| 梅安娜·佩雷拉 | 斯科特·克利斯蒂安森 |
|---|---|
| CELA 數據科學 | 客戶安全性與信任 |
| Microsoft | Microsoft |
抽象 — 識別安全性錯誤報告 (SBR) 是軟體開發生命週期中的重要一步。 在以監督式機器學習為基礎的方法中,通常假設完整的 Bug 報告都可供訓練,並且其標籤被認為是無雜訊的。 據我們所知,這是第一項研究表明,即使僅有標題可用並且存在標籤噪音的情況下,SBRs 仍然可以進行精確的標籤預測。
索引字詞 — 機器學習、錯誤標記、雜訊、安全性錯誤報告、錯誤資料庫
我。 介紹
在回報的 Bug 中找出安全性相關問題是軟體開發小組迫切需要的問題,因為這類問題需要更快速的修正,以符合合規性需求,並確保軟體和客戶數據的完整性。
機器學習和人工智慧工具有望讓軟體開發更快速、敏捷且正確。 數位研究人員已將機器學習應用於識別安全性 Bug [2]、[7]、[8]、[18] 的問題。先前發佈的研究假設整個 Bug 報告可用於定型和評分機器學習模型。 這不一定是這種情況。 在某些情況下,無法提供整個 Bug 報告。 例如,錯誤報告可能包含密碼、個人識別資訊(PII)或其他種類的敏感數據,而我們目前面臨Microsoft的情況。 因此,了解在只有較少資訊的情況下(例如僅有 Bug 報告的標題)識別安全性漏洞的有效性是很重要的。
此外,錯誤儲存庫通常包含標錯的條目 [7]:將非安全性錯誤報告分類為安全性相關,反之亦然。 發生錯誤標記的原因有很多,從開發小組缺乏安全性專業知識到某些問題的模糊性,例如,非安全性 Bug 有可能以間接方式惡意探索,以造成安全性影響。 這是一個嚴重的問題,因為 SRS 的標記錯誤會導致安全性專家必須以昂貴且耗時的努力手動檢閱 Bug 資料庫。 了解雜訊如何影響不同的分類器,以及不同機器學習技術在面對被各種雜訊污染的數據集時,其穩健性(或脆弱性),是必須解決的問題,以將自動分類應用於軟體工程的實務中。
初步工作認為 Bug 存放庫本質上是雜訊,而且雜訊可能對效能機器學習分類器 [7] 產生負面影響。 不過,目前缺乏系統且量化的研究來探討不同層級和類型的雜訊如何影響不同監督機器學習演算法在識別安全性錯誤報告(SRB)問題上的效能。
在這項研究中,我們顯示,即使只有標題可供訓練和評分,也可以執行 Bug 報告的分類。 據我們所知,這是首個進行此類研究的項目。 此外,我們提供了對錯誤報告分類中雜訊影響的第一個系統研究。 我們比較研究三種機器學習技術(邏輯迴歸、樸素貝氏和 AdaBoost)的魯棒性,以對抗與類別無關的噪音。
雖然有一些分析模型可擷取一些簡單分類器 [5]、 [6] 的雜訊一般影響,但這些結果不會對雜訊對精確度的影響提供緊密界限,而且僅適用於特定的機器學習技術。 對機器學習模型中雜訊效果的準確分析通常是藉由執行計算實驗來執行。 從軟體測量數據 [4] 到衛星影像分類 [13] 和醫療數據 [12] 等數種案例,都進行了這類分析。 然而,由於這些結果高度相依於數據集的性質和基礎分類問題,因此無法轉譯成我們的特定問題。 目前根據我們所知,尚未有已發佈的研究結果探討嘈雜數據集對於安全性錯誤報告分類的影響問題。
