[本文章是發行前版本文件,且隨時可能變更。]
全新最佳化的 DirectLake 語意模型可加快流程分析速度,並提升記憶體使用效率。 透過節省記憶體,您可以分析更大型的流程,並透過使用較小的 Fabric 容量來執行分析,從而節省成本。 此外,採用了更直觀的 Power BI 語意模型資料結構,讓您能以更少的時間和精力深入深入解析資料。
重要
- 這是預覽功能。
- 預覽功能不供生產時使用,而且可能功能受限。 這些功能是在正式發行前先行推出,讓客戶能夠搶先體驗並提供意見反應。
- 如需詳細資訊,請前往預覽條款。
語意模型描述
當流程發佈到 Fabric 工作區時,它會建立一個新的語意模型和相應的報告。 此螢幕擷取畫面是發佈到 Fabric 的語義模型結構的範例。
選取影像右下角的放大鏡以放大顯示。

關係
視覺效果的篩選和互連所需的關聯性在已發佈的資料模型中預先定義。 除非連接其他資料來源,否則無需手動建立更多關聯性。 在此情境中,請使用 Power BI 複合語意模型,並在該模型的基礎上建立關聯。
資料模型摘要
從邏輯角度來看,資料模型由許多實體子集組成,如本節第一段所述。
- 過程資料:所有未經篩選和計算測量的過程相關資料
- 視覺資料:提供程序探勘自訂視覺效果所需的預先計算資料的實體
- 幫助實體:Power BI 所需的其他實體
以下是子集和所包含實體的簡要描述。
程序資料
程序資料實體的內容在特定場景下會發生變化。
- 當流程模型資料重新整理時
- 建立新檢視時
- 建立新的自訂指標時
- 當使用者在任何流程檢視中變更篩選定義時
使用這些實體可讓您:
- 存取原始過程資料
- 受套用篩選器影響的過程資料
- 存取根據套用的篩選器計算出的度量
| Entity | Description |
|---|---|
| 案例 | 流程中所有案例及其屬性清單。 每個案例包含一個獨特的案例識別碼顯示,以及在對應設定步驟中定義的每個案例屬性的值。 與 CaseMetrics 實體結合,以取得完整的案例資訊。 |
| 事件 | 流程中所有事件屬性的清單。 每個事件都有一個獨特的事件識別索引,以及在對應設定步驟中定義的每個事件屬性的值。 與以 Is_Node 欄位進行篩選的 ProcessMapMetrics 實體結合,以取得完整的事件資訊。 |
| CaseMetrics | 實體包含與案例和檢視的特定組合相關的所有案例層級指標。 Power Automate Process Mining 桌面應用程式中定義的案例層級自訂指標加入到此實體。 |
| AttributesMetadata | 實體保存在將事件日誌資料匯入程序模型時,定義的所有案例/事件層級屬性的定義。 包括其資料類型、屬性類型和屬性層級 (案例或事件)。 |
| MiningAttributes | 保存可用探勘屬性的值。 可以設定程序檢視,以便根據所選的探勘屬性從不同角度查看程序。 如果沒有其他可用的探勘屬性,則實體保存 Activity 屬性的值。 |
| 檢視 | 在 Power Automate Process Mining 桌面應用程式中建立的可用 (已發佈) 檢視清單。 僅公共程序檢視會發佈到資料集。 條目可用於篩選報告、報告頁面和視覺效果,以僅視覺化特定程序檢視中的資料。 |
| 變體 | 實體保存變體和程序檢視之間的關係。 如果在考慮篩選條件後檢視中包含特定變體,則包含記錄。 |
視覺資料
只有當流程模型進行資料刷新時,才會重新計算視覺資料實體。
| Entity | Description |
|---|---|
| ProcessMapMetrics | 流程圖自訂視覺效果中視覺化所需的流程模型中所有節點和轉換的聚合度量。 這個實體結合了事件 (節點) 資訊和邊緣 (轉換) 資訊 — 若要在其他視覺物件中使用事件或邊緣,請依據 Is_Node 欄位的值進行篩選。 Power Automate Process Mining 桌面應用程式中定義的事件層級自訂指標加入到此實體。 |
其他實體
| Entity | Description |
|---|---|
| LocalizationTable | 用於本地化目的的內部資料表。 |
Power BI 綜合模型
我們建議您在 Power Automate Process Mining 發佈的語意模型之上,使用 Power BI 複合模型,並在該模型中針對以下情境進行必要的修改:
- 您需要建立更多資料來源
- 您需要建立更多實體
- 您需要建立更多的關係
- 您需要建立更多自訂 DAX (資料分析運算式) 查詢
重要
語意模型是在 DirectLake 存取模式下建立,但其選項設定為自動。 此設定代表使用非最佳 DAX 查詢或錯誤設定複合模型可能會導致後援到 DirectQuery 模式。 這代表您的報告不會中斷,但您可能會遇到效能下降的情況。
如需了解更多關於在 DirectLake 語意模型之上建立 Power BI 複合資料模型的資訊,請參閱:在語意模型或模型上建立複合模型。
語意模型重新整理
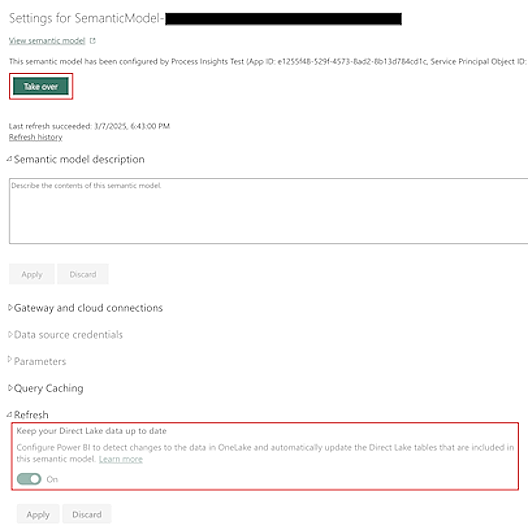
預設情況下,Power Automate Process Mining 會提供的語意模型會自動保持最新。
對於大型資料集,OneLake 中底層表的資料重新整理可能需要更長。 這可能會導致報告出現潛在的不一致。 儘管在資料重新整理結束時存在最終一致性 (語義模型已明確重新整理),但您可能會想要透過關閉語義模型設定畫面中的保持 Direct Lake 資料最新標誌,來避免中間可能出現的不一致情況。
在更新此畫面之前,您需要選擇設定畫面頂端的接管,以取得語意模型的所有權。