適用於:![]() Power BI Desktop
Power BI Desktop ![]() Power BI 服務
Power BI 服務
關鍵影響因素視覺效果可協助您瞭解影響您感興趣計量的因素。 可分析您的資料、為重要因素排名並將其顯示為關鍵影響因素。 例如,假設您想要了解影響員工流動率 (也稱為變換) 的因素。 其中一個因素可能是雇用合約長度,另一個因素可能是在通勤時間。
本文提供如何在Power BI中使用關鍵影響因素視覺效果的逐步教學課程。 它說明如何設定視覺效果、解譯其結果,以及針對常見問題進行疑難解答。 如果您想要瞭解哪些因素會推動數據中的特定結果,例如客戶意見反應、銷售或其他計量,本指南將協助您使用Power BI的 AI 技術支援分析工具取得可採取動作的深入解析。
何時使用關鍵影響因素
如果您想要執行下列作業,關鍵影響因素視覺效果會是不錯的選擇:
- 查看哪些因素會影響正在分析的計量。
- 對比這些因素的相對重要性。 例如,針對客戶流失,短期合約的影響是否大於長期合約?
關鍵影響因素視覺效果的功能
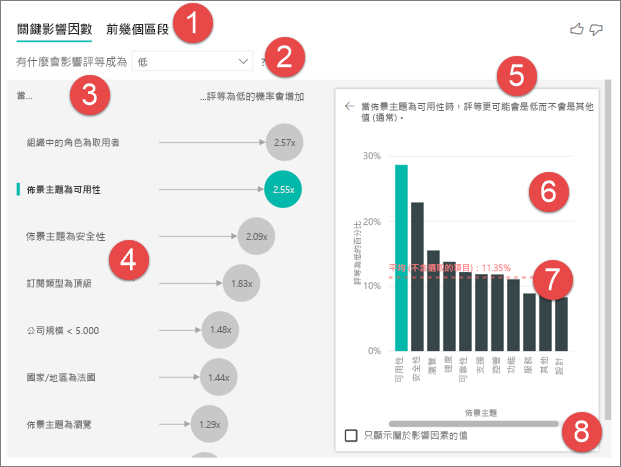
索引標籤:選取索引標籤並在檢視之間切換。 [關鍵影響因素] 顯示所選計量值的主要參與者。 [主要區段] 顯示參與所選計量值的主要區段。 「區段」是值的組合。 例如,其中一個區段可能是成為長期客戶並住在西部區域的取用者。
下拉式方塊:正在調查的計量值。 在此範例中,請查看計量 評等。 選取的值為 [低]。
重述:它可協助您解讀左窗格中的視覺化內容。
左窗格:左窗格包含一個視覺效果。 在此案例中,左窗格會顯示主要關鍵影響因素清單。
重述:它可協助您解釋右窗格中的圖像。
右窗格:右窗格包含一個視覺效果。 就這個案例,柱形圖會顯示左窗格中選取的關鍵影響者 主題 的所有值。 左窗格中的可用性特定值會以綠色顯示。 [主題] 的所有其他值都會以黑色顯示。
平均線:[ 主題 ] 的所有可能值都會計算平均值,但 可用性 除外(這是選取的影響因素)。 因此,計算會套用至所有黑色的值。 它會告訴您其他 主題 中被低評分的比例。 在此案例中,11.35% 具有低評等 (以虛線顯示)。
複選框:篩選出右窗格中的視覺效果,只顯示屬於該字段影響因素的值。
分析類別目錄計量
- 產品經理希望您了解哪些因素會導致客戶對您的雲端服務留下負面評論。 若要參考 Power BI Desktop 中的步驟,請開啟 客戶意見反應 PBIX 檔案。
注意
客戶意見反應資料集乃基於 [Moro et al., 2014] S. Moro、P. Cortez 和 P. Rita。 一種 Data-Driven 方法預測銀行電話行銷的成功。決策支持系統,Elsevier,62:22-31,2014 年 6 月。
在 [視覺效果] 窗格的 [建置視覺效果] 下方,選取 [關鍵影響因素] 圖示。
