Tip
Power BI Dataflow Gen1 現在處於舊版狀態,不會再投資新功能。 對於具備 Fabric 存取權的高級用戶, Dataflow Gen2 是推薦的路徑,提供效能、規模、可靠性、功能性及內建 AI 的提升。 Pro/PPU 客戶可以繼續使用 Gen1,因為 Gen2 在這類情境下的指引正在演進中。 請參閱從 Dataflow Gen1 升級到 Dataflow Gen2 以獲得升級指引。
設計維度模型是資料流程中最常見的任務之一。 本文將介紹使用資料流程建立維度模型的一些最佳實務。
暫存資料流
任何資料整合系統的關鍵之一,就是減少來自原始作業系統的讀取次數。 在傳統的資料整合架構中,這種減少是透過建立一個稱為 暫存資料庫的新資料庫來完成的。 暫存資料庫的目的是定期將資料從資料來源以原樣載入暫存資料庫。
其餘的資料整合則以暫存資料庫作為進一步轉換的來源,並將其轉換為維度模型結構。
我們建議你採用相同的方法來使用資料流程。 建立一組資料流,負責從來源系統載入資料 as-is(且只載入你需要的資料表)。 結果會被儲存在資料流的儲存結構中(Azure Data Lake Storage 或 Dataverse)。 此變更確保源系統的讀取操作最小化。
