估其品質。 在這個階段中,請務必:
- 使用預先定義的計量來評估測試數據集的整體應用程式效能,包括模型和提示效能。
- 比較這些測試的結果、建立基準,然後將程式代碼部署到生產環境。
第三階段
- 在生產環境中積極使用應用程式時,會進行許多實驗。 請務必監視您的解決方案,以確保其能充分執行。 在此階段:
- 內嵌在應用程式中的遙測檢測會發出相關的追蹤、計量和記錄。
- 雲端服務會發出 Azure OpenAI 健康情況和其他相關計量。
- 量身打造的遙測記憶體會保存追蹤、計量、記錄、使用量、同意和其他相關計量的數據。
- 預先設定的儀錶板體驗可讓開發人員、數據科學家和系統管理員在生產環境中監視 LLM API 效能和系統健康情況。
- 終端使用者的意見反應會提交給開發人員和數據科學家,以供評估,以協助改善解決方案。
收集數據和遙測可讓您深入瞭解未來要解決和改善的領域。 在構想階段採取先佔式步驟,例如識別適當的計量,並在建置應用程式時對解決方案執行嚴格的評估,您就可以在稍後為解決方案做好準備,以取得成功。
產生 AI 中的可觀察性挑戰
雖然一般可觀察性可能需要ISV流覽許多障礙,但產生式AI解決方案會導入特定的考慮和挑戰。
定性評估
由於產生 AI 提示回應是以自然語言形式提供,因此必須以唯一方式進行評估。 例如,您可以檢查其特性,例如基礎性和相關性。
ISV 必須考慮測量這些品質的最佳路線,無論其選擇手動評估還是 AI 輔助計量,在迴圈中搭配人類進行最終驗證。
無論您評估它的方式為何,您也可能需要預先存在的數據集來比較您的提示回應。 當您識別常見提示主題的理想回應時,這些準備工作可能表示在開發應用程式期間進行更多工作。
負責 AI
道德 AI 的新考慮和期望引進了監視隱私權、安全性、包容性等等的需求。 ISV 必須監視這些屬性,才能提升使用者的安全性、降低風險,以及將負面用戶體驗降到最低。
Microsoft負責任 AI 的六項原則,可協助促進安全、道德且值得信任的 AI 系統。 若要在解決方案中推廣這些值,針對這些標準評估您的應用程式非常重要。
使用量和成本監視計量
令牌是產生式 AI 應用程式的主要測量單位,而且所有提示和響應都會進行標記化,以便測量它們。 追蹤所使用的令牌數目很重要,因為它會影響執行應用程式的成本。
公用程式計量
監視應用程式的用戶滿意度和業務影響,與效能或品質計量一樣重要。 因為 AI 會以不同的方式與客戶互動,因此有新的考慮可監視客戶參與和保留。
您可以透過許多不同的方式來測量 AI 回應的效用度。 例如,提示和回應漏鬥會追蹤互動產生可用或有用的回應所花費的時間長度。 也請務必考慮追蹤使用者與 AI 互動的時間、交談長度,以及使用者接受所提供回應的次數。 在使用者可以編輯回應的案例中,測量編輯距離或編輯響應的範圍至關重要。
效能計量
AI 需要更複雜的高效能系統,必須正確維護,以確保您的解決方案能夠快速且有效率地處理提示和數據。 當產生 AI 以大量不同程度地建立定性內容時,請務必讓系統在不同的案例中評估及測試您的 AI。
由於 LLM 互動比一般應用程式更為複雜,因此必須在多層測量,以找出延遲問題。 例如,標記使用者提示、產生回應,並將回應傳回給用戶的時間可以個別測量,或整體來測量。 應評估工作流程的每個個別元件,以找出潛在問題的區域。
您觀察解決方案的能力也取決於您的部署方法。 ISV 通常會針對其 Copilot 應用程式採用兩種部署模式之一。 您可以在您擁有的環境中部署和管理應用程式,或在屬於客戶的環境中部署應用程式。
若要深入瞭解部署如何影響解決方案類型的可檢視性,請流覽 Pro-code 可檢視性指南。
要監視和評估的計量
在產生 AI 應用程式和機器學習模型的 ISV 領域,請務必持續評估您的解決方案,並及時介入以遏制不想要的行為。 監視與用戶體驗或意見反應、護欄和負責任 AI 相關的計量、輸出的一致性、延遲和成本,對於優化 Copilot 應用程式的效能至關重要。