![[視覺效果] 窗格上 [關鍵影響因素] 圖示的螢幕快照。](media/power-bi-visualization-influencers/power-bi-template-new.png)
將您想要調查的計量移至 [分析] 欄位。 若要了解造成客戶對服務給予低評等的因素,請選取 [客戶資料表]>[評等]。
將您認為可能會影響 評等 的欄位移至 [ 依說明 ] 欄位。 您可以視需要移動許多欄位。 在此案例中,請從下列欄位開始:
- Country-Region
- 組織中的角色
- 訂閱類型
- 公司規模
- 佈景主題
將 [展開依據] 欄位保留空白。 只有在分析量值或摘要欄位時,才會使用此欄位。
若要將焦點放在負面評等上,請在 [影響評等的專案] 下拉式方塊中選取 [低]。
分析會在所分析欄位的資料表層級執行。 在此情況下,它是 評等 指標。 此計量是在客戶層級定義。 每個客戶都會給予高分或低分。 所有說明因素都必須在客戶層級定義,以供視覺效果使用。
在上述範例中,所有說明因素都與計量具有一對一或多對一關聯性。 在此案例中,每個客戶已將單一主題指派給其評等。 同樣地,客戶來自某個國家或地區、具有一種成員資格類型,並在其組織中擔任一個角色。 說明因素已經是客戶的屬性且不需要轉換。 視覺效果可以立即使用。
稍後在教學課程中,您將探討更複雜的範例,包含一對多關聯性。 在這些案例中,資料行必須先向下彙總至客戶層級,才能執行分析。
用於說明因素的量值和彙總,也會在 [分析] 計量的資料表層級進行評估。 本文稍後會顯示一些範例。
解譯類別目錄關鍵影響因素
讓我們探討對於低評等的關鍵影響因素。
可能對低評等造成影響的最主要單一因素
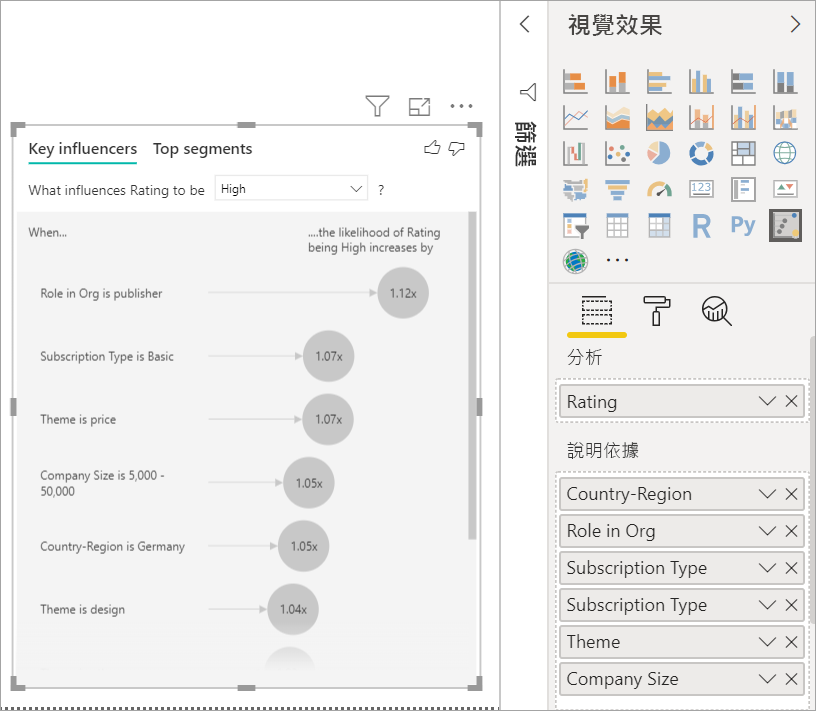
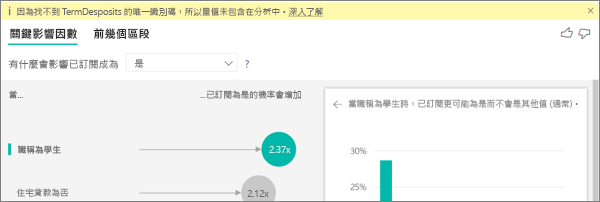
此範例中的客戶可以有三個角色之一:取用者、系統管理員或發行者。 取用者是導致低評等的主要因素。
![主要影響因素的螢幕快照,其中已選取 [組織中的角色] 。](media/power-bi-visualization-influencers/power-bi-role-consumer.png)
更精確地說,取用者給予服務負分的可能性是 2.57 倍。 關鍵影響因素圖表在左側清單中先列出 [組織中的角色是取用者]。 選取 [組織中的角色是取用者],Power BI 即會在右窗格中顯示更多詳細資料。 這會顯示比較每個角色影響低評等的可能性。
- 14.93% 的取用者給予低分。
- 平均而言,所有其他角色在 5.78% 的時間會給予低分。
- 與所有其他角色相比,取用者給予低分的可能性是 2.57 倍。 您可以使用紅色虛線來劃分綠色直條,以決定此分數。
可能對低評等造成影響的第二個單一因素
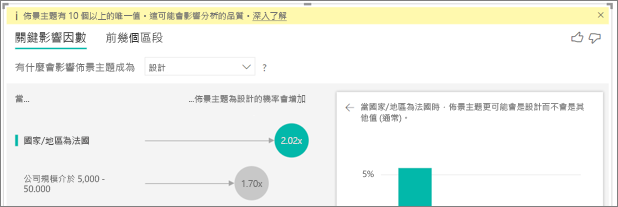
關鍵影響因素視覺效果比較來自許多不同變數的因素並進行排名。 第二個影響因素與 組織的角色無關。選取清單中的第二個影響因素,也就是 主題是可用性。