接著,你可以建立其他資料流,這些資料會從預備資料流取得來源。 此方法的好處包括:
- 減少源系統的讀取操作次數,進而降低源系統的負擔。
- 若使用本地資料來源,可減輕資料閘道的負擔。
- 為核對準備資料的中間副本,以備來源系統資料變更時使用。
- 讓轉換資料流與來源無關。
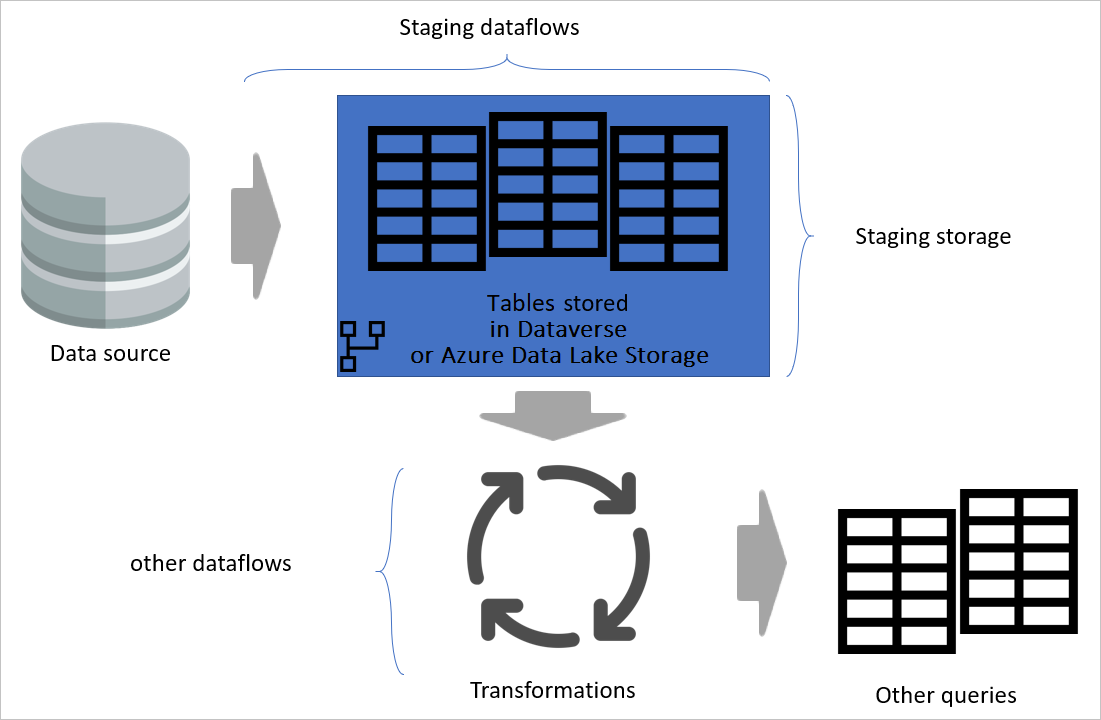
強調暫存資料流與暫存儲存的圖示。 圖示顯示佇列資料流從資料來源存取的資料,以及資料表儲存在 Cadavers 存儲或 Azure 數據湖存儲中。 接著顯示表格與其他資料流一起被轉換,這些資料流會以查詢的形式發送。
轉換資料流
當你將轉換資料流與暫定資料流分離時,轉換過程與來源無關。 這種分離對於將來源系統遷移到新系統會有幫助。 這種情況下你只需要改變暫定資料流即可。 轉換資料流通常不會有問題,因為它們只來自暫存資料流。