我們的研究貢獻:
我們會訓練分類器,以僅根據報告標題來識別安全性錯誤報告(SBR)。 據我們所知,這是首個這樣做的研究。 先前的運作方式是使用完整的 Bug 報告,或透過其他互補功能增強 Bug 報告。 當由於隱私問題無法提供完整的 Bug 報告時,僅依據圖塊進行的 Bug 分類特別重要。 例如,臭名昭著的是包含密碼和其他敏感數據的 Bug 報告。
我們也提供第一個系統研究不同機器學習模型的標籤雜訊容忍度,以及用於自動分類 SBR 的技術。 我們比較研究三種不同的機器學習技術(羅吉斯回歸、貝氏天真和 AdaBoost)對類別相依和與類別無關的雜訊的強固性。
論文的其餘部分如下:在第二節中,我們介紹了文學中的一些先前的作品。 在第三節中,我們會描述數據集,以及如何預先處理數據。 方法會在第四節中說明,以及我們在第 V 節中分析的實驗結果。最後,我們的結論和未來作品在六中呈現。
第二節 上一個工作
機器學習在 BUG 存放庫中的應用。
在利用文本採礦、自然語言處理和機器學習技術研究 bug 存放庫的廣泛文獻中,常見的目標之一是自動化某些繁瑣的任務,比如安全性 bug 偵測[2]、[7]、[8]、[18]、bug 重複識別[3]、bug 分類[1]、[11],僅舉幾個應用來說。 在理想情況下,機器學習(ML)和自然語言處理的結合可能會減少策劃 Bug 資料庫所需的手動工作,縮短完成這些工作所需的時間,並增加結果的可靠性。
在 [7] 中,作者提出一種自然語言模型,用於根據 Bug 的描述自動對 SBR 進行分類。 作者會從定型數據集中的所有 Bug 描述中擷取詞彙,並手動將其策劃成三個單字清單:相關單字、停止字詞(似乎與分類無關的常見字詞),以及同義字。 他們比較由安全性工程師評估數據訓練的安全性漏洞分類器效能,和由一般漏洞回報者標記數據訓練的分類器效能。 雖然在安全性工程師檢閱的數據上訓練時,其模型顯然更有效,但建議的模型是以手動衍生的詞彙為基礎,這使得模型依賴於人為策展。 此外,沒有分析不同等級的雜訊如何影響其模型、不同的分類器如何響應雜訊,以及任一類別中的雜訊是否對效能產生不同的影響。
Zou et.al [18] 會利用 Bug 報表中包含的多種資訊類型,其中包含 Bug 報表的非文字欄位(例如時間、嚴重性和優先順序)以及 Bug 報表的文字內容(例如摘要欄位中的文字特徵)。 根據這些功能,他們會建置模型,以透過自然語言處理和機器學習技術自動識別 SBR。 在 [8] 中,作者會執行類似的分析,但此外,他們會比較受監督和未監督機器學習技術的效能,並研究訓練其模型所需的數據量。
在 [2] 中,作者也會探索不同的機器學習技術,根據其描述將 Bug 分類為 SBR 或 NSR(非安全性錯誤報告)。 他們建議以 TFIDF 為基礎的數據處理和模型定型管線。 他們會將所提議的流程與以單字袋和天真貝氏為基礎的模型進行比較。 Wijayasekara 等人 [16] 也使用文字採礦技術,根據常用字詞來產生每個 Bug 報告的特徵向量,以識別隱藏影響 Bug(HIB)。 楊等人聲稱,借助詞頻(TF)和朴素貝葉斯,找出高影響的錯誤報告(例如SBRs)。 在 [9] 中,作者建議模型來預測 Bug 的嚴重性。