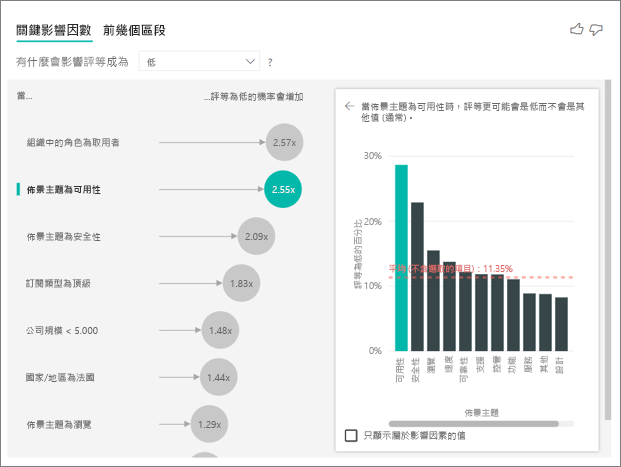
第二個最重要因素與客戶評論的主題相關。 評論產品可用性的客戶,與評論其他主題 (例如可靠性、設計或速度) 的客戶相比,給予低分的可能性高 2.55 倍。
視覺效果之間的平均值 (以紅色虛線顯示) 已從 5.78% 變更為 11.35%。 平均值乃基於所有其他值的平均,因此為動態。 針對第一個影響因素,平均值排除了客戶角色。 針對第二個影響因素,則排除了可用性主題。
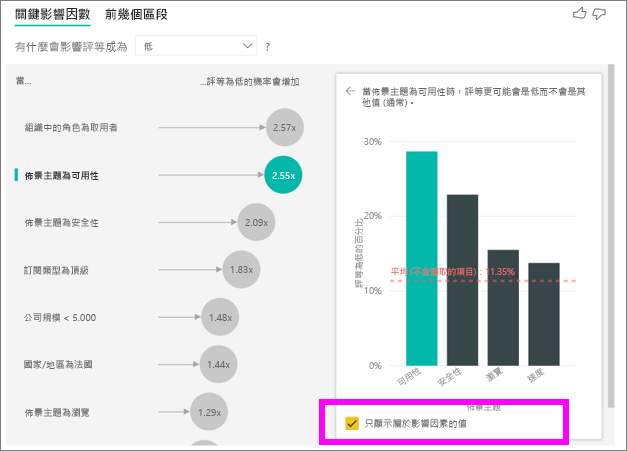
選取 [僅顯示影響因素的值 ] 複選框,以僅使用有影響力的值來篩選數據。 在此案例中為造成低分的角色。 12 個主題會縮減為 Power BI 識別為驅動低評等主題的四個主題。
與其他視覺效果互動
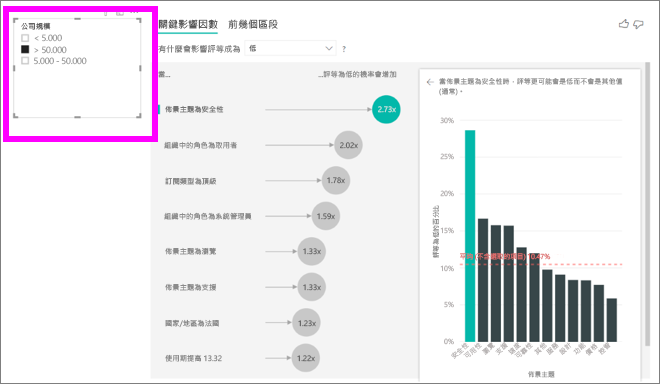
您每次選取交叉分析篩選器、篩選條件或畫布上的其他視覺效果時,關鍵影響因素視覺效果會在資料的新部分重新執行分析。 例如,您可以將 [公司規模] 移至報表作為交叉分析篩選器。 使用它來查看您企業客戶的關鍵影響因素是否與一般母體不同。 企業公司規模大於 50,000 名員工。
選取 [> 50,000] 重新執行分析,而且您可以看到影響因素已變更。 針對大型企業客戶,低評等之主要影響因素具有與安全性相關的主題。 您可能想要進一步調查,確認您的大型客戶是否對特定安全功能不滿意。
解譯連續關鍵影響因素
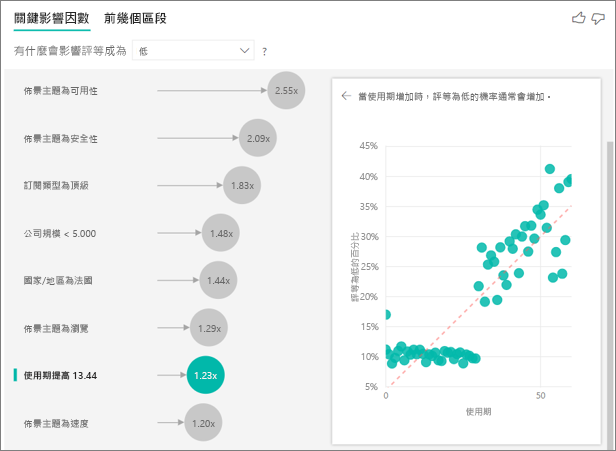
到目前為止,您已了解如何使用視覺效果來探索不同類別欄位對低評等的影響。 您也可以在 [說明依據] 欄位中使用連續因素,例如年齡、高度和價格。 讓我們看看當 使用期 從客戶數據表移至 [說明依據] 時會發生什麼情況。 會員年資顯示客戶使用服務多長時間。
隨著使用期提升,收到較低評等的可能性隨之提高。 此趨勢表示長期客戶較可能給予負面分數。 這是有趣的見解,您可能想要在稍後進行追蹤。
視覺效果顯示每當使用期增加 13.44 個月,收到低評等的可能性平均而言會增加 1.23 倍。 在此案例中,13.44 月表示使用期的標準差。 因此,您得到的見解將探討以標準數量增加之使用期 (使用期的標準差) 會如何影響收到低評等的可能性。
右窗格中的散佈圖會繪製每個任期值之低評等的平均百分比。 它使用趨勢線來醒目提示斜率。
量化連續關鍵影響因素
在某些情況下,您可能會發現連續變數會自動變成類別變數。 如果變數之間的關聯性不是線性,則無法將關聯性描述為只是增加或減少 (就像上述範例中所做的一樣)。
我們會執行相互關聯測試,以判斷影響因素對於目標的線性程度。 如果目標是連續的,我們會執行Pearson相互關聯;如果目標為類別,我們會執行 Point Biserial 相互關聯測試。 如果我們偵測到關聯性不夠線性,則會進行受監督量化,並產生最多 5 個量化。為了找出最合理的量化,我們使用受監督量化方法。 受監督量化方法會查看說明因素與所分析目標之間的關聯性。
