反模式是看似有益但會導致效能問題、資源效率低下以及工作流程中潛在失敗的實踐。 透過理解和避免這些反模式,您可以最佳化雲端流程以獲得更好的效能和可靠性。
避免巢狀 For each 迴圈
巢狀 For each 迴圈可能是雲端流程中的資源密集型作業,並影響效能和資源消耗。
- 執行時間:巢狀迴圈可以迅速增加總迭代次數。 例如,如果您有兩個迴圈,每個迴圈有 10 次迭代,則總迭代次數為 10 x 10 = 100。 這種指數級的成長可以延長流程的執行時間,特別是如果每次迭代都處理大型資料集或執行複雜的作業。
- 限制和配額:Power Automate 強制執行限制和配額,例如迴圈內允許的最大迭代次數和總體執行時間。 巢狀迴圈可以快速接近這些限制,導致流程失敗或限制,特別是在處理大型資料集或頻繁執行時。
- 效能影響:巢狀迴圈中的每次迭代都會消耗處理能力和記憶體。 隨著迭代次數的增加,對系統資源的需求也會增加,可能會減慢整個流程。
進一步了解:並行迴圈和分批限制
根據您的情況,您可以透過處理上層資料表中的相關記錄來避免巢狀迴圈。 請考量下列各項:
情境:外部迴圈使用列出資料列動作從 ProductCategory 資料表中擷取 IsPromotion 資料欄為 True 的產品類別清單。 然後,內迴圈處理外迴圈擷取到的每個類別的 Product 資料表中的相關記錄。
替代方法:使用 OData 查詢擴充功能來簡化此過程。 此方法可讓您使用單一 For each 迴圈,將對 Dataverse 的總請求數減少為僅一個 RetrieveMultiple 呼叫。
若要實作 OData 查詢擴充:
- 使用擴充查詢參數指定將 ProductCategory 資料表連結到 Product 資料表的查詢資料欄名稱。 這種方法在單一查詢中擷取相關記錄。 例如,將擴充查詢參數設為
Products($select=ProductName,Price)。 - 使用 $select 參數來限制從相關資料表傳回的資料欄。
- 使用篩選資料列參數直接在查詢資料表的資料欄上套用條件來擷取和處理相關記錄。 例如,將篩選資料列參數設為
IsPromotion eq true。

避免發生無限迴圈
使用 Power Automate,流程可以無限觸發,例如當流程更新觸發它的同一張資料表時。
當您儲存可能導致無限觸發迴圈的流程時,Power Automate 會向您發出警告。
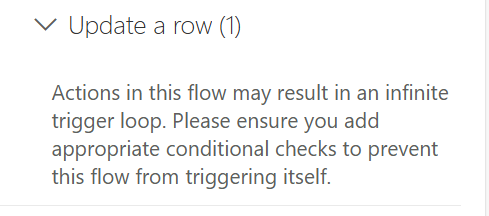
若要避免無限迴圈:
- 使用觸發條件:觸發條件確保流程僅在滿足特定條件時執行,從而防止不必要的執行。 透過向觸發程序新增條件來實現觸發條件,以在流程進行之前檢查某些值或狀態。 例如,如果您的流程更新狀態欄位,則可以設定觸發條件,以便僅在狀態尚未設定為所需值時執行流程。
- 終止流程:另一種方法是,如果偵測到會導致無限迴圈的情況,則停止流程繼續。 當滿足特定條件時,使用終止動作結束流程。 如果流程即將進入無限迴圈,可以使用此方法作為一種保護措施來防止進一步的動作。 例如,如果流程偵測到它已經處理了一筆記錄,它可以自行終止以避免重新處理。
避免大量資料轉換作業
處理大規模資料轉換時,請考慮使用擷取、轉換、載入 (ETL) 流程。 例如,不必使用 Power Automate 雲端流程從大型 Excel 電子資料表中讀取資料,執行資料格式化或驗證,然後將資料寫入 Dataverse。 使用 Power Platform 資料流程或其他 ETL 工具可能更合適。
