在 Power Query 中,你可以根據一個或多個欄位的值將各列的值分組成一個值。 你可以從兩種分組操作中選擇:
欄位分組。
行分組。
在這個教學中,你使用的是以下範例表格。
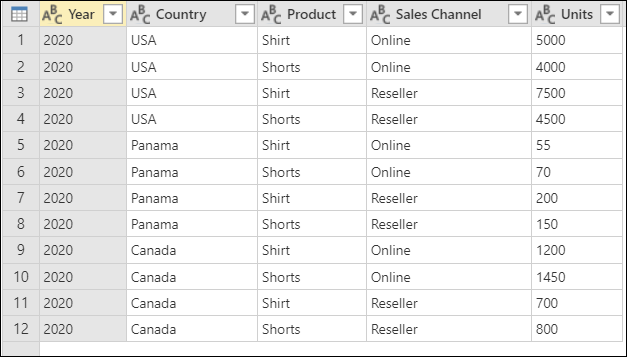
表格截圖,欄位顯示年份(2020年)、國家(美國、巴拿馬或加拿大)、產品(襯衫或短褲)、銷售通路(線上或經銷商)及單位數(從55到7500不等的各種數值)
在哪裡可以找到按按鈕群組
你可以在三個地方找到 Group by 按鈕:
在 Home 標籤的 Transform 群組裡。

在 Transform 頁面的 Table 群組中。
在快捷選單中,當你右鍵點擊選取欄位時,
使用彙總函數將欄位分組為一個或多個欄位
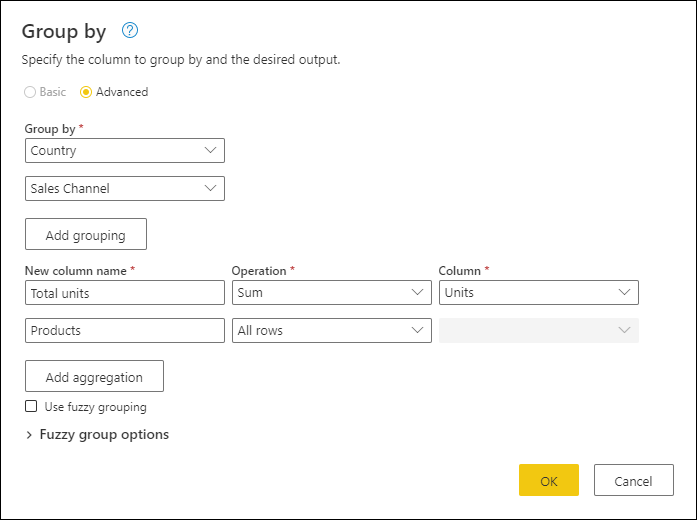
在這個例子中,你的目標是彙總各國及銷售通路層級的總銷售量。 你可以使用 國家 和 銷售渠道 欄位來執行分組操作。
- 在「首頁」分頁選擇「按群組」。
- 選擇 進階 選項,這樣你可以選擇多個欄位來分組。
- 選擇 國家 欄位。
- 選擇 新增分組。
- 選擇 銷售通路 欄位。
- 在 「新欄位名稱」輸入 「總單位數」,在 「操作」中選擇 「總和」,在 「欄位」中選擇 「單位數」。
- 選擇 確定

此操作會給出以下表格。

可用操作
透過 「群組依」 功能,可用的操作可分為兩種分類:
- 行級操作
- 欄位層級操作
下表說明了這些操作的每一項。
| 作業名稱 | 類別 | Description |
|---|---|---|
| 總和 | 欄位操作 | 彙總該欄的所有數值 |
| 平均 | 欄位操作 | 計算欄位的平均值 |
| Median | 欄位操作 | 從一欄計算中位數 |
| Min | 欄位操作 | 計算欄位的最小值 |
| 最大值 | 欄位操作 | 計算欄位的最大值 |
| Percentile | 欄位操作 | 利用輸入值從0到100從欄位計算百分位數 |
| 計算唯一值的數量 | 欄位操作 | 計算欄位中不同值的數量 |
| 計數行數 | 排行操作 | 計算給定群組的總行數 |
| 計算不同行數 | 排行操作 | 計算給定群中不同行數 |
| 所有列 | 排行操作 | 輸出表格中所有分組的行,並且沒有執行聚合操作 |
備註
統計不同值和百分位數這些操作僅在 Power Query Online 中提供。
執行一個操作,將欄位分組為一個或多個欄位
從原始樣本開始,在此範例中,你建立一欄包含總單位,另外兩欄分別列出表現最佳產品的名稱與銷售單位,並依國家及銷售通路彙整。

請使用以下欄位作為 按欄位分組 :
- 國家
- 銷售通路
請依照以下步驟建立兩欄:
- 使用加總操作來彙總單位欄位。 此欄名稱為 「總單位」。
- 透過使用「所有列」操作新增 Products 欄位。

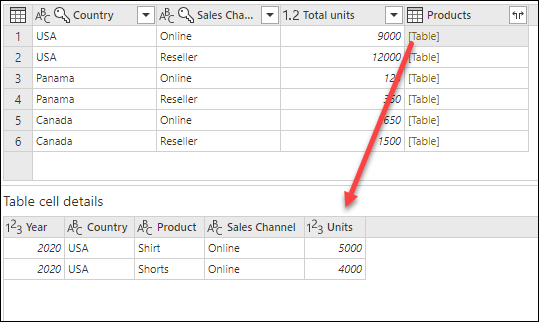
完成操作後,請注意 Products 欄位中每個儲存格內都有 [Table] 值。 每個 [Table] 值包含了從原始表格中被 國家 和 銷售管道 欄位分組的所有資料列。 你可以選擇儲存格內的空白,預覽對話框底部的表格內容。
備註
詳細預覽窗格可能無法顯示所有用於分組操作的列。 你可以選擇 [Table] 值,查看所有與對應分組操作相關的列。
接著,你需要在新產品欄位中擷取 Units 欄位中值最高的那一列,並將該欄位稱為 Top Performer 產品。
擷取表現最佳的產品資訊
使用帶有 [Table] 值的新產品欄位,你可以在功能區的「新增欄位」標籤中,從一般群組中選擇「自訂」欄位來建立新的自訂欄位。
「Power Query」功能區中「新增欄位」標籤的截圖,上面強調了「自訂欄位」選項。
你的新專欄名稱為 「頂尖表現產品」。 在Table.Max([Products], "Units" )中輸入公式。