這種分離也有助於防止來源系統連線緩慢。 轉換資料流不需要等很久就能收到來自原始系統慢速連線的紀錄。 暫存資料流已經完成這部分,資料也準備好進入轉換層。
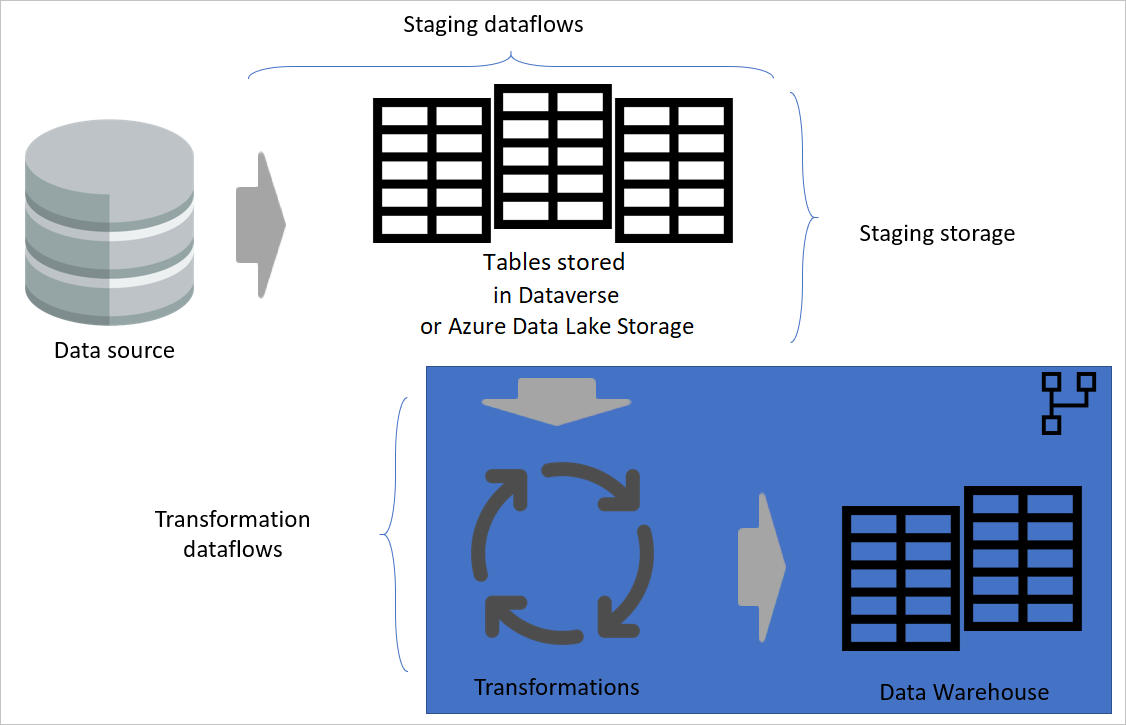
分層架構
分層架構是指在不同層執行動作的架構。 分階段與轉換資料流可以是多層資料流架構中的兩層。 嘗試分層執行動作能確保維護成本最低。 當你想修改某件事時,只需要在所在的圖層中進行修改即可。 其他層應該都能正常運作。
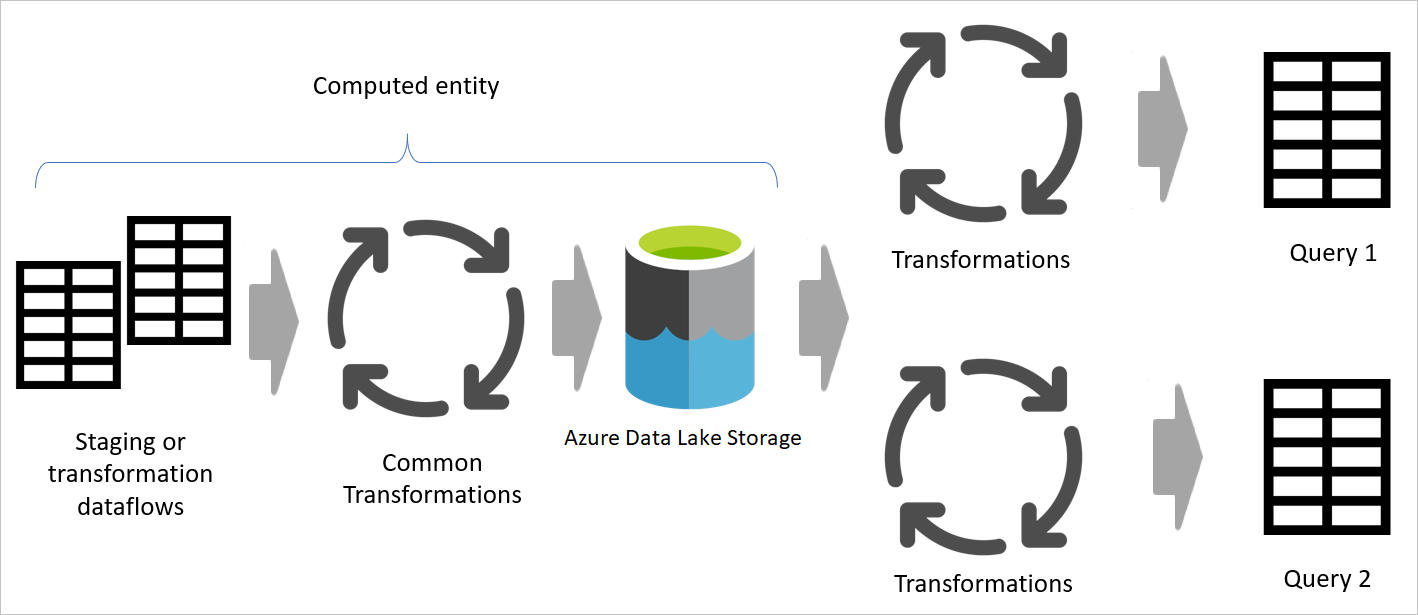
下圖展示了一個多層次的資料流架構,其中資料表會被用於 Power BI 語意模型中。
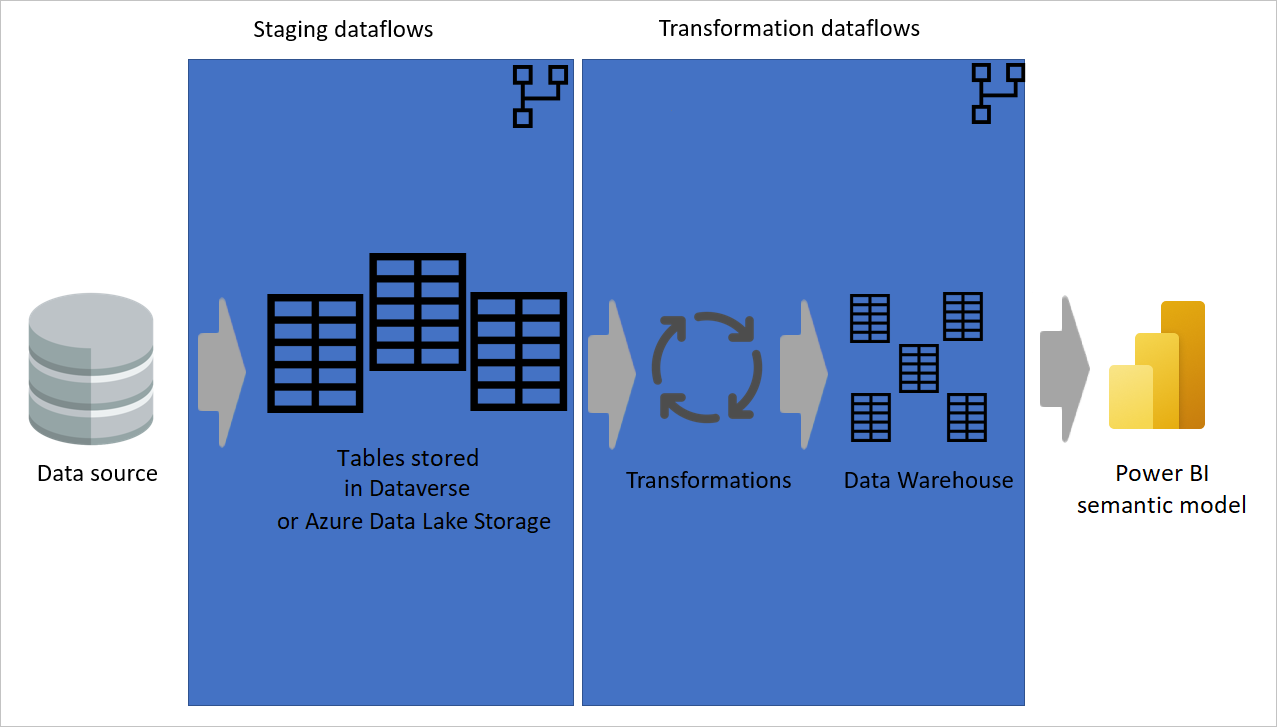
盡可能使用計算出來的表格
當你在另一個資料流中使用一個資料流的結果時,你是在使用計算資料表的概念,也就是從一個「已處理並儲存」的資料表取得資料。 資料流內部也可能發生同樣的情況。 當你從另一個表格參考一個表格時,你可以使用計算出來的表格。 這種方法在需要在多個表格中執行的轉換時非常有用,這些轉換稱為 共用轉換。
