處理文本資料有時可能會感到麻煩。 例如,城市「Redmond」的名稱可能會以不同的大小寫來表示(「Redmond」、「redmond」和「REDMOND」)。 這可能會導致在 Power Query 中轉換數據時發生問題,因為 Power Query M 公式語言區分大小寫。
值得慶幸的是,Power Query M 會提供函式來清除和正規化文字數據大小寫。 有函式可將文字轉換成小寫(abc)、大寫(ABC),或適當大小寫(Abc)。 此外,Power Query M 也提供數種方式來完全忽略大小寫。
本文說明如何變更文字、清單和數據表中的單字大寫。 它還描述了在文字、清單和表格中處理數據時忽略大小寫的各種方法。 此外,本文將討論如何根據案例排序。
變更文字大小寫
有三個函式可將文字轉換成小寫、大寫和適當大小寫。 函式為 Text.Lower、 Text.Upper與 Text.Proper。 下列簡單範例示範如何在文字中使用這些函式。
將文字中的所有字元轉換成小寫
下列範例示範如何將字串中的所有字元轉換成小寫。
let
Source = Text.Lower("The quick brown fox jumps over the lazy dog.")
in
Source
此程式碼會產生下列輸出:
the quick brown fox jumps over the lazy dog.
將文字中的所有字元轉換成大寫
下列範例示範如何將文字字串中的所有字元轉換成大寫。
let
Source = Text.Upper("The quick brown fox jumps over the lazy dog.")
in
Source
此程式碼會產生下列輸出:
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.
將所有單字轉換成初始大寫
下列範例示範如何將句子中的所有單字轉換成初始大寫。
let
Source = Text.Proper("The quick brown fox jumps over the lazy dog.")
in
Source
此程式碼會產生下列輸出:
The Quick Brown Fox Jumps Over The Lazy Dog.
變更清單中的案例
在清單中變更大小寫時,最常使用的函式是 List.Transform。 下列簡單範例示範如何在清單中使用此函式。
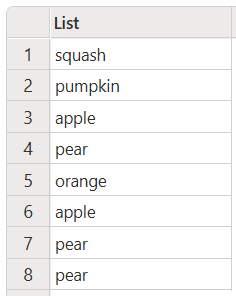
將所有項目轉換成小寫
下列範例示範如何將清單中的所有專案變更為小寫。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
此程式碼會產生下列輸出:
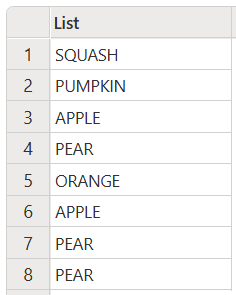
將所有項目轉換成大寫
下列範例示範如何將清單中的所有專案變更為大寫。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Upper Case" = List.Transform(Source, Text.Upper)
in
#"Upper Case"
此程式碼會產生下列輸出:
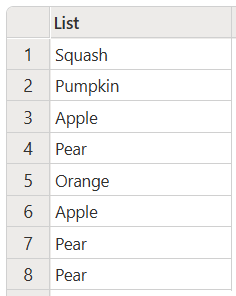
將所有項目轉換成適當的大小寫
以下範例示範如何將清單中的所有項目變更為正確的大小寫。
let
Source = {"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
#"Proper Case" = List.Transform(Source, Text.Proper)
in
#"Proper Case"
此程式碼會產生下列輸出:
變更數據表中的大小寫
在資料表中變更大小寫時,最常使用的函式是 Table.TransformColumns。 您也可以使用 函式來變更資料列中包含的文字大小寫,稱為 Table.TransformRows。 不過,此函式不會經常使用。
下列簡單範例示範如何使用 函 Table.TransformColumns 式來變更數據表中的案例。
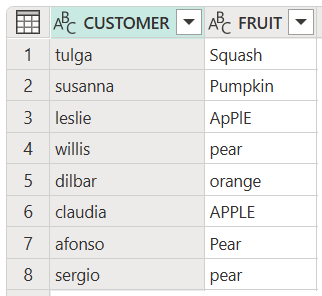
將數據表數據列中的所有項目轉換成小寫
下列範例示範如何將表格欄位中的所有專案變更為小寫,此例中為客戶名稱。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Lower Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Lower})
in
#"Lower Case"
此程式碼會產生下列輸出:
將表格列中的所有項目轉為大寫