資料流程可以有效地處理大量資料,並為 ETL 任務提供比雲端流程更好的效能。 ETL 工具提供資料轉換、驗證和載入的專門功能,可簡化複雜的資料處理任務。
若要使用雲端流程中的編排邏輯管理資料負載,請將雲端流程與資料流程結合。 方法如下:
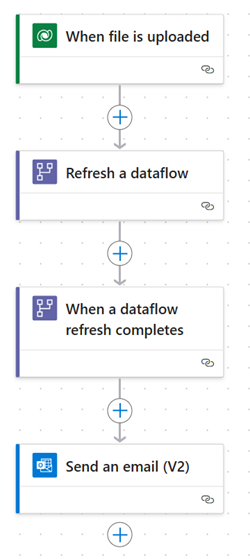
叫用資料流程重新整理
- 動作:使用 Power Automate 中的資料流程連接器觸發重新整理動作,並啟動資料流程中定義的 ETL 流程。
- 範例:設定一個雲端流程,根據計劃 (例如每日) 或事件 (例如,當新文件上傳到 SharePoint 資料夾時) 觸發資料流程重新整理。
ETL 後動作
- 觸發程序:使用 Power Automate 中的當資料流程重新整理完成時觸發程序在 ETL 過程完成後執行動作。
- 範例:資料流程完成後,使用雲端流程傳送通知、更新記錄或執行資料處理。
避免使用 For each 迴圈更新大量記錄
當 Power Automate 中的流程觸發時,使用者通常需要在資料來源中建立或更新數千筆記錄。 許多使用者使用 For each 迴圈按順序處理每筆記錄,導致延遲和延誤。
為了提高效能,請嘗試以下兩種方法:
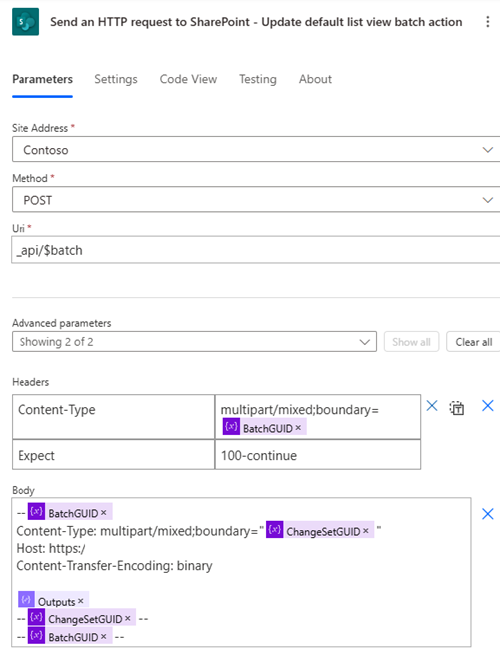
批次作業
- 描述:批次建立或更新記錄。 許多連接器和服務提供支援批次請求的 API 端點。 這種方法可讓您將多個作業分組到單一 HTTP 請求中。
- 實作:使用批次作業功能一次傳送多個建立或更新請求。 這些作業會依照批次請求中指定的順序依序執行。 回應的順序與批次作業中的請求的順序相符。
- 優點:減少發送到資料來源的單獨請求的數量,最大限度地減少延遲並提高效能。
For each 迴圈中的平行性
- 描述:在 For Each 迴圈中啟用並行處理,以同時處理多筆記錄。
- 實作:設定 For Each 迴圈以並行處理最多 50 筆記錄。 對於不支援批次作業的服務來說,這種方法很有用。
- 優點:同時處理多筆記錄,顯著減少了整體處理時間。
有關發出批次請求的資訊,請參閱以下 REST API 文件:
在 Dataverse 中使用批次作業
使用 Dataverse 時,使用批次作業 Web API 來減少所需的動作數量、簡化流程並提高效能。
批次作業 Web API 比批次作業具有明顯的優勢。 它們的差異如下:
- 批次作業:雖然批次作業是在單一請求中發佈的,但它們作為多個單獨的作業執行。 批次內的每個作業都單獨處理。
- 批次作業:相反,批次作業會作為單一作業發佈和執行。 整個批次請求算作一次作業,可以大幅減少動作次數,提高效率。
若要叫用批次作業:
- 使用具有 Microsoft Entra ID 的 HTTP:您可以使用經過 Microsoft Entra ID 驗證的 HTTP 請求叫用批次作業 Web API。
- 將 HTTP 連接器與服務主體一起使用:或者,您可以在使用服務主體叫用這些 API 時使用 Power Automate 中的 HTTP 連接器。
在此範例中,我們使用選擇動作來準備 JSON 格式的記錄:

然後,我們使用 Microsoft Entra ID 的 HTTP 來使用 CreateMultiple Web API 發佈請求:
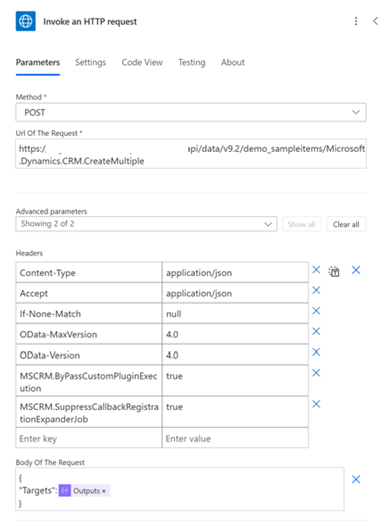
如果 JSON 輸出中有 100 筆記錄,則此方法只會產生一個動作,而不是 Dataverse 中的 100 個「建立資料列」動作。