多個 GPU 和電腦
1.簡介
CNTK 目前支援四種平行的 SGD 演算法:
必要條件
若要執行平行定型,請確定已安裝訊息傳遞介面 (MPI) 實作:
在 Windows 上安裝版本 7 (7.0.12437.6) 的 Microsoft MPI (MS-MPI) ,這是來自 此下載頁面的訊息傳遞介面標準的 Microsoft 實作,只會在頁面標題中標示為「版本 7」。 按一下 [下載] 按鈕,然後選取執行時間 (
MSMpiSetup.exe) 。在 Linux 上,安裝 OpenMPI 1.10.x 版。 請依照 這裡的 指示自行建置。
2.在 Python 中設定 CNTK 中的平行定型
若要在 Python 中使用資料平行的 SGD,使用者必須建立分散式學習模組,並將分散式學習模組傳遞給定型人員:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
針對使用者定義定型迴圈 (,而不是training_session) ,使用者必須傳入 num_data_partitions 和 partition_index 至 MinibatchSource.next_minibatch() 方法,讓不同的 MPI 節點在讀取) 範例之後 distributed_after ,從不同的資料分割讀取資料 (。
請注意, Communicator.finalize() 只有在分散式定型成功完成時,才應該呼叫 。 如果分散式背景工作角色失敗,則不應該呼叫這個方法。
如需功能完整的範例,請參閱 ConvNet 範例。
3.在 BrainScript 中設定 CNTK 的平行訓練
若要在 CNTK BrainScript 中啟用平行訓練,您必須先在組態檔或命令列中開啟下列參數:
parallelTrain = true
其次, SGD 組態檔中的 區塊應該包含名為 ParallelTrain 且具有下列引數的子區塊:
parallelizationMethod: () 合法值為DataParallelSGD、BlockMomentumSGD和ModelAveragingSGD。這會指定要使用的平行演算法。
distributedMBReading: (選擇性) 接受布林值: 或false;true預設值為false建議開啟分散式迷你批次讀取,以將每個背景工作角色中的 I/O 成本降到最低。 如果您使用 CNTK 文字格式讀取器、影像讀取器或 複合資料讀取器,則 distributedMBReading 應該設定為 true。
parallelizationStartEpoch: (選擇性) 接受整數值;預設值為 1。這會指定從使用 Epoch、平行定型演算法開始;之前,所有背景工作都執行相同的訓練,但只允許一個背景工作角色儲存模型。 如果平行定型需要一些「暖開始」階段,此選項會很有用。
syncPerfStats: (選擇性) 接受整數值;預設值為 0。這會指定效能統計資料的列印頻率。這些統計資料包括同步處理期間內通訊和/或計算所花費的時間,這對於瞭解平行定型演算法的瓶頸很有用。
0 表示不會印出任何統計資料。其他值會指定將列印統計資料的頻率。例如,
syncPerfStats=5表示統計資料會在每 5 次同步處理之後列印出來。子區塊,指定每個平行定型演算法的詳細資料。 子區塊的名稱應該等於
parallelizationMethod。 (強制)
Python 針對不同的平行處理方法,提供更大的彈性和用法如下所示。
4.使用 CNTK 執行平行訓練
CNTK 中的平行處理是使用 MPI 實作。
4.1 使用 BrainScript 執行平行訓練
假設上述任何平行訓練 BrainScript 組態,可以使用下列命令來啟動平行 MPI 作業:
使用 Linux 在同一部電腦上平行定型:
mpiexec --npernode $num_workers $cntk configFile=$config使用 Windows 在同一部電腦上平行定型:
mpiexec -n %num_workers% %cntk% configFile=%config%使用 Linux 跨多個運算節點進行平行定型:
步驟 1:使用您慣用的編輯器建立主機檔案$hostfile
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
其中 name_of_node (n) 只是背景工作節點的 DNS 名稱或 IP 位址。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
使用 Windows 跨多個運算節點進行平行定型:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
其中 $cntk 應該參考 CNTK 可執行檔的路徑 ($x 是 Linux 殼層替代環境變數的方式, %x% 相當於 Windows 殼層中的) 。
4.2 使用 Python 執行平行訓練
如需使用 Python 的 CNTK v2 分散式定型範例,請參閱:
假設有 CNTK v2 Python 腳本 training.py ,您可以使用下列命令來啟動平行 MPI 作業:
使用 Linux 在同一部電腦上平行定型:
mpiexec --npernode $num_workers python training.py使用 Windows 在同一部電腦上平行定型:
mpiexec -n %num_workers% python training.py使用 Linux 跨多個運算節點進行平行定型:
步驟 1:使用您慣用的編輯器建立主機檔案$hostfile
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
其中 name_of_node (n) 只是背景工作節點的 DNS 名稱或 IP 位址。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
使用 Windows 跨多個運算節點進行平行定型:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel使用 1 位的 SGD 訓練
CNTK 實作 1 位的 SGD 技術 [1]。 這項技術允許將每個迷你批次散發給 K 背景工作角色。 產生的部分漸層接著會在每個迷你批次之後交換和匯總。 「1 位」是指 Microsoft 開發的一項技術,用來將每個漸層值交換的資料量減少為單一位。
5.1 「1 位的 SGD」 演算法
在每個迷你批次之後直接交換部分漸層需要禁止的通訊頻寬。 若要解決此問題,1 位的 SGD 會積極量化每個漸層值...表示每個值的單一位 (!) 。 實際上,這表示會裁剪大型漸層值,而小型值則會人工擴大。 令人驚奇的是,這不會在使用 技巧 時傷害聚合。
訣竅是,針對每個迷你批次,演算法會比較背景工作角色) 與原始漸層值之間交換的量化漸層 (, (應該交換) 。 計算並記住兩 (量化錯誤) 之間的差異。 此殘差接著會新增至 下一個 迷你批次。
因此,儘管積極量化,但最終會以完整精確度交換每個漸層值;只是延遲。 實驗顯示,只要此模型與暖開始結合, (在小型定型資料子集上定型的種子模型,而不需要平行化) ,這項技術就表示這項技術會導致精確度降低或非常小,同時讓速度不遠于線性 (GPU 在計算太小的子批次時變得效率不佳) 。
為了達到最大效率,技術應該與 自動迷你批次縮放結合,此時,定型器會嘗試增加迷你批次大小。 根據即將推出的資料小子集進行評估,定型器會選取不會傷害聚合的最大迷你批次大小。 在這裡,CNTK 會以迷你批次大小無從驗證的方式指定學習速率和動向超參數。
5.2 在 BrainScript 中使用 1 位的 SGD
1 位的 SGD 本身沒有啟用它以外的參數,之後應該啟動 Epoch。 此外,應該啟用自動迷你批次調整。 這些設定方式是將下列參數新增至 SGD 區塊:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