將量值和彙總解譯為關鍵影響因素
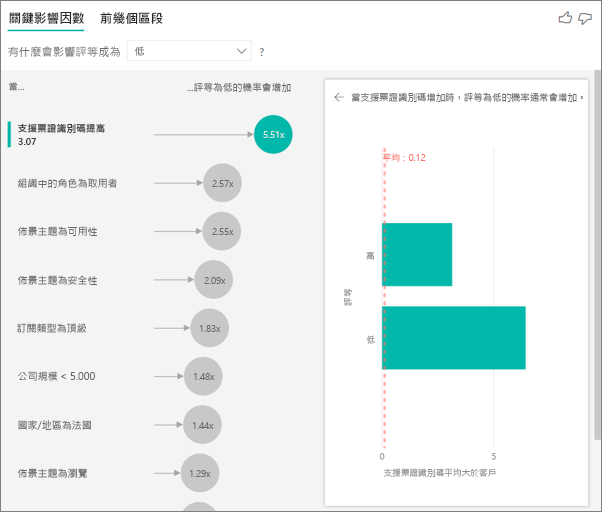
您可以使用量值和彙總作為分析中的說明因素。 例如,客戶支援票證計數對您收到的分數有何影響。 或者,已開啟票證的平均持續時間對您收到的分數有何影響。
在此案例中,您想要了解客戶支援票證數量是否會影響他們給予的分數。 現在,您會從支援票證表帶入支援票證 ID。 由於客戶可能有多個支援票證,因此您需要將識別碼彙總至客戶層級。 彙總十分重要,因為分析是在客戶層級執行,因此必須在該層級的資料粒度上定義所有驅動因素。
讓我們看看識別碼的計數。 每個客戶資料列都具有與其建立關聯的支援票證計數。 在此案例中,隨著支援票證計數增加,收到低評等的可能性隨之提高 4.08 倍。 此螢幕擷取畫面會顯示在客戶層級評估的不同「評等」值的平均支援票證數目。
解譯結果:主要區段
您可以使用 [關鍵影響因素] 索引標籤來個別評估每個因素。 您也可以使用 [主要區段] 索引標籤來了解各種因素組合會如何影響您正在分析的計量。
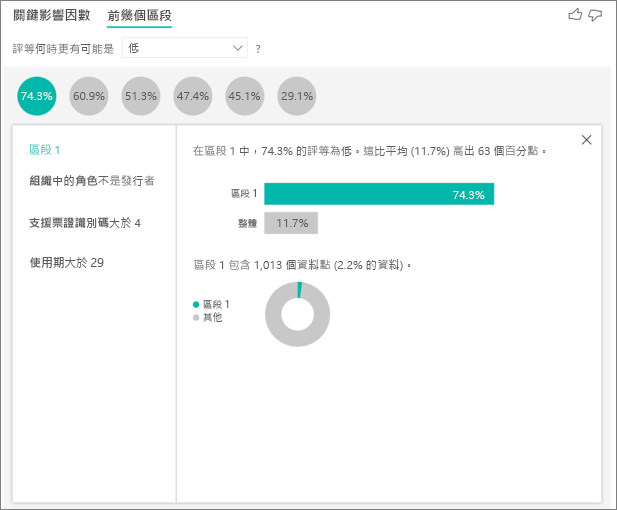
主要區段一開始會顯示 Power BI 發現的所有區段概觀。 下列範例顯示已找到六個區段。 區段內低評等的百分比可決定排名。 例如,區段 1 中 74.3% 的客戶評等為低。 泡泡圖愈高,低評等的比例也愈高。 泡泡圖大小代表該區段內有多少客戶。
![已選取 [頂端區段] 索引標籤的螢幕快照。](media/power-bi-visualization-influencers/power-bi-top-segments-tab.png)
選取一個泡泡,即會顯示該區段的詳細資料。 例如,如果您選取 [區段 1],則會發現其代表已建立的客戶。 他們成為客戶已超過 29 個月,並擁有四個以上的支援票證。 最後,他們並非發行者 (所以他們是取用者或管理員)。
在此群組中,74.3% 的客戶給予低評等。 平均客戶在 11.7% 的時間給予低評等,因此該區段的低評等比例較高。 高出 63 個百分點。 區段 1 也包含約 2.2% 的資料,因此其代表母體的可定址部分。
新增計數
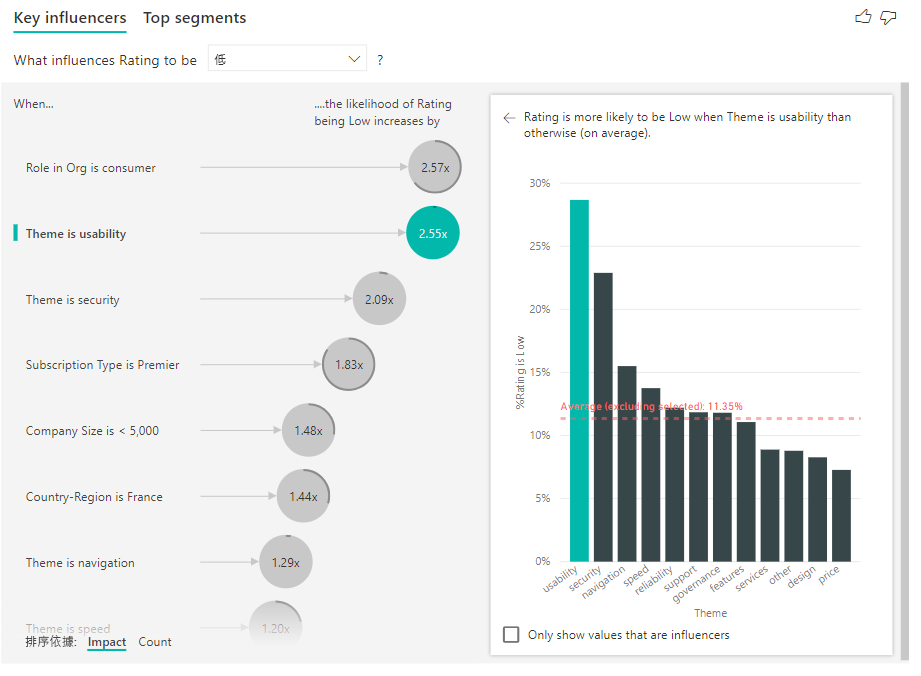
影響因素有時可能會有重大影響,但代表非常少的資料。 例如,[主題是可用性] 是低評等的第三大影響因素。 不過,可能只有少數客戶會抱怨可用性。 計數可協助您排列想要專注的影響因素優先順序。
您可以透過 [格式視覺效果] 窗格的 [分析] 卡片 開啟計數。
![[格式] 窗格中 [啟用計數] 滑桿的螢幕快照。](media/power-bi-visualization-influencers/power-bi-ki-counts-toggle.png)