卷標雜訊
處理帶有標籤雜訊的數據集的問題已被廣泛研究。 Frenay 和 Verleysen 在 [6] 中提出了一個標籤噪音分類法,以區分不同類型的噪音標籤。 作者提出了三種不同類型的標籤雜訊:第一種是獨立於真實類別和實例特徵值的標籤雜訊;第二種是僅依賴於真實標籤的標籤雜訊;以及第三種是誤標機率也取決於特徵值的標籤雜訊。 在我們的工作中,我們研究前兩種類型的噪音。 從理論上的觀點來看,捲標雜訊通常會降低模型的效能 [10],但在某些情況下 [14] 除外。 一般而言,穩健的方法依賴避免過度擬合來處理標籤雜訊 [15]。 在衛星影像分類 [13]、軟體質量分類 [4] 和醫學領域分類 [12] 等許多領域,對分類中的噪音效果的研究以前已經完成。 據我們所知,尚未有任何出版作品研究在SBRs分類問題中嘈雜標籤效果的精確量化。 在此案例中,尚未建立雜訊等級、雜訊類型和效能降低之間的精確關聯性。 此外,值得瞭解不同的分類器在噪音的存在下的行為。 更普遍的是,我們不知道任何有系統地研究嘈雜數據集對軟體錯誤報告內容中不同機器學習演算法效能的影響的工作。
第三。 數據集描述
我們的數據集包含 1,073,149 個錯誤標題,其中 552,073 個對應至 SBR,521,076 個則對應至 NSBR。 這些數據是從 2015 年、2016 年、2017 年和 2018 年 Microsoft 各團隊收集而來。 所有標籤都是透過基於特徵碼的錯誤驗證系統或由人工標記取得。 數據集中的 Bug 標題非常簡短,包含大約 10 個單字,並概述問題。
一個。 數據前置處理 我們會依空白區剖析每個 Bug 標題,以產生令牌清單。 我們會處理每個令牌清單,如下所示:
移除所有的檔案路徑符號
分割標記,其中存在下列符號:{ 、(、)、-、}、{、[、]、}
拿掉停用字詞、僅由數字字元組成的標記,以及在整個語料庫中出現少於 5 次的標記。
四。 方法論
定型機器學習模型的程式包含兩個主要步驟:將數據編碼為特徵向量,以及定型受監督的機器學習分類器。
一個。 特徵向量和機器學習技術
第一個部分涉及使用 [2] 中使用的 frequencyinverse 檔頻率演算法 (TF-IDF) 一詞,將數據編碼為特徵向量。 TF-IDF 是一種資訊擷取技術,可權衡詞彙頻率(TF)及其反向文件頻率(IDF)。 每個單字或字詞都有其各自的 TF 和 IDF 分數。 TF-IDF 演算法會根據出現在檔中的次數,將該字指派給該字的重要性,更重要的是,它會檢查關鍵詞在整個數據集標題集合中的相關性。 我們訓練和比較了三種分類技術:天真貝氏(NB)、提升判定樹(AdaBoost)和羅吉斯回歸(LR)。 我們選擇了這些技術,是因為它們在文獻中基於完整報告識別安全漏洞報告的相關任務中已證明有良好的表現。 在初步分析中確認了這些結果,這三個分類器優於支援向量機器和隨機樹系。 在我們的實驗中,我們會使用 scikit-learn 連結庫進行編碼和模型定型。