請注意,Data-Parallel SGD 也可以使用,而不需 1 位量化。 不過,在一般案例中,特別是每個模型參數只套用一次的案例,就像用於轉送 DNN 一樣,這不會因為高通訊頻寬需求而有效率。
下面第 2.2.3 節顯示語音工作上 1 位的 SGD 結果,與下一個描述的 Block-Momentum SGD 方法進行比較。 這兩種方法在接近線性的速度上沒有或幾乎不會遺失精確度。
5.3 在 Python 中使用 1 位的 SGD
若要在 Python 中使用資料平行的 SGD,選擇性地搭配 1 位的 SGD,使用者必須建立分散式學習模組,並將分散式學習模組傳遞給定型人員:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
在建立distributed_learner期間將num_quantization_bits變更為 32,會使用非量化Data-Parallel SGD。 在此情況下,不需要暖開機。
6 Block-Momentum SGD
Block-Momentum SGD 是「區塊模型更新和篩選」的實作,或 BMUF、演算法、簡短 的 Block Momentum [2]。
6.1 Block-Momentum SGD 演算法
下圖摘要說明Block-Momentum演算法中的程式。

6.2 在 BrainScript 中設定 Block-Momentum SGD
若要使用 Block-Momentum SGD,必須使用下列選項,在 區塊中 SGD 具有名為 BlockMomentumSGD 的子區塊:
syncPeriod. 這類似于syncPeriod中的ModelAveragingSGD,它會指定執行模型同步處理的頻率。 的BlockMomentumSGD預設值為 120,000。resetSGDMomentum. 這表示在每次同步處理點之後,本機 SGD 中使用的平滑漸層將會設定為 0。 此變數的預設值為 true。useNesterovMomentum. 這表示 Nesterov 樣式的動態更新會套用在區塊層級上。 如需詳細資訊,請參閱 [2]。 此變數的預設值為 true。
區塊動向和區塊學習率通常會根據所使用的背景工作角色數目自動設定,亦即
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
我們的體驗指出,這些設定通常會產生類似標準 SGD 演算法的聚合,最多 64 個 GPU,這是我們執行的最大實驗。 您也可以使用下列選項手動指定這些參數:
blockMomentumAsTimeConstant指定區塊層級模型更新中低傳遞篩選的時間常數。 其計算方式如下:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRate指定區塊學習速率。
以下是Block-Momentum SGD 組態區段的範例:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 在 BrainScript 中使用 Block-Momentum SGD
1.重新調整學習參數
若要達到每個背景工作角色的類似輸送量,您必須增加與背景工作角色數目成正比的迷你樣本數目。 您可以藉由調整
minibatchSize或nbruttsineachrecurrentiter來達成此目的,視是否使用框架模式隨機化而定。與 Model-Averaging SGD 不同,不需要調整學習率 (,請參閱以下) 。
建議搭配暖啟動的模型使用 Block-Momentum SGD。 在我們的語音辨識工作中,從 24 小時 (8.600 萬個樣本定型的種子模型開始,) 到 120 小時, (43.2 百萬個樣本,) 使用標準 SGD 的資料,即可達成合理的聚合。
2. ASR 實驗
我們使用 Block-Momentum SGD 和 Data-Parallel (1 位的) SGD 演算法,在 2600 小時語音辨識工作上定型 DNN 和 LSTM,以及比較字辨識協助工具與加速因素。 下表和圖表顯示結果 (*) 。
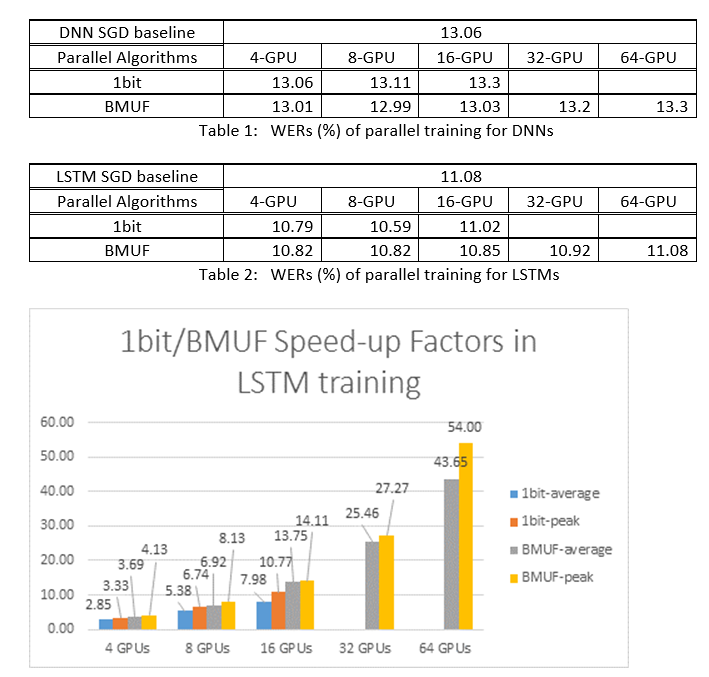
(*) :尖峰加速因數:針對 1 位的 (,相較于在一個迷你batch 中達到的 SGD 基準) ,測量最大速度因素 (;針對 Block Momentum,以一個區塊中達到的最大速度來測量;平均加速因數:在 SGD 基準中耗用的時間除以觀察到的經過時間。 這兩個計量因為 I/O 中的延遲而引進,可能會大幅影響平均加速因數測量,特別是當同步處理是在迷你批次層級執行時。 同時,最大加速因數相對強固。
3. 注意事項
建議將 設定
resetSGDMomentum為 true,否則通常會導致定型準則的差異。 在每個模型同步處理之後,將 SGD 的動力重設為 0,基本上會減少最後一個迷你廣告的貢獻。 因此,建議不要使用大型的 SGD 動向。 例如,針對 120,000 的syncPeriod,如果用於 SGD 的動力為 0.99,我們就會觀察到顯著的精確度損失。 將 SGD 的動力減少為 0.9、0.5 或甚至完全停用它,可提供類似的協助工具,因為標準 SGD 演算法可以達成。Block-Momentum SGD 延遲,並將模型更新從一個區塊分散到後續區塊。 因此,您必須確定模型同步處理通常會在定型中執行足夠的作業。 快速檢查是使用
blockMomentumAsTimeConstant。 建議滿足下列方程式的唯一定型範例N數目:N > = blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
近似值源自下列事實: (1) Block Momentum 通常會設定為 (1-1/num_of_workers) ; (2) log(1-1/num_of_workers)~=-num_of_workers 。
6.4 在 Python 中使用 Block-Momentum
若要在 Python 中啟用Block-Momentum,類似于 1 位的 SGD,使用者必須建立並傳遞一個區塊的訊號分散式學習者給訓練人員:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
如需功能完整的範例,請參閱 ConvNet 範例。
7 Model-Averaging SGD
模型平均 SGD 是 [3,4] 中詳述的模型平均演算法實作,而不需使用自然漸層。 這裡的概念是讓每個背景工作角色處理一部分資料,但平均化每個背景工作角色在指定的期間之後的模型參數。
相較于 1 位的 SGD 和 Block-Momentum SGD,Model-Averaging SGD 通常較慢且較差,因此不再建議使用。
若要使用 Model-Averaging SGD,必須在 區塊中 SGD 具有下列選項的 ModelAveragingSGD 子區塊:
syncPeriod會指定執行模型平均之前,每個背景工作角色必須處理的樣本數目。 預設值為 40,000。
7.1 在 BrainScript 中使用 Model-Averaging SGD
若要讓Model-Averaging SGD 發揮最大效率且有效率,使用者必須微調一些超參數:
minibatchSize或nbruttsineachrecurrentiter。 假設n背景工作角色參與Model-Averaging SGD 設定,目前的分散式讀取實作會將迷你批次的第一個載入1/n每個背景工作角色。 因此,若要確定每個背景工作角色會產生與標準 SGD 相同的輸送量,就必須放大迷你批次大小n-折迭。 對於使用框架模式隨機化定型的模型,這可以藉由放大minibatchSizen次數來達成;對於使用序列模式隨機化來定型的模型,例如 RNN,某些讀取器需要改為增加nbruttsineachrecurrentitern。learningRatesPerSample. 我們的體驗指出,若要取得與標準 SGD 類似的聚合,必須增加learningRatesPerSamplen次數。 您可以在 [2] 中找到說明。 由於學習率增加,因此需要特別小心,以確保定型不會分位,事實上這是Model-Averaging SGD 的主要注意事項。 如果觀察到定型準則增加,您可以使用AutoAdjust設定來重載上一個最佳模型。暖開始。 發現如果從標準 SGD 演算法定型的種子模型開始,Model-Averaging SGD 通常會比較好, (不需要平行處理) 。 在我們的語音辨識工作中,從 24 小時 (8.600 萬個樣本定型的種子模型開始,) 到 120 小時, (43.2 百萬個樣本,) 使用標準 SGD 的資料,即可達成合理的聚合。
以下是組態區段的 ModelAveragingSGD 範例:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 在 Python 中使用 Model-Averaging SGD
這是正在處理的工作。
8 Data-Parallel使用參數伺服器定型
參數伺服器是分散式機器學習 [5][6][7] 中廣泛使用的架構。 它帶來的最重要優點是,具有許多背景工作角色的非同步平行訓練。 它會將參數伺服器引進為分散式模型存放區。 參數伺服器架構不會直接利用 AllReduce 基本類型來同步處理背景工作角色之間的參數更新,而是提供使用者介面,例如 「Add」 和 「Get」,讓本機背景工作角色從參數伺服器更新和擷取全域參數。 如此一來,當地工作者不需要在訓練程式期間等候彼此,這可節省大量時間,特別是當背景工作數目很大時。
此外,由於參數伺服器是儲存模型參數的分散式架構,背景工作角色只能擷取在迷你批次定型程式期間所需的這些參數,這在設計分散式定型方法時具有非常良好的彈性,也可在使用疏鬆模型更新進行定型時提升效率。 在此版本中,我們會先將焦點放在非同步平行定型,稍後我們將進一步介紹如何使用疏鬆更新利用參數伺服器架構進行有效率的模型定型。
8.1 使用 Data-Parallel ASGD
- 若要使用非同步 SGD (縮寫的參數伺服器。ASGD) ,您應該使用 Multiverso 支援 Multiverso 建置 CNTK,Multiverso 是 Microsoft Research Asia 小組所開發分散式機器學習工作的一般參數伺服器架構。
Clone Code:請使用下列方法,複製 CNTK 根資料夾底下的程式碼:
git submodule update --init Source/Multiverso
Linux:請在設定程式中使用--asgd=yes建置 。Windows:請將 新增CNTK_ENABLE_ASGD至您的系統內容,並將值設定為true
- 暖開始。 在某些情況下,最好是讓非同步模型定型從種子模型開始, (由標準 SGD 演算法) 定型。 在某些情況下,非同步 SGD 會因為背景工作角色之間的延遲更新而對定型帶來更多雜訊。 某些模型在一開始就對這類雜訊非常敏感,這可能會導致模型定型的差異。 在這種情況下,需要 暖開始 。
8.2 在 BrainScript 中設定Data-Parallel ASGD
若要在 CNTK 中使用 Data-Parallel ASGD,您必須在 SGD 區塊中使用子區塊 DataParallelASGD,並具有下列選項
-
syncPeriodPerWorkers. 它會指定每個背景工作角色在與參數伺服器通訊之前必須處理的樣本數目。 預設值為 256。 建議使用 minibatch 大小。 很明顯地,頻繁的同步處理會導致大量的通訊成本。 在我們的測試中,在大部分情況下,不需要將值設定為 1。
-
usePipeline. 它會指定是否開啟模型擷取和本機計算的管線。 開啟管線會大幅增加訓練的整體輸送量,因為它會隱藏部分或所有通訊成本。 不過,有時候它可能會讓交集速率變慢,因為新增管線會導入更多延遲。 整體來說,大部分情況下都會使用管線來儲存時鐘時間。
-
AdjustLearningRateAtBeginning. 根據最近發佈的檔 [5],定型 ASGD 較不穩定,而且需要使用較小的學習速率來避免定型遺失偶爾發生暴增,因此學習程式會變得較不有效率。 不過,我們發現並非所有工作都需要使用較低的學習率。 此外,對於一開始敏感的工作,我們會以小型學習率開始定型,並在定型程式的開始階段逐漸放大,直到達到一般 SGD 中使用的初始學習速率為止。 如此一來,最終精確度將會比對 SGD,同時速度為 ASGD。 因此,我們會為 ASGD 使用者提供此選項,以利用此技巧。 它是 DataParallelASGD 中具有兩個參數的子區塊: adjustCoefficient 和 adjustNBMiniBatch。 邏輯是學習速率是從調整 SGD 初始學習率的 adjustCoefficient開始,並透過每個adjustNBMiniBatch迷你批次的ADJUSTCoefficient來增加 SGD 初始學習率。
以下是組態區段的 DataParallelASGD 範例:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 在 Python 中設定Data-Parallel ASGD
這是正在處理的工作。
8.4 實驗
下圖顯示使用 CIFAR-10 資料集測試 ASGD 的實驗。 此實驗中使用的模型是 20 層 ResNet。 非同步演算法可降低等候所有背景工作節點的成本。 在此情況下,ASGD 明顯比同步演算法快,例如 MA 和 SSGD。 *在實驗中,所有平行模式都會 (迷你批次更新) 同步處理每個反復專案的參數。 針對 SSGD,我們使用 32 位參數更新。 非同步演算法在範例處理速度測量的定型輸送量方面獲得顯著優勢,特別是當工作節點數目高達 16 時。
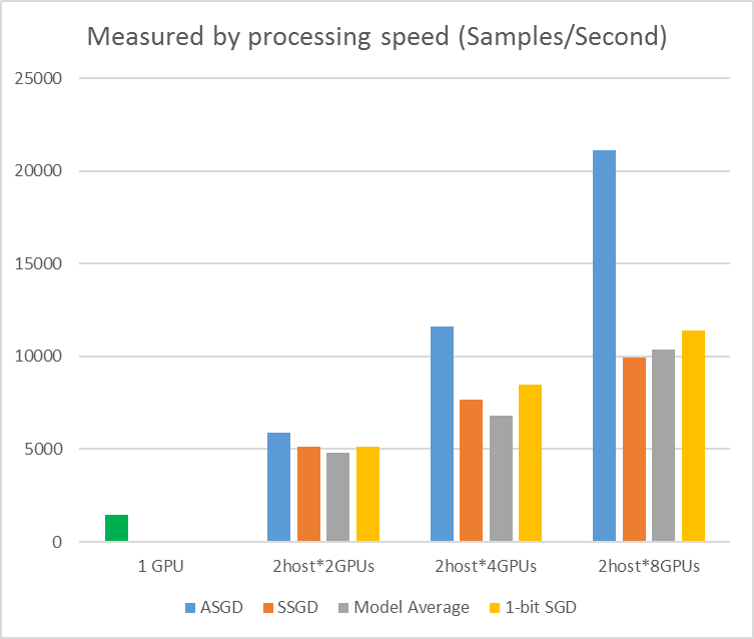 圖 2.4 不同定型方法的速度
圖 2.4 不同定型方法的速度
參考資料
[1] F. Seide, 一開始,, Jasha Droppo, 一行 Li, 和 Yu, 「1 位隨機漸層下降及其應用程式到資料平行分散式的語音 DNN 定型」,在 2014 年 Interspeech 的繼續中。
[2] K. Chen and Q. Huo, "Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering," in Proceedings of ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li, and A. J. Smola, 「Parallelized stochastic gradient descent」,in Proceedings of Advances in NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. 在 2014 年學習標記法上的國際會議中,「平行訓練具有自然漸層和參數平均的 DNN」。
[5]Chen J、Monga R、Bengio S 等,重新流覽 Distributed Synchronous SGD。 ICLR, 2016。
[6]Dean Jeffrey、Greg Corrado、Rajat Monga、KaiChen、Matthieu Devin、Mark 一線、Andrew 資深等人。大規模分散式深層網路。 在神經資訊處理系統的進階中,pp. 1223-1231。 2012.
[7]Li Mu、Li Xia、Zic yang、Aaron Li、Fei Xia、David G.Andersen 和一個 Smola。 「分散式機器學習的參數伺服器」。在 Big Learning NIPS Workshop 中,第 6,p. 2。 2013.