下列範例示範如何將表格欄中的所有項目變更為大寫,在此案例中為水果名稱。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Upper Case" = Table.TransformColumns(Source, {"FRUIT", Text.Upper})
in
#"Upper Case"
此程式碼會產生下列輸出:
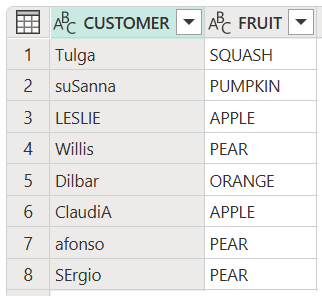
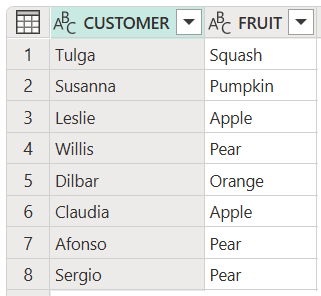
將數據表中的所有項目轉換為適當的大小寫
下列範例示範如何將這兩個表格欄中的所有項目變更為適當的大小寫。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Customer Case" = Table.TransformColumns(Source, {"CUSTOMER", Text.Proper}),
#"Proper Case" = Table.TransformColumns(#"Customer Case", {"FRUIT", Text.Proper})
in
#"Proper Case"
此程式碼會產生下列輸出:
忽略大小寫
在許多情況下,搜尋或取代專案時,您可能需要忽略您要尋找的專案案例。 由於 Power Query M 公式語言對大小寫敏感,因此,若兩個專案內容相同但大小寫不同,這些專案會被判定為不同的,而非相同的。 忽略案例的其中一種方法牽涉到 Comparer.OrdinalIgnoreCase 在包含 equationCriteria 參數或 comparer 參數的函式中使用 函式。 另一個忽略案例的方法牽涉到在 IgnoreCase 包含 options 參數的函式中使用 選項(如果有的話)。
忽略文字中的大小寫
在文字中搜尋有時會要求您忽略大小寫,才能尋找搜尋文字的所有實例。文字函式通常會在 Comparer.OrdinalIgnoreCase 參數中使用 comparer 函式,在測試是否相等時忽略大小寫。
下列範例示範如何在判斷句子是否包含特定單字時忽略大小寫,而不論大小寫為何。
let
Source = Text.Contains(
"The rain in spain falls mainly on the plain.",
"Spain",
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
true
下列範例示範如何取得句子中最後一次出現的「the」字的初始位置,不論大小寫。
let
Source = Text.PositionOf(
"THE RAIN IN SPAIN FALLS MAINLY ON THE PLAIN.",
"the",
Occurrence.Last,
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
34
忽略清單中的大小寫
任何包含可選 equationCriteria 參數的清單函數都可以使用 Comparer.OrdinalIgnoreCase 函數來忽略清單中的大小寫。
下列範例會檢查清單是否包含特定項目,同時忽略大小寫。 在此範例中,List.Contains 僅能比較清單中的一個項目,您無法比較一個清單與另一個清單。 為此,您必須使用 List.ContainsAny。
let
Source = List.Contains(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
"apple",
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
true
下列範例會檢查清單是否包含第二個參數中所有指定的項目,並且忽略大小寫。 如果清單中缺少任何一項,例如在第二個範例中的 cucumber,函式會傳回 FALSE。
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin"},
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
true
let
Source = List.ContainsAll(
{"Squash", "Pumpkin", "ApPlE", "pear", "orange", "APPLE", "Pear", "pear"},
{"apple", "pear", "squash", "pumpkin", "cucumber"},
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
false
下列範例會檢查清單中的任何項目是否為蘋果或梨子,同時忽略大小寫。
let