使用 AI 輔助計量進行定性評估
為了測量定性資訊,ISV 可以使用 AI 輔助計量來監視其解決方案。 AI 輔助計量會利用 GPT-4 之類的 LLM 來評估類似人為判斷的計量,這可讓您更細微地輸入解決方案的功能。
這些計量通常需要參數,例如問題、答案,以及交談中任何周圍的內容。 它們大致分為兩種類別:
- 風險與安全計量會 監視高風險內容,例如暴力、自我傷害、性內容和仇恨內容
- 產生品質計量會 追蹤定性測量,例如:
- 基礎性-模型的回應與來自提示或輸入來源的資訊一致。
- 相關性模型回應與原始提示的關聯性。
- 一致性-模型回應可理解且類似人類的程度。
- 流暢的模型回應的語言、文法和語法。
這類計量可讓ISV更輕鬆地評估其應用程式回應的品質。 它們可快速且可測量地評估許多可能難以解譯的不同值。
負責任的 AI 標準
Microsoft致力於維護負責任 AI 的標準。 為了支援這一點,我們建立了一組 負責任的 AI 標準 ,可協助您降低與產生 AI 相關聯的風險:
- 當責
- 透明
- 公平性
- 包容性
- 可靠性和安全性
- 隱私權與安全性
ISV 可以監視計量,以在發生問題時通知它們。 這些通知可能包含質化 AI 輔助計量,可篩選有害內容的回應或提示,或對特定錯誤或標幟的訊息發出警示 ISV。
例如,Azure OpenAI 提供解決方案,可測量因內容篩選而未傳回內容的已篩選提示和回應百分比。 ISV 應監視傳回這些錯誤的提示,並旨在減少發生的數量。
客戶使用量和滿意度
某些 AI 功能可以與其他類型的應用程式類似,例如監視客戶保留期和使用應用程式所花費的時間。 不過,監視客戶滿意度有許多差異,特別適用於 AI:
- 用戶對回應的反應。 這可透過計量來測量,就像使用者對向上或向下大拇指回應的反應一樣簡單。
- 用戶的回應變更。 在使用者可以修改 AI 回應以符合其需求的案例中,您可以藉由監視使用者修改回應量來取得深入解析。 例如,使用者大幅變更的草稿電子郵件,可能不像使用者依身分傳送的草稿電子郵件那麼有用。
- 用戶的回應使用率。 請考慮監視使用者是否透過您的應用程式採取動作來回應 AI。 如果 AI 建議透過您的應用程式採取動作,請測量接受建議的用戶率。
許多 AI 應用程式的目標是建立您的使用者發現有幫助的回應。 使用提示和回應漏鬥圖是測量解決方案產生有用回應速度的常見方式。 此漏鬥圖會測量解決方案建立使用者保留或結束交談所花費的時間和互動量。
在此概念中,漏鬥圖會在使用者提交提示時開始。 當 AI 產生使用者可以互動的回應時,漏鬥圖會縮小,因為回應會更接近使用者想要的內容。 例如,使用者可以編輯 AI 回應,或要求稍微不同的答案。 一旦使用者對互動感到滿意,他們就會有他們尋找的特定資訊,且漏鬥圖會結束。 測量您的提示需要多少互動,使其從廣泛到有用,且特定有助於判斷應用程式對客戶的有效程度。
藉由觀察您的使用者如何與解決方案互動,您可以推斷您的應用程式有多有説明。 如果您的用戶持續利用 LLM 的輸出而不採取更多動作,則回應可能會對他們有用。
成本監視
由於執行產生式 AI 應用程式所需的資源可以快速加起來,因此必須一致地觀察它們。
可能會影響應用程式成本優化的某些領域包括:
- GPU 使用率
- 記憶體成本和考慮
- 調整考量
確保這些計量的可見度可協助您控制成本,同時設定與這些計量相關的警示系統或自動程式,也有助於提示立即採取行動。
例如,應用程式所使用的提示和完成令牌數目會直接影響您的 GPU 使用率,以及操作解決方案的成本。 密切監視令牌使用量,並在超過特定閾值時設定警示,可協助您隨時瞭解應用程式的行為。
解決方案可用性和效能
如同所有解決方案,一致的 AI 應用程式監視可協助提升高階效能。 產生 AI 應用程式與其他應用程式之間的其中一個主要差異是令牌化的概念,在測量效能時必須考慮此概念。