啟用計數之後,您將會在每個影響因素的泡泡周圍看到環形,其代表影響因素所包含資料的約略百分比。 環形包圍泡泡的面積越多,它所包含的資料就越多。 我們可以看到 [主題是可用性] 包含少量資料。
您也可以使用視覺效果左下方的 [排序依據] 切換,先依計數 (而不是影響) 來排序泡泡。 訂閱類型是 頂級,它是基於數量的最大影響者。
![顯示[排序依據]按鈕的螢幕快照,已切換為先依計數排序。](media/power-bi-visualization-influencers/power-bi-ki-counts-sort.png)
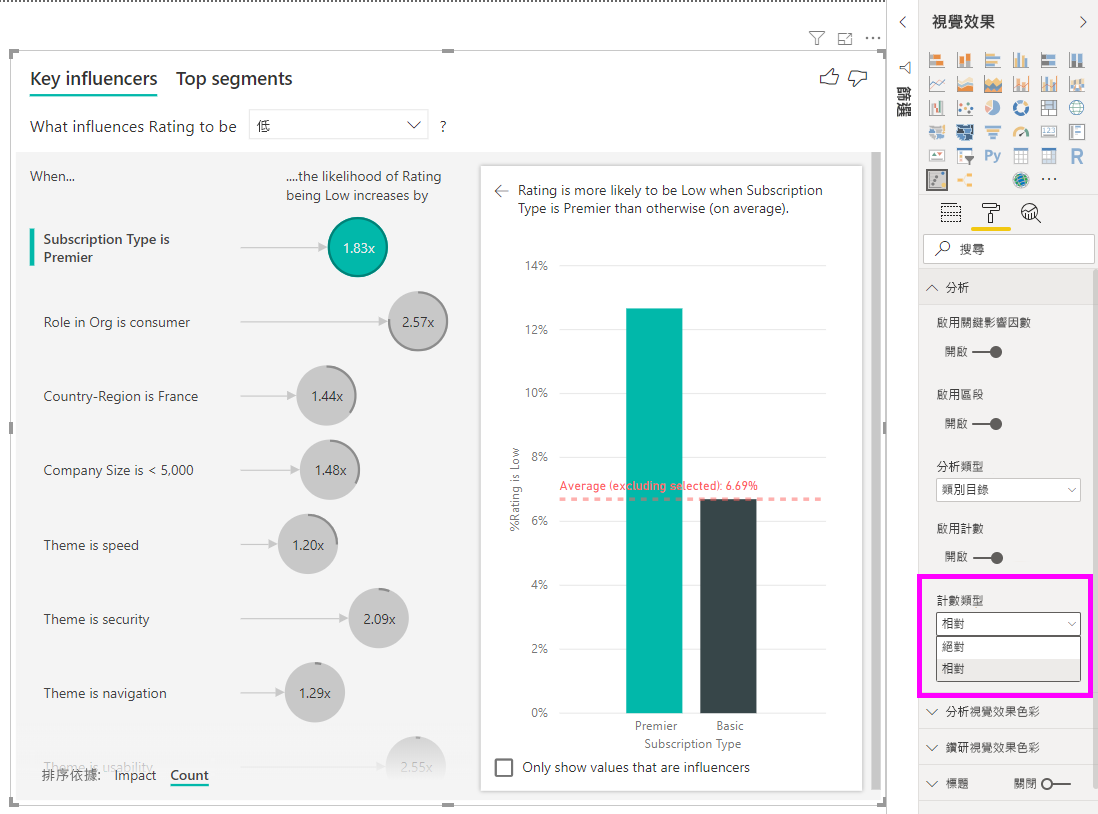
在圓形周圍具有全環表示影響因素包含 100% 的資料。 您可以使用 [格式視覺化窗格] 的 分析卡片 上的 計數類型 下拉式清單,將計數類型變更為相對於最大影響因素。 現在,具有最多資料量的影響因素會以全環代表,而所有其他計數都會與其相對。
分析數值計量
如果您將未摘要的數值欄位移至 [分析] 欄位,您就可以選擇如何處理該案例。 您可以移至 [ 格式化視覺效果 ] 窗格,並在 [類別分析類型 ] 和 [ 連續分析類型] 之間切換,來變更視覺效果的行為。
本文稍早會說明類別分析類型。 例如,如果您查看範圍 1 到 10 的問卷分數,則可以詢問「有什麼會影響問卷分數成為 1?」
連續分析類型會將問題變更為連續的問題。 使用上述範例,我們的新問題會是「有什麼會影響問卷分數增加/減少?」
當您所分析的欄位中有許多唯一值時,這項區別十分有用。 在下一個範例中,我們會查看房價。 詢問「有什麼會影響房價成為 156,214?」並不具意義,因為這是特定情況,而且我們可能沒有足夠的資料來推斷模式。
相反,我們可能會想問,“影響房價上漲什麼”,這允許我們把房價視為一個範圍,而不是不同的值。
解譯結果:關鍵影響因素
注意
本節中的範例會使用公用網域房價資料。 如果您想要跟著做 ,可以下載範例數據集 。
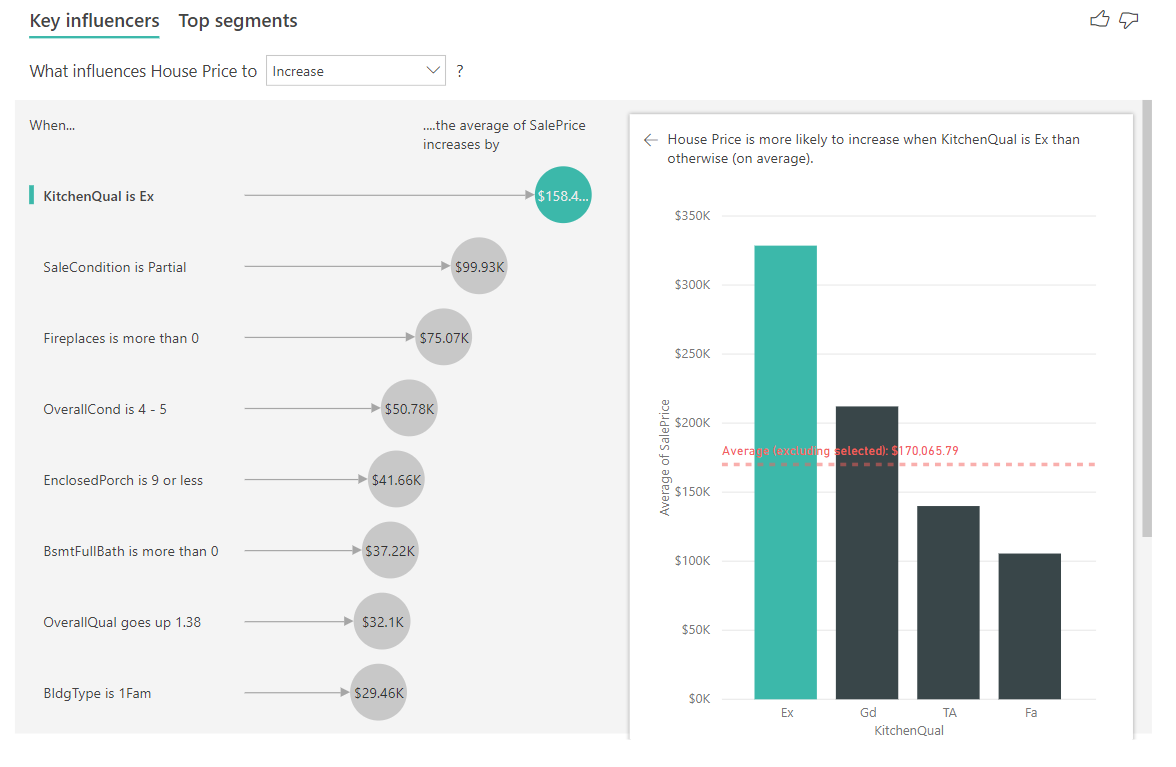
在此案例中,我們將探討「影響房價上漲的影響」。一些解釋性因素可能會影響房價,如 建年(房屋建成 年份)、 廚房品質 ,以及 YearRemodAdd (房屋改造年份)。
在下列範例中,我們會查看絕佳廚房品質的主要影響因素。 結果與我們在分析類別計量時所看到的結果類似,但有一些重大差異:
- 右側直條圖會顯示平均值,而不是百分比。 因此,它向我們展示了擁有優秀廚房的房子的平均房價(綠色條形圖),與沒有優秀廚房的房子的平均房價(點狀線)相比。
- 泡泡中的數位仍然是紅色虛線和綠色橫條之間的差異,但它以數位表示(\$158.49K),而不是可能性(1.93x)。 因此,平均而言,擁有高檔廚房的房屋比沒有高檔廚房的房屋貴將近16萬美元。
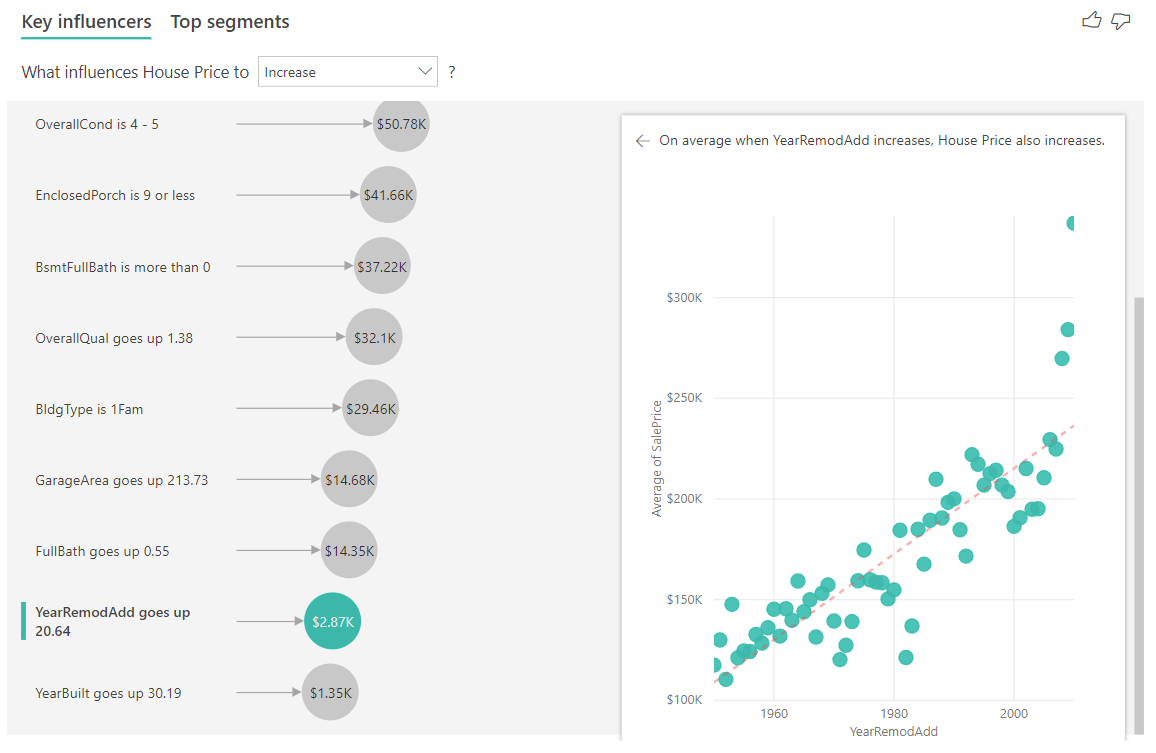