Source = List.ContainsAny(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
{"apple","pear"},
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
true
下列範例只會保留不重複的項目,同時忽略大小寫。
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
)
in
Source
此程式碼會產生下列輸出:
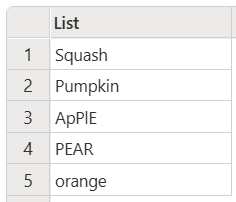
在上一個範例中,輸出會顯示清單中找到的第一個獨特項目的情況。 因此,雖然有兩個蘋果(ApPlE 和 APPLE),但只會顯示找到的第一個範例。
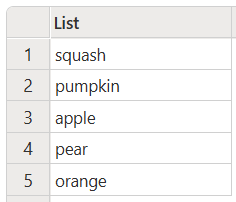
下列範例只會保留唯一的項目,在比較時忽略大小寫,但也會返回所有小寫結果。
let
Source = List.Distinct(
{"Squash", "Pumpkin", "ApPlE", "PEAR", "orange", "APPLE", "Pear", "peaR"},
Comparer.OrdinalIgnoreCase
),
#"Lower Case" = List.Transform(Source, Text.Lower)
in
#"Lower Case"
此程式碼會產生下列輸出:
忽略數據表中的大小寫
數據表有數種方式可以忽略大小寫。 數據表函式,例如 Table.Contains、 Table.Distinct和 Table.PositionOf 所有 包含 equationCriteria 參數。 這些參數可以使用 Comparer.OrdinalIgnoreCase 函式來忽略資料表中的大小寫,就像前一節中的清單一樣。 數據表函式,例如包含 condition 參數的 Table.MatchesAnyRows,也可以使用 Comparer.OrdinalIgnoreCase 並將其包裹在其他數據表函式中來忽略字母大小寫。 其他數據表函式,特別是模糊比對,可以使用 IgnoreCase 選項。
下列範例示範如何選取包含「pear」一詞的特定行,同時忽略大小寫。 這個範例會使用 condition 的 參數Table.SelectRowsText.Contains做為條件,在忽略大小寫時進行比較。
let
Source = #table(type table[CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "pear"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "pear"}
}),
#"Select Rows" = Table.SelectRows(
Source, each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
此程式碼會產生下列輸出:

下列範例示範如何判斷資料表中是否有任何資料列包含 pear 資料列中的 FRUIT 。 這個範例在 Text.Contains 函數中使用Comparer.OrdinalIgnoreCase,並在Table.MatchesAnyRows 函數中使用condition 參數。
let
Source = #table(type table [CUSTOMER = text, FRUIT = text],
{
{"Tulga", "Squash"},
{"suSanna", "Pumpkin"},
{"LESLIE", "ApPlE"},
{"Willis", "PEAR"},
{"Dilbar", "orange"},
{"ClaudiA", "APPLE"},
{"afonso", "Pear"},
{"SErgio", "peAR"}
}),
#"Select Rows" = Table.MatchesAnyRows(Source,
each Text.Contains([FRUIT], "pear", Comparer.OrdinalIgnoreCase))
in
#"Select Rows"
此程式碼會產生下列輸出:
true
以下範例示範如何處理使用者輸入並包含他們最愛水果的欄位,但沒有任何特定格式的表格。 此數據行會先模糊比對,以擷取其最愛水果的名稱,然後顯示在它自己的數據行中,名為 Cluster。 接著會檢查 叢集 欄位,以判斷欄位中不同的水果。 一旦決定唯一的水果,最後一個步驟就是將所有水果名稱變更為小寫。
let
// Load a table of user's favorite fruits into Source
Source = #table(type table [Fruit = text], {{"blueberries"},