建置產生的 AI 解決方案的 ISV 可以測量:
- 轉譯第一個令牌的時間
- 每秒轉譯的令牌
- 應用程式可以管理的每秒要求數
雖然所有這些計量都可以測量為群組,但請務必注意 LLM 具有多層。 例如,AI 產生回應所需的時間是由下列時間所組成:
- 從使用者接收提示
- 透過令牌化處理提示
- 推斷任何相關的遺漏資訊
- 產生回應
- 透過Detokenization將此資訊編譯為回應
- 將此回應傳回給使用者
在這些步驟中測量,可協助您識別延遲和發生位置,讓您能夠解決其來源的問題。
其他行性 AI 評估技術
黃金數據集
黃金數據集是一組專家解答,用於提供共同質量保證的實際用戶問題。 這些答案不會用來定型您的模型,但可以與模型提供給相同用戶問題的答案進行比較。
雖然這不是您可以測量的計量,但擁有高品質的標準化回應,您可以比較 LLM 的回應,以協助解決方案輸出。 如此一來, 建立您自己的黃金數據集 來評估 copilot 效能有助於加速您的 Copilot 評估程式。
多回合對話模擬
手動策劃評估數據集主要僅限於單一回合對話,因為難以建立自然音效的多回合聊天。 ISV 可以開發仿真的交談,以測試其副手的多回合交談能力,而不是撰寫腳本互動來比較模型的答案。
此模擬可藉由讓您的 AI 與簡單的虛擬使用者互動,來產生對話。 接著,此使用者會透過預先產生的提示腳本與您的 AI 互動,或透過 AI 產生它們,讓您能夠建立大量的測試對話進行評估。 您也可以使用人工評估工具來與應用程式互動,並產生較長的交談來檢閱。
藉由評估應用程式在較長交談中的互動,您可以評估它如何有效地識別使用者的意圖,並在整個交談中使用內容。 由於許多行用 AI 解決方案旨在建置在多個用戶互動上,因此評估應用程式處理多回合交談的方式非常重要。
開始使用 開發人員工具
ISV 開發人員和數據科學家需要使用工具和計量來評估其 LLM 解決方案。 Microsoft有許多選項可供您探索。
Azure AI Studio
Azure AI Studio 提供模型管理、模型基準檢驗、追蹤、評估及微調 LLM 解決方案的可觀察性功能。
它支援 兩種類型的自動化計量 來評估產生式 AI 應用程式:傳統的 ML 計量和 AI 輔助計量。 您也可以使用 聊天遊樂場 和相關功能,輕鬆地測試您的模型。
提示流程
提示流程 是一套開發工具,旨在簡化 LLM 型 AI 應用程式的端對端開發週期,從原型設計和測試到部署和監視。 提示流程 SDK 提供:
- 內建評估工具 ,可透過 Prompty 支援自定義程式代碼型或以提示為基礎的評估工具,以滿足工作特定的評估需求。
- 提示追蹤會追蹤 提示的輸入、輸出和內容,並讓開發人員識別模型問題的原因和來源
- 監視儀錶板,包括系統(例如令牌使用量、延遲)和自定義計量,以在 Azure AI Studio 和 Application Insights 中支援預先和部署後可觀察性。
其他工具
Prompty 是語言無關的資產類別,可用來建立和管理 LLM 提示。 它可讓您藉由提供設計、測試及增強解決方案的選項來加速開發程式。
PyRIT(適用於 Generative AI 的 Python 風險識別工具) 是Microsoft開放自動化架構,用於紅小組的 Generative AI 系統。 它可讓您根據不同的傷害類別來評估警戒的健全性。
下一步
藉由設計具有可檢視性和監視功能的產生 AI 應用程式,您可以透過生產環境從開發評估其品質。 開始使用可用來開始開發應用程式的工具,或探索監視已在生產環境中的解決方案的選項。
其他資源
如何評估 LLM:完整的計量架構 - Microsoft 研究
評估 LLM 應用程式的進一步指引
開始使用提示流程 - Azure 機器學習 |Microsoft Learn
設定並開始處理提示流程的資訊