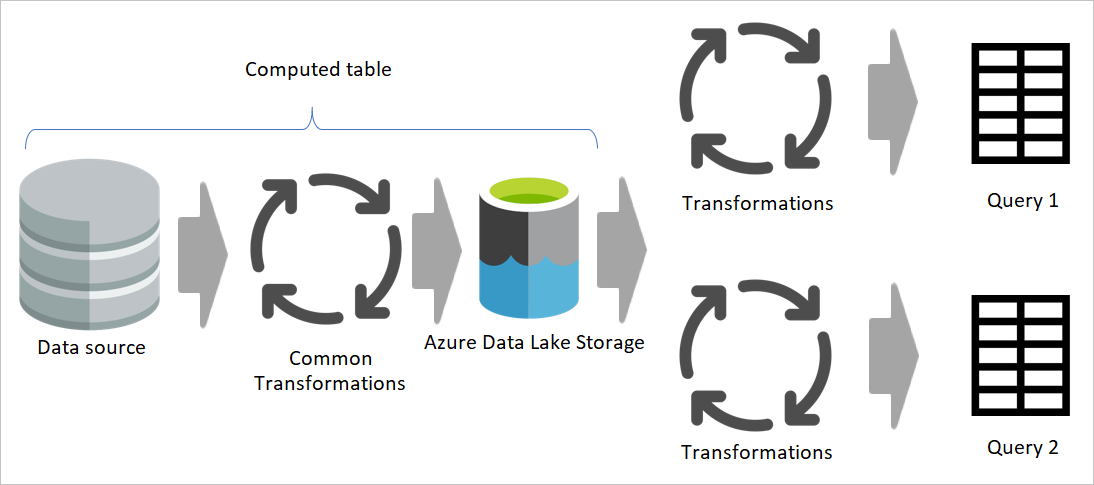
在前一張圖片中,計算出來的資料表直接從來源取得資料。 然而,在暫存與轉換資料流架構中,計算出的資料表很可能是來自暫存資料流。
建立星型結構
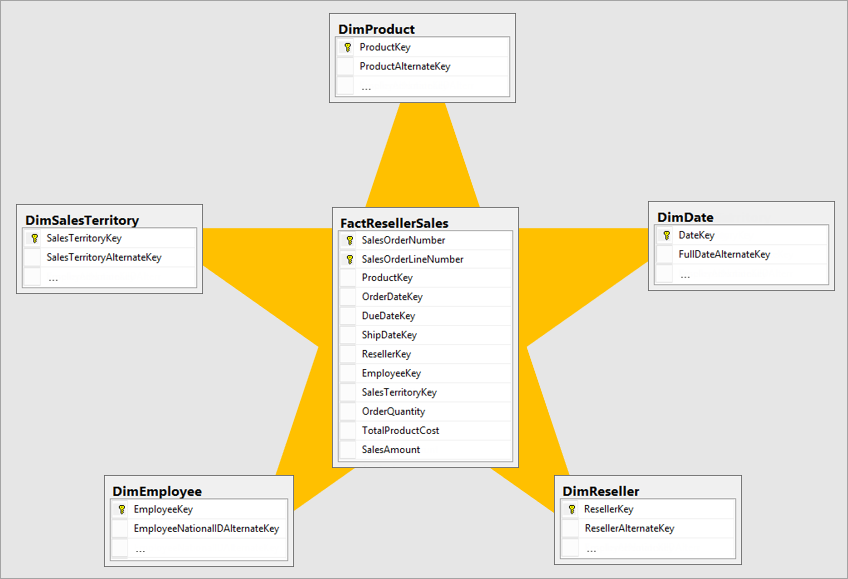
最佳維度模型是星型結構模型,其維度與事實表設計以最小化查詢資料的時間。 星型結構模型也讓資料視覺化工具更容易理解。
將與營運系統相同配置的資料帶入商業智慧系統並不理想。 資料表應該重新設計。 部分表格應呈現維度表的形式,以保留描述性資訊。 有些表格應該以事實表的形式呈現,以保留可彙總的資料。 事實表和維度表形成的最佳版面配置是星型結構。 欲了解更多資訊,請參閱 「了解星型結構及 Power BI 的重要性」。
使用唯一的維度鍵值
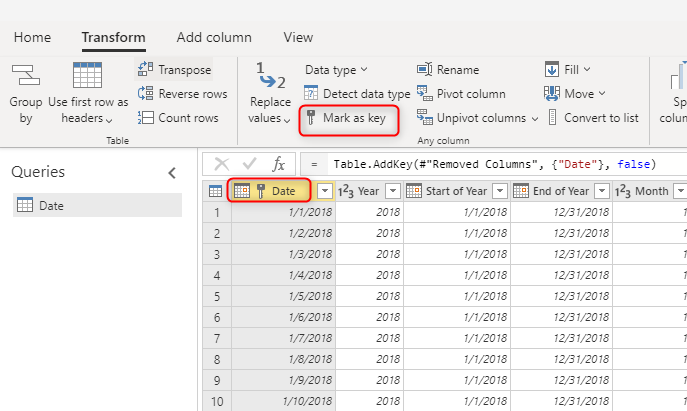