在下一個範例中,我們看看持續因素(年房被改造)對房價的影響。 這相較於我們如何分析類別目錄計量的連續影響因素有下列不同之處:
- 右窗格中的散佈圖會繪製每個不同重建年份的平均房價。
- 泡沫中的值顯示平均房價上漲多少(在此案例中為 $2.87K),當房屋的翻修年份增加其標準差(在此案例中為20年)時。
最後,在量值案例中,我們將查看平均房屋建造年份。 分析如下:
- 右窗格中的散佈圖會繪製數據表中每個相異值的平均房價。
- 泡泡中的值顯示平均房價在平均年份增加其標準偏差(在此案例中為30年)時上漲多少。在此案例中,房價上漲\$1350。
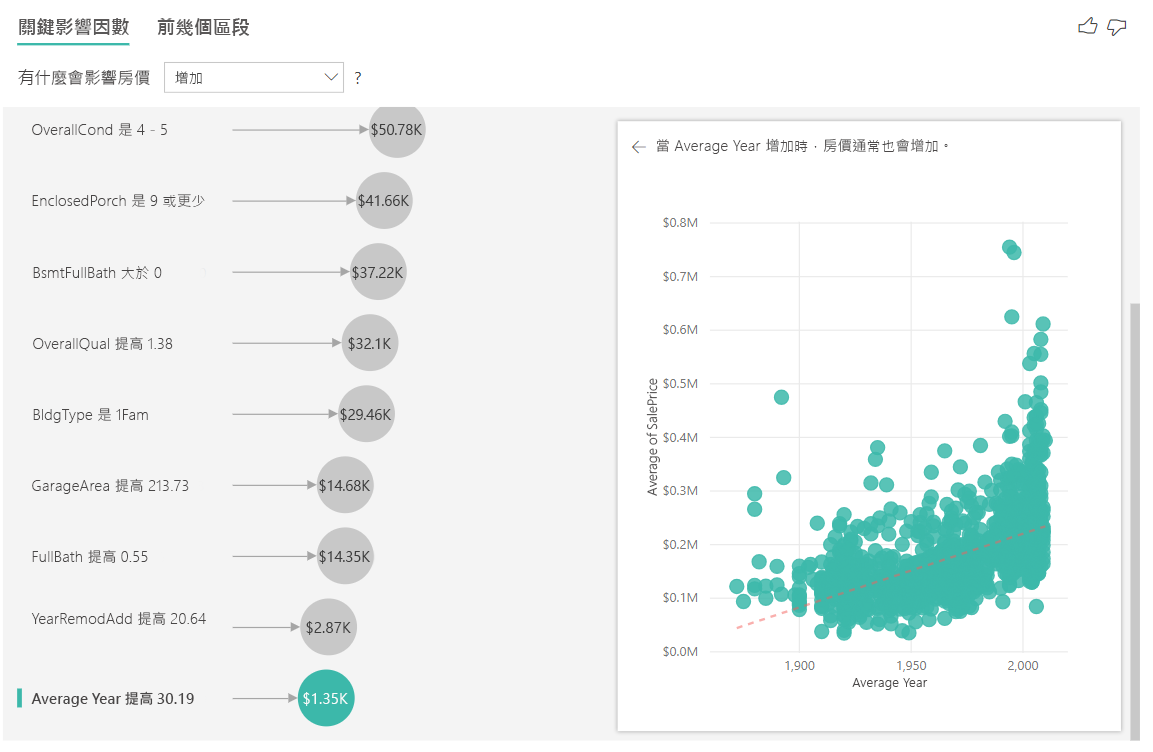
使用頂級區段解析結果
數值目標主要區段顯示房價平均高於整體資料集的群組。 例如,下面我們可以看到 第 1 段落 是由車庫可容納汽車數目大於 2 的房屋組成,並且 屋頂樣式 是 四坡頂。 具有這些特性的房屋的平均價格為 \$355K,而數據中的整體平均值為 \$180K。
分析量值或摘要資料行計量
針對量值或摘要數據行,分析預設為本文稍早所述的連續分析類型。 無法加以變更。 分析量值/摘要資料行與未摘要數值資料行之間的最大差異,在於分析執行的層級。
針對未摘要資料行,分析一律會在資料表層級執行。 在房價範例中,我們已分析 [房價] 計量來查看有什麼會影響房價變高/變低。 分析會自動在資料表層級執行。 在我們的資料表中,每個房屋有唯一的識別碼,因此分析會在房屋層級執行。
針對量值和摘要資料行,我們不會立即得知分析所在的層級。 如果 [房價] 已摘要為 [平均值],我們必須考慮想要計算此平均房價的層級。 這是鄰近地區層級的平均房價嗎? 還是區域層級?
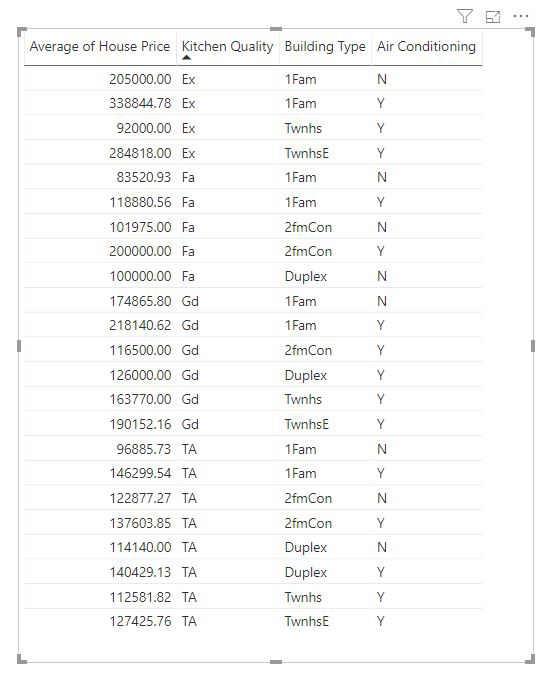
量值和摘要資料行會自動在所使用的 [說明依據] 欄位層級分析。 想像一下,我們想要在說明中檢查三個字段:廚房品質、建築類型和空調。 房價的平均值會針對這三個字段的每個唯一組合來計算。 切換至表格檢視以了解正在評估的數據如何呈現,通常是很有幫助的。
此分析已高度摘要,因此回歸模型可能很難在可從中學習的數據中找到任何模式。 我們應該以更詳細的層級執行分析,以獲得更好的結果。 如果我們想要在房屋層級分析房價,則需要明確地將 [識別碼] 欄位新增至分析。 不過,我們不想要將房屋識別碼視為影響因素。 學習到,隨著房屋標識碼的增加,房屋價格的升高並沒有幫助。 [ 依欄位展開 ] 選項在這裡派上用場。 您可以使用 Expand by 來新增您想要用來設定分析層級的欄位,而不需要尋找新的影響因素。
看看當我們將ID新增至按...展開之後,視覺效果。 定義要評估量值的層級後,解讀影響因素與 未匯總的數值欄完全相同。
若要瞭解 Power BI 如何使用幕後 ML.NET,以自然的方式推斷數據和表面見解,請參閱 Power BI 使用 ML.NET 來識別關鍵影響因素。
考量與疑難排解
視覺效果的限制為何?