{"Blue berries are simply the best"}, {"strawberries"}, {"Strawberries = <3"},
{"Apples"}, {"'sples"}, {"4ppl3s"}, {"Bananas"}, {"fav fruit is bananas"},
{"Banas"}, {"My favorite fruit, by far, is Apples. I simply love them!"}}
),
// Create a Cluster column and fuzzy match the fruits into that column
#"Cluster fuzzy match" = Table.AddFuzzyClusterColumn(
Source, "Fruit", "Cluster",
[IgnoreCase = true, IgnoreSpace = true, Threshold = 0.5]
),
// Find the distinct fruits from the Cluster column
#"Ignore cluster case" = Table.Distinct(
Table.SelectColumns(#"Cluster fuzzy match", "Cluster"),
Comparer.OrdinalIgnoreCase
),
// Set all of the distinct fruit names to lower case
#"Set lower case" = Table.TransformColumns(#"Ignore cluster case",
{"Cluster", Text.Lower}
)
in
#"Set lower case"
此程式碼會產生下列輸出:
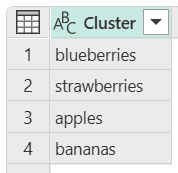
大小寫和排序
清單和數據表都可以分別使用 List.Sort 或 Table.Sort來排序。 不過,文字排序依據列表或表格中項目的大小寫,以判斷實際排序順序(遞增或遞減)。
最常見的排序方式是使用全部小寫、全部大寫或正確大小寫的文字。 如果有這些案例的混合,遞增排序順序如下所示:
- 以大寫字母開頭的清單或數據表數據行中的任何文字都是第一個。
- 如果有相符的文字,但一個是正常大小寫,另一個是全大寫,全大寫版本應列在最前面。
- 然後排序小寫。
針對遞減順序,先前列出的步驟會反向處理。
例如,下列範例包含所有小寫、所有大寫和適當大小寫文字的混合,以遞增順序排序。
let
Source = { "Alpha", "Beta", "Zulu", "ALPHA", "gamma", "alpha",
"beta", "Gamma", "Sierra", "zulu", "GAMMA", "ZULU" },
SortedList = List.Sort(Source, Order.Ascending)
in
SortedList
此程式碼會產生下列輸出:
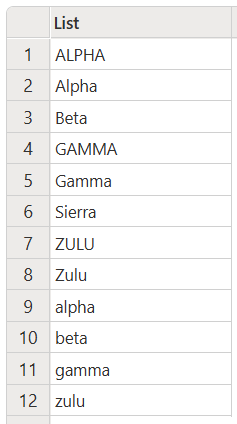
雖然不常見,但您可能會在文字中混用大寫字母和小寫字母來排序。 在此情況下,遞增排序順序為:
- 以大寫字母開頭的清單或數據表數據行中的任何文字都是第一個。
- 如果有相符的文字,則接下來會處理左側具有最多大寫字母的文字。
- 接著將小寫字母進行排序,同時優先把最多的大寫字母排列到右側。
在任何情況下,在排序之前,將文字轉換成一致的大小寫可能會比較方便。
Power BI Desktop 正規化
Power Query M 區分大小寫,對相同文字的不同大小寫加以區別。 例如,會將 「Foo」、“foo” 和 “FOO” 視為不同。 不過,將數據載入 Power BI Desktop 時,文字值會正規化,這表示不論其大小寫為何,Power BI Desktop 都會將它們視為相同的值。 因此,如果您需要在維護數據中區分大小寫時轉換數據,您應該先在 Power Query 中處理資料轉換,再將數據載入 Power BI Desktop。
例如,Power Query 中的下表顯示數據表中每個數據列的不同案例。
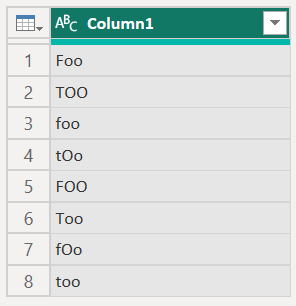
當此數據表載入 Power BI Desktop 時,文字值會變成正規化,導致下表。
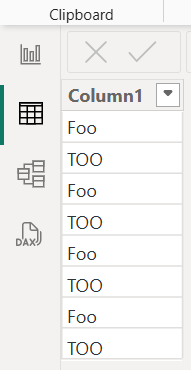
在 Power BI Desktop 資料表中,“foo” 的第一個實例和 “too” 的第一個實例會決定其餘資料列中 “foo” 和 “too” 的大小寫。 在此範例中,“foo” 的所有實例都會正規化為 “Foo” 值,而 “too” 的所有實例都會正規化為 “TOO”。