建立尺寸表時,務必為每個尺寸表準備一個鑰匙。 此鍵確保維度間不存在多對多(換句話說,即「弱」)關係。 你可以通過某些轉換來創建此鍵,從而確保在維度中,某一欄或欄的組合能夠返回唯一的列。 然後可以在資料流的表格中標記該欄位組合為鍵。
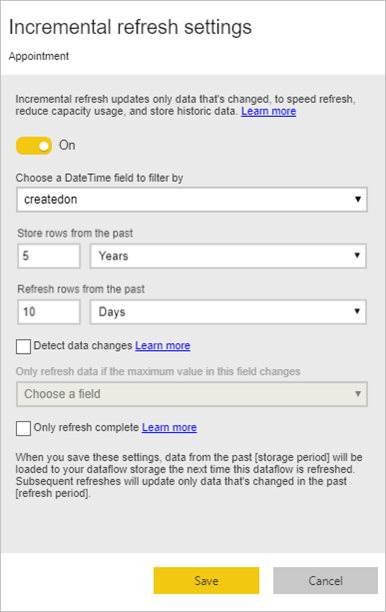
對於大型事實表,請執行增量式重新整理
事實表總是維度模型中最大的表。 我們建議您減少這些表格的傳輸列數。 如果你有一個非常大的事實表,務必使用增量式刷新來處理該表。 增量刷新可以在 Power BI 語意模型中進行,也可以在資料流資料表中進行。
你可以用增量刷新只刷新部分資料,也就是被更改的部分。 有多種選項可選擇要刷新哪部分資料,哪部分要持久保存。 欲了解更多資訊,請參閱 使用 Power BI 資料流的增量刷新。
利用參考資料來建立維度與事實表
在原始碼系統中,你通常會有一個表格,用來在資料倉儲中產生事實表和維度表。 這些資料表是計算資料表及中間資料流的良好候選。 流程中常見的部分——例如資料清理、移除多餘的列和欄——可以只完成一次。 透過從那些動作的輸出中抽取參考資料,你可以建立維度表和事實表。 此方法使用計算出的表格來處理常見的轉換。