關鍵影響因素視覺效果有一些限制:
- 不支援直接查詢。
- 不支援對 Azure Analysis Services 和 SQL Server Analysis Services 的實時連線。
- 不支援發佈至 Web。
- 需要 .NET Framework 4.6 或更高版本。
- 不支援 SharePoint Online 內嵌。
- 如果數據模型設為true,並且禁止隱含量值,則不支援分析屬於類別的指標,例如在數據模型中定義計算群組時。
我看到一項錯誤:找不到影響因素或區段。 這是為什麼?
如果您在 [說明依據] 中包含欄位但未發現影響因素,則會出現此錯誤。 檢查下列其中一個問題是否適用。
- 您在 [分析] 和 [說明依據] 中包含了您正在分析的計量。 請從 [說明依據] 中將其移除。
- 您的說明欄位具有太多類別與太少觀察值。 這種情況會讓視覺效果難以判斷哪些因素是影響因素。 它很難根據少數觀察值來進行一般化。 如果您要分析數值欄位,您可能會想要在分析卡片的格式圖表窗格中,從類別分析切換為連續分析。
- 您的說明因素有足夠觀察值來進行一般化,但視覺效果找不到任何有意義的關聯性來回報。
我看到一項錯誤:我正在分析的計量沒有足夠資料來執行分析。 這是為什麼?

視覺效果運作方式是查看一個群組與其他群組的資料模式比較結果。 例如,它會尋找給予低評等和給予高評等的客戶比較結果。 如果您模型中的資料只有少數觀察值,則很難找到模式。 如果視覺效果沒有足夠資料來尋找有意義的影響因素,則會指出需要更多資料來執行分析。
建議您對所選狀態進行至少 100 次觀察。 在此案例中,狀態是流失的客戶。 您也需要對用於比較的狀態進行至少 10 次觀察。 在此案例中,比較狀態是未流失的客戶。
如果您要分析數值欄位,您可能會想在 分析 卡片的 格式視覺效果 窗格中,從 類別分析 切換為 連續分析。
我看到一項錯誤:未針對 [分析] 進行摘要處理時,分析一律會在其父資料表的資料列層級執行。 不允許透過 [展開依據] 欄位變更此層級。 這是為什麼?
分析數值或類別目錄資料行時,分析一律會在資料表層級執行。 例如,如果您要分析房價,而且您的資料表包含 [識別碼] 資料行,則會在房屋識別碼層級自動執行分析。
當您要分析量值或摘要資料行時,需要明確地指出要執行分析的層級。 您可以使用 [展開依據] 來變更量值和摘要資料行的分析層級,而不需要新增影響因素。 如果已將 [房價] 定義為量值,則您可以將 [房屋識別碼] 資料行新增至 [展開依據] 來變更分析層級。
我看到一項錯誤:[說明依據] 中的欄位與包含所分析計量的資料表不具有唯一關聯性。 這是為什麼?
分析會在所分析欄位的資料表層級執行。 例如,如果您分析客戶對服務的意見反應,您可能會擁有告訴您客戶給予高評等或低評等的資料表。 在此案例中,您的分析會執行於客戶資料表層級。
如果定義相關資料表的層級比包含計量的資料表更為精細,則您會看到此錯誤。 以下是範例:
- 您分析導致客戶給予服務低評等的原因。
- 您想要了解客戶使用服務的所在裝置,是否會影響他們給予的評論。
- 客戶可以透過多種不同方式來使用服務。
- 在下列範例中,客戶 10000000 使用瀏覽器和平板電腦來與服務互動。
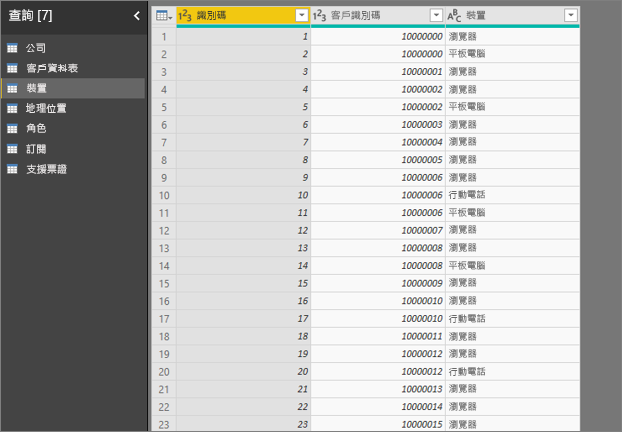
如果您嘗試使用裝置的資料行作為說明因素,您會看到下列錯誤:

因為裝置並非在客戶層級上定義,所以會出現此錯誤。 一個客戶可以在多部裝置上使用服務。 若要讓視覺效果找出模式,裝置必須是客戶的屬性。 根據您對商務的理解,有幾個解決方法:
- 您可以將裝置摘要變更為計數。 例如,如果裝置數量可能會對客戶給予的分數造成影響,請使用計數。
- 您可以轉換裝置資料行,查看在特定裝置上使用服務是否會影響客戶的評等。
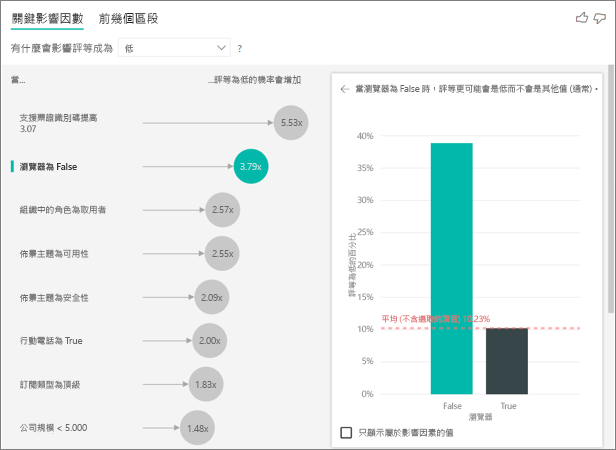
在此範例中,資料已經樞紐分析,以建立瀏覽器、行動和平板電腦的新資料行 (請務必在轉換資料之後,在模型化視圖中刪除並重新建立關聯性)。 您現在可以在 [說明依據] 中使用這些特定的裝置。 所有裝置都是影響因素,而瀏覽器對客戶分數的影響最大。
更精確地說,不透過瀏覽器來使用服務的客戶,比透過瀏覽器的客戶,給予低分的可能性高出 3.79 倍。 在清單中較低的位置,對於行動裝置情況恰好相反。 使用行動應用程式的客戶會比不使用行動應用程式的客戶更可能給予低分。
我看到一項警告:我的分析中未包括量值。 這是為什麼?
分析會在所分析欄位的資料表層級執行。 如果您分析客戶流失,您可能會擁有告訴您客戶是否流失的資料表。 在此案例中,您的分析會執行於客戶資料表層級。
根據預設,量值和匯總預設會在數據表層級進行分析。 如果有平均每月消費的量值,該量值會在客戶資料表層級進行分析。
如果客戶資料表不具有唯一識別碼,您即無法評估該量值且分析會將其忽略。 若要避免這種情況,請確定包含計量的資料表具有唯一識別碼。 在此案例中為客戶資料表,而唯一識別碼為客戶識別碼。 使用 Power Query 來新增索引資料行也很容易。
我看到一項警告:我正在分析的計量具有超過 10 個唯一值,而且此數量可能會影響我的分析品質。 這是為什麼?