該公式的結果會產生一個新的欄位,欄位值為 [Record]。 這些記錄值本質上是一個只有一列的表格。 這些記錄包含每個 [Table] 值的 Products 欄位中 Units 欄位最大值的列。

在這個包含[記錄]值的「頂尖表現者產品」欄位中,你可以選擇![]() 展開圖示、選擇產品與單位欄位,然後選擇確定。
展開圖示、選擇產品與單位欄位,然後選擇確定。

移除 產品 欄位並設定兩個新展開欄位的資料型別後,結果會像以下圖片。

模糊分組
備註
以下功能僅在 Power Query Online 中提供。
為了示範如何進行「模糊分組」,請參考下圖所示的範例表格。
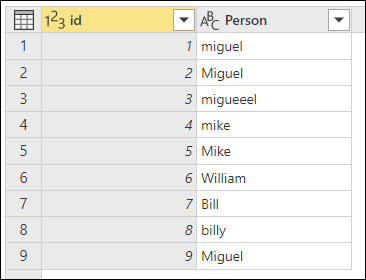
模糊分組的目標是執行一種使用文字字串近似匹配演算法的分組操作。 Power Query 使用 Jaccard 相似度演算法來衡量實例對之間的相似度。 接著,它會應用聚合階層聚類來將實例群組在一起。 下圖顯示您所期望的輸出,表格按人物欄位分組。
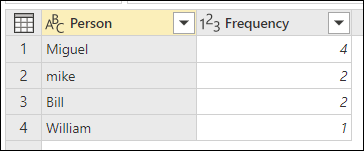
要進行模糊分組,你執行本文先前描述的相同步驟。 唯一的差別是這次在「依群組排序」對話框中,您勾選了「使用模糊分組」選項。

對於每一組資料列,Power Query 會選擇最頻繁的實例作為「典範」實例。 如果有多個實例以相同頻率出現,Power Query 會選擇第一個。 在「按群組」對話框選擇確定後,你會得到預期的結果。
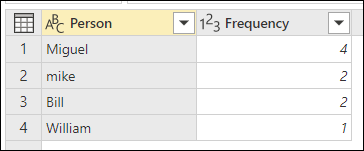
不過,透過擴展 模糊群組選項,你可以更精確地控制模糊群組的操作。

以下選項可用於模糊分組:
- 相似度門檻(可選):此選項表示兩個數值必須多相似才能被歸類。 最小設定為零(0)時,所有值會被歸為一組。 最大設定為 1 時,只能將完全相同的數值分組在一起。 預設值是 0.8。
- 忽略大小寫:當比較文字串時,忽略大小寫。 此選項預設為啟用。
透過組合文字部分分組 :演算法嘗試將文字部分(例如Micro 和soft 合併為Microsoft )來進行分組。- 顯示相似度分數:顯示輸入值與經過模糊分組後計算出的代表性值之間的相似度分數。 需要新增如 「所有列」 這類操作,以逐列層級展示這些資訊。
轉換表(可選) :你可以選擇一個轉換表,將數值(例如將MSFT 映射到 Microsoft )來組合。
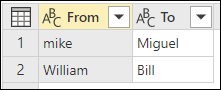
在此範例中,使用轉換表來示範如何映射值。 轉換表有兩欄:
- 從:表格中要尋找的文字字串。
- 收件人:用來替換 「From 」欄位文字字串的文字字串。
下圖展示了此範例中使用的轉換表。
這很重要
重要的是,轉換表的欄位和欄位名稱必須與前一張圖片相同(必須標示為「From」和「To」)。 否則 Power Query 不會將該表格識別為轉換表。
返回「 按群組」 對話框,展開 模糊群組選項,將操作從 「計數列 」改為 「所有」,啟用 「顯示相似度分數」 選項,然後選擇「 轉換表 」下拉選單。

選擇轉換表後,選擇 確定。 該操作的結果會給你以下資訊:
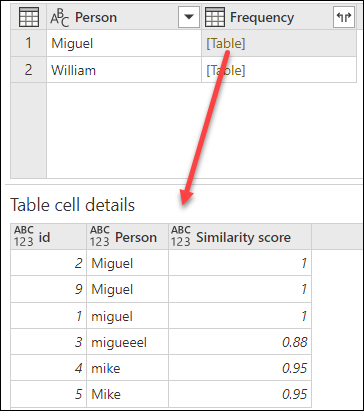
在此範例中,啟用了 忽略大小寫 選項,因此轉換表中 From 欄位的值用來尋找文字字串,而不必考慮字串的實況。 此轉換操作先進行,接著執行模糊分組操作。
相似度分數也會顯示在人物欄位旁的表格值中,精確反映這些值的分組方式及其相似度分數。 如果需要,你可以擴充此欄位,或使用新 頻率 欄位的值來做其他類型的轉換。
備註
當以多欄分組時,若替換值會增加相似度分數,轉換表會在所有欄位執行替換操作。
欲了解更多轉換表的運作方式,請參考「轉換表原則」。