B. 雜訊類型
這項工作中研究的雜訊是指訓練數據中類別標籤的雜訊。 因此,在這類雜訊的存在下,學習程式與產生的模型會因為錯誤範例而受損。 我們會分析套用至類別資訊的不同雜訊等級的影響。 標籤噪音的類型此前曾在文獻中使用各種術語討論過。 在我們的工作中,我們會分析分類器中兩種不同的標籤噪音的影響:與類別無關的標籤噪音,這是藉由隨機選擇樣本並翻轉其標籤所引入的;以及類別相依的噪音,其中類別有不同的可能性導致噪音。
a) 與類別無關的雜訊:與類別無關的雜訊是指與實例真實類別無關的雜訊。 在此類型的雜訊中,數據集中每個實例的錯誤標記 pbr 機率都相同。 我們透過以機率 pbr隨機翻轉數據集中的每個標籤,來引入與類別無關的雜訊。
b) 類別相依雜訊:類別相依雜訊是指相依於實例之真實類別的雜訊。 在這種類型的雜訊中,SBR 類別中錯誤標記的機率是 psbr,而 NSBR 類別中錯誤標記的機率是 pnsbr。 我們在數據集中引入類別相依的雜訊,方法是對每一個真實標籤為 SBR 的項目,以機率 psbr進行翻轉。 同樣地,我們會使用機率 pnsbr來翻轉 NSBR 實例的類別標籤。
c) 單類別雜訊:單一類別雜訊是類別相依雜訊的特殊案例,其中 pnsbr = 0,psbr> 0。 請注意,對於與類別無關的雜訊,我們有 psbr = pnsbr = pbr。
C. 雜訊產生
我們的實驗會調查 SBR 分類器訓練中不同雜訊類型和層級的影響。 在我們的實驗中,我們會將數據集的 25% 設定為測試數據、10 個% 作為驗證,65 個% 作為定型數據。
我們會針對不同層級的 pbr、psbr 和 pnsbr,將雜訊新增至定型和驗證數據集。 我們不會對測試數據集進行任何修改。 所使用的不同雜訊等級是 P = {0.05 × i|0 < i < 10}。
在與類別無關的雜訊實驗中,針對 pbr ∈ P,我們會執行下列動作:
產生訓練和驗證資料集的噪聲。
使用訓練資料集訓練羅吉斯回歸、朴素貝氏和 AdaBoost 模型(具有雜訊);使用驗證資料集調整模型(含雜訊);
使用測試數據集測試模型(無雜訊)。
在類別相依雜訊實驗中,針對 psbr ∈ P 和 pnsbr ∈ P,我們會針對 psbr 和 pnsbr的所有組合執行下列作業:
產生訓練和驗證資料集的噪聲。
使用具有雜訊的訓練數據集來訓練羅吉斯回歸、朴素貝葉斯和 AdaBoost 模型。
使用驗證數據集調整模型(具有雜訊):
使用測試數據集測試模型(無雜訊)。
V. 實驗結果
在本節中,會根據第四節中所述的方法,分析實驗的結果。
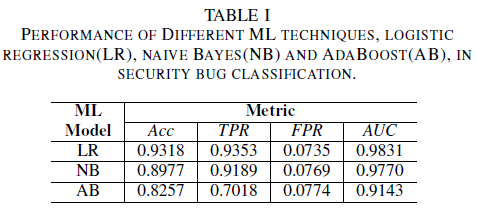
a) 在定型數據集中沒有雜訊的模型效能:本文的其中一個貢獻是提出了一種機器學習模型,僅使用 Bug 標題作為決策的依據來識別安全漏洞。 這可讓機器學習模型定型,即使開發小組不想因為敏感數據的存在而完全共用錯誤報告。 我們比較在只使用 Bug 標題進行訓練時三個機器學習模型的效能。