AI 視覺效果可以分析類別目錄欄位和數值欄位。 針對類別欄位,範例可能是『流失為「是」或「否」』」,以及『客戶滿意度為「高」、「中」或「低」』。 增加要分析的類別數量,表示每個類別中的觀察值會較少。 這種情況會導致視覺效果更難在資料中找到模式。
分析數值欄位時,您可以選擇將數值欄位視為文字,在此情況下,您執行的分析與類別數據相同的分析(類別分析)。 如果您有許多相異值,建議您將分析切換至 連續分析,這表示我們可以從數位增加或減少時推斷模式,而不是將它們視為相異值。 您可以在分析卡上的格式視覺效果窗格中,從類別分析切換為連續分析。
若要尋找更強的影響因素,建議您將類似的值分組至單一單位。 例如,如果您有價格的計量,則將類似價格分組為「高」、「中」和「低」類別,可能會取得比使用個別價格點更好的結果。
我的資料中有一些因素看起來應該是關鍵影響因素,但事實上並不是。 此情況如何發生?
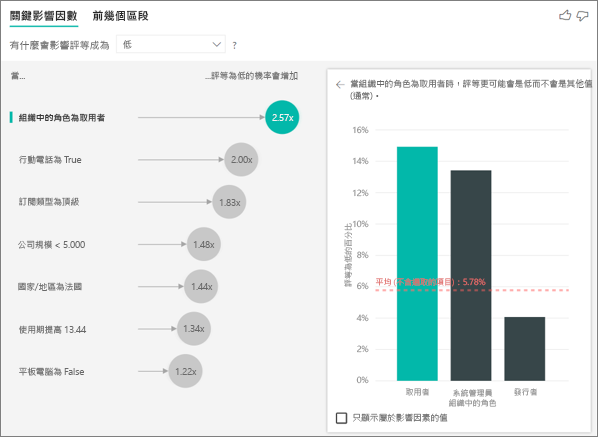
在下列範例中,身分為取用者的客戶會造成低評等 (14.93% 的評等為低)。 管理員角色的低評分比例高達 13.42%,但不被視為有影響力的角色。
此判斷的原因是視覺效果在尋找影響因素時也會考慮資料點的數量。 下列範例有超過 29,000 名取用者,比管理員人數 (大約 2,900) 少 10 倍。 只有 390 名給予低評等。 視覺效果沒有足夠資料來判斷它是使用管理員評等來發現模式或只是碰巧發現。
關鍵影響因素的數據點限制為何?
我們對包含 10,000 個資料點的範例執行分析。 其中一側中泡泡會顯示所有找到的影響因素。 另一邊的柱形圖和散佈圖會遵守這些核心視覺效果的取樣策略。
如何計算類別分析的關鍵影響因素?
在幕後,AI 視覺效果會使用 ML.NET 來執行羅吉斯回歸來計算主要影響因素。 羅吉斯迴歸是一種統計模型,將不同的群組互相比較。
如果您想要了解造成低評等的因素,羅吉斯迴歸會查看給予低分和給予高分的客戶有何不同。 如果您有多個類別 (例如高分、中間分數和低分),您可以查看給予低評等與未給予低評等的客戶有何不同。 在此案例中,給予低分和給予高評等或中間評等的客戶有何不同?
羅吉斯迴歸會搜尋資料中的模式,並找出給予低評等和給予高評等的客戶有何不同。 例如,它可能會發現擁有較多支援票證的客戶,會比幾乎沒有或完全沒有支援票證之客戶給予更高百分比的低評等。
羅吉斯迴歸也會考慮有多少資料點存在。 例如,如果扮演系統管理員角色的客戶會按比例給予更多負面分數,但只有少數系統管理員,則此因素不會被視為具影響力。 此判斷的原因是因為沒有足夠資料點可用於推斷模式。 統計測試 (稱為 Wald 測試) 用於判斷某因素是否視為影響因素。 視覺效果會使用 0.05 的 p 值來決定閾值。
如何計算數值分析的關鍵影響因素?
在幕後,AI 視覺效果會使用 ML.NET 來執行線性回歸來計算主要影響因素。 線性迴歸是一種統計模型,可查看您所分析欄位的結果如何根據您的說明因素而變更。
例如,當我們分析房價時,線性回歸會觀察擁有絕佳廚房對房價的影響。 具由絕佳廚房的房屋相較於沒有絕佳廚房的房屋,房價通常較低或較高?
線性迴歸也會考慮資料點數量。 例如,如果具有網球場的房屋價格較高,但具有網球場的房屋為少數,則不會將此因素視為具影響力。 此判斷的原因是因為沒有足夠資料點可用於推斷模式。 統計測試 (稱為 Wald 測試) 用於判斷某因素是否視為影響因素。 視覺效果會使用 0.05 的 p 值來決定閾值。
如何計算區段?
在幕後,AI 視覺效果會使用 ML.NET 來執行判定樹來尋找有趣的子群組。 決策樹最終目標是取得資料點的子群組,該資料點在您感興趣的計量中相對較高。 這可能是具有低評等的客戶或高價房屋。
決策樹會採用每個說明因素,並嘗試判斷哪些因素會提供最佳「分割」。 例如,如果您篩選資料以僅包括大型企業客戶,則是否會區隔給予高評等和給予低評等的客戶? 也許可以考慮篩選數據,只包含針對安全性提供意見的客戶?
決策樹分割之後,會擷取資料的子群組,並針對該資料判斷下一個最佳分割。 在此案例中,子群組是評論安全性的客戶。 每次分割之後,決策樹也會考慮是否有足夠的資料點,讓此群組夠具代表性可從中推斷模式。 如果沒有,則其為資料中的異常,而不是真正的區段。 另一個統計測試會套用至檢查具有 p 值 0.05 之分割條件的統計重要性。
決策樹完成執行之後,會擷取所有分割 (例如安全性評論和大型企業) 並建立 Power BI 篩選條件。 此篩選條件的組合,會在視覺效果中封裝為區段。
為什麼某些因素會成為影響因素或停止成為影響因素,因為我將更多字段移到 [解釋依據] 中?
視覺效果會將所有說明因素一起評估。 某個因素本身可能是影響因素,但考慮到其他因素時,則可能不是。 假設您想要分析是什麼造成高房價,臥室和房屋大小為說明因素:
- 就其本身而言,較多臥室可能是造成高房價的因素。
- 將房屋大小包含於分析中,表示您現在要探討當房屋大小保持不變時,臥室會如何變化。
- 如果房屋大小固定在 1,500 平方英呎,則不斷增加臥室數目不太可能大幅提高房價。
- 相較於之前考慮房屋大小,臥室可能並非重要因素。
與 Power BI 同事共用報表時,您必須擁有個別網狀架構或 Power BI Pro 授權,或報表儲存在 Premium 容量中。 請參閱 共用報表。