注意
Microsoft 於 2025 年 8 月 31 日退休所有經典的電子發現體驗。 此退休包含經典內容搜尋、經典電子發現 (Standard) ,以及經典電子發現 (高級) 。
本文的指引僅適用於中國) 由世紀互聯提供的 Microsoft 365 (主辦的組織。 如果您的組織尚未由 21Vianet 託管,請參考 Microsoft Purview 入口網站中新電子發現體驗的指引。
在 eDiscovery (Premium) 中運用預測編碼機器學習能力的第一步,就是建立一個預測編碼模型。 建立模型後,你可以訓練它,辨識評論集中的相關與非相關內容。
欲檢視預測編碼工作流程,請參閱 「了解電子發現中的預測編碼」 (高級)
在你建立模型之前
- 要建立預測編碼模型,審查集中必須至少有 2,000 個項目。
- 在建立模型前,務必將所有收藏都提交到審查集。 模型建立後加入審查集的項目不會被處理,也不會被分配模型產生的預測分數。
- 審查集中任何不含文字的項目,模型不會處理或分配預測分數。 帶有文字的項目會包含在控制集或訓練集中。
建立模型
在Microsoft Purview入口網站中,開啟一個電子發現 (高級) 案件,然後選擇 「審查集 」標籤。
開啟審查集,然後選擇 分析>、管理預測編碼 (預覽) 。
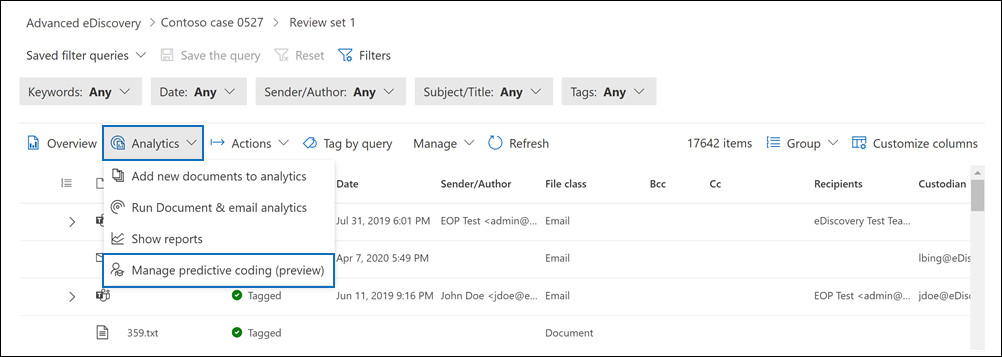
在 預測編碼模型 (預覽) 頁面,選擇 新模型。
在飛出頁面輸入模型名稱及可選描述。
您也可以選擇在飛出頁面 (選擇與信賴程度與誤差範圍相關的 進階選項) 設定進階設定。 這些設定會影響控制組中包含的物品數量。 控制集在訓練過程中用來評估模型對訓練回合中執行的標註項目所分配的預測分數。 如果您的組織有關於文件審查信心水準與誤差範圍的指引,請在適當的欄位中明確說明。 否則,就用預設設定。
選擇 儲存 以建立模型。
系統準備模型需要幾分鐘。 準備好後,你可以進行第一輪訓練。
建立模型後會發生什麼事
在建立模型後,在建立與準備模型的過程中,背景會發生以下事情:
- 系統會計算控制集的項目數量。 此規模基於回顧集的項目數量、置信水準與誤差範圍的設定。 控制組的物品是隨機選擇並指定為控制組物品。 系統包含第一輪訓練中控制組的10項項目。
- 系統會從複習組中隨機選出40題,納入第一輪訓練的訓練集。 因此,第一輪訓練包含50項標註項目:40項來自訓練組,10項來自控制組。
後續步驟
在你建立一個審查集的模型後,下一步就是進行訓練輪次,讓模型「教導」該模型辨識與調查相關的內容。 欲了解更多資訊,請參閱 「訓練預測編碼模型」。