羅吉斯回歸模型是效能最佳的分類器。 它是 AUC 值最高的分類器,值為 0.9826,在 FPR 值為 0.0735 時有 0.9353 的召回率。 天真貝葉斯分類器的效能略低於羅吉斯回歸分類器,AUC 為 0.9779,當 FPR 為 0.0769 時,召回率為 0.9189。 與先前提到的兩個分類器相比,AdaBoost 分類器具有劣質的效能。 它達到了 0.9143 的 AUC,並在 0.0774 的 FPR 下達到了 0.7018 的召回率。 ROC 曲線下的區域 (AUC) 是比較數個模型效能的好計量,因為它摘要說明 TPR 與 FPR 關聯的單一值。 在後續的分析中,我們會將比較分析限製為 AUC 值。
一個。 類別噪音:單一類別
人們可以想像一個案例,其中所有 Bug 預設都會指派給 NSBR 類別,而且只有在有安全性專家檢閱 Bug 存放庫時,才會將 Bug 指派給類別 SBR。 此案例以單一類別實驗的設定來表示,我們假設 pnsbr = 0 和 0 < psbr< 0.5。
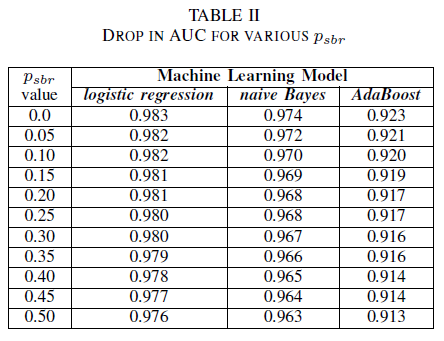
從表格II中,我們觀察到這三個分類器在AUC中的影響很小。 在模型 AUC-ROC,其中 psbr = 0,與 psbr = 0.25 的模型 AUC-ROC 相比,羅吉斯迴歸的差異為 0.003,朴素貝葉斯為 0.006,而 AdaBoost 也是 0.006。 在 psbr = 0.50 的情況下,每個模型所測量的 AUC 與 psbr = 0 所定型的模型相比,羅吉斯回歸差異為 0.007,樸素貝葉斯差異為 0.011,而 AdaBoost 的差異則為 0.010。 在單一類別雜訊的存在下訓練的羅吉斯迴歸分類器,其 AUC 指標的變化幅度最小,也就是說,與我們的朴素貝氏和 AdaBoost 分類器相比,它的表現更為穩健。
B. 類別雜訊:與類別無關
我們比較了三個分類器的效能,當訓練集受到與類別無關的噪音損毀時的情況。 我們會針對訓練數據中以不同層級的 pbr 定型的每個模型測量 AUC。
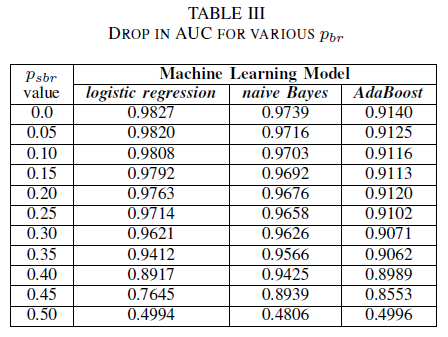
在表格 III 中,我們觀察到在實驗中每增加一次雜訊,AUC-ROC 都會減少。 AUC-ROC 測量的結果是基於使用無雜訊數據訓練的模型,比較於使用類別獨立噪聲 (pbr = 0.25) 訓練的模型的 AUC-ROC,在羅吉斯回歸中相差 0.011,在樸素貝氏中相差 0.008,而在 AdaBoost 中相差 0.0038。 我們觀察到當雜訊等級低於 40%時,標籤雜訊不會顯著影響朴素貝氏和 AdaBoost 分類器的曲線下面積 (AUC)。 另一方面,羅吉斯回歸分類器會對卷標雜訊等級超過 30%的 AUC 量值產生影響。
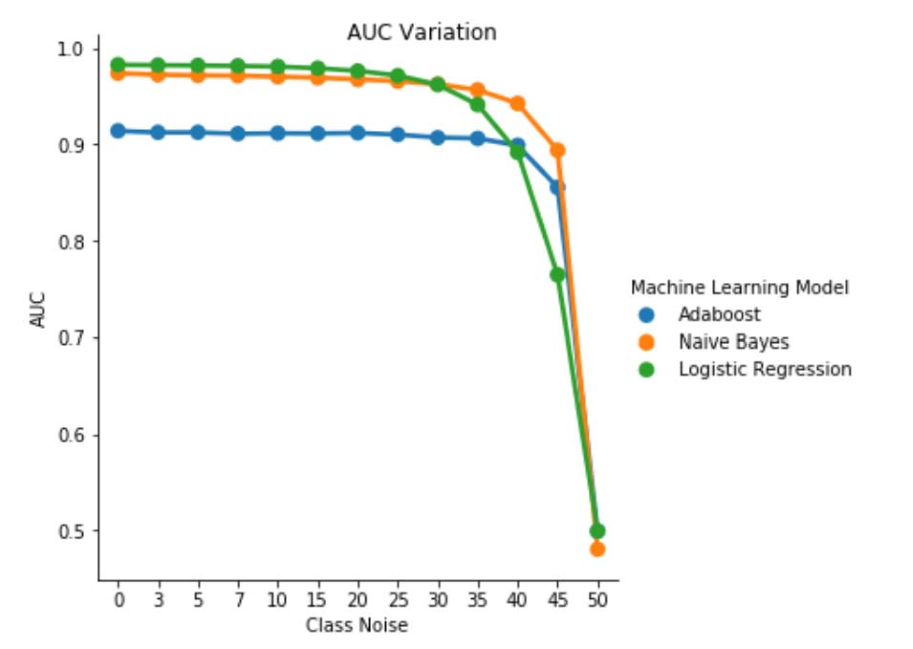
圖 1. 類別獨立雜訊中 AUC-ROC 參數的變化。 對於雜訊等級 pbr =0.5,分類器的作用就像隨機分類器,例如 AUC≈0.5。 但是我們可以觀察到,對於較低的雜訊等級(pbr ≤ 0.30),羅吉斯回歸學習模組與其他兩個模型相比,提供了更好的效能。 不過,對於 0.35≤ pbr ≤ 0.45,朴素貝氏學習器呈現更佳的 AUCROC 指標。
C. 類別雜訊:類別相依
在最後一組實驗中,我們會考慮不同類別包含不同雜訊等級的案例,例如 psbr ≠ pnsbr。 我們在訓練數據中將 psbr 和 pnsbr 各自獨立地以0.05遞增,並觀察三個分類器的行為變化。
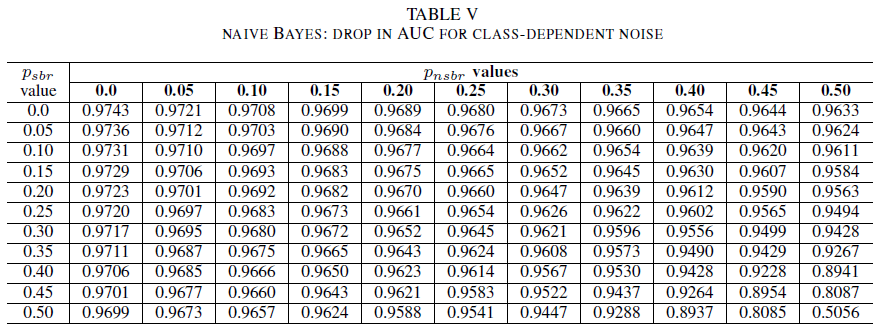
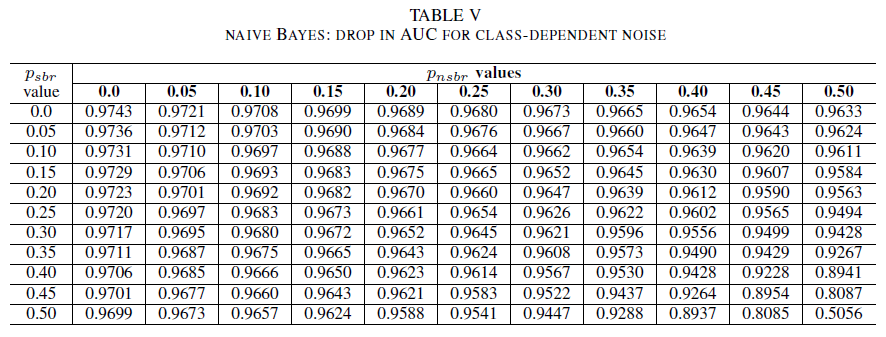
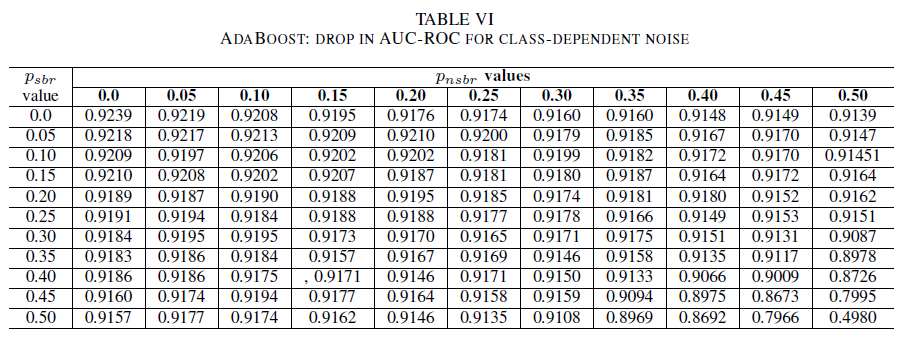
表格 IV、V 和 VI 分別展示了在不同類別中,隨著噪音水平增加,AUC 的變化情況:表格 IV 對應羅吉斯回歸,表格 V 對應朴素貝葉斯,表格 VI 則對應 AdaBoost。 對於所有分類器,當這兩個類別的雜訊等級高於 30(%)時,我們注意到 AUC 指標受到影響。 天真的貝氏行為健全。 即使在正類別中有50個% 標籤被更改的情況下,只要負類別包含不超過30個% 的噪音標籤,對AUC的影響仍然很小。 在此情況下,AUC 中的下降值為 0.03。 AdaBoost 呈現這三個分類器中最強固的行為。 AUC 的顯著變化只有在雜訊等級超過兩個類別中 45% 時才會發生。 在此情況下,我們會開始觀察大於0.02的AUC衰變。
D. 存在於原始數據集中的剩餘雜訊
我們的數據集是由以簽章為基礎的自動化系統和人類專家所標記。 此外,人類專家已進一步審查和關閉所有 Bug 報告。 雖然我們預期數據集中的雜訊量最低且不具統計意義,但剩餘雜訊的存在不會使結論失效。 事實上,為了圖解,假設原始數據集因類別獨立雜訊損毀,等於 0 < p < 1/2 獨立同分佈(即 i.i.d) 的每個項目。
如果我們在原始雜訊之上,新增一個具有機率 pbr i.i.d 的類別獨立雜訊,則每個條目的產生雜訊將會是 p∗ = p(1 − pbr )+(1 − p)pbr。 對於 0 < p,pbr< 1/2,我們有每個標籤 p 的實際雜訊∗嚴格大於我們人為地新增至數據集 pbr 的雜訊。 所以,如果分類器最初是使用完全無雜訊的數據集(p = 0)進行訓練,則其效能會更好。 總而言之,實際數據集中殘差雜訊的存在表示,對分類器雜訊的復原能力比這裡呈現的結果更好。 此外,若我們數據集中的剩餘雜訊在統計上具有顯著性,那麼當雜訊層級嚴格低於0.5時,我們的分類器的AUC將降至0.5(即隨機猜測)。 我們不會在結果中觀察到這種行為。
六。 結論和未來工作
我們在本文中的貢獻有兩個方面。
首先,我們已根據 Bug 報告的標題,顯示安全性錯誤報告分類的可行性。 這在因隱私權限制而無法使用整個 Bug 報告的情況下特別相關。 例如,在我們的案例中,Bug 報告包含密碼和密碼編譯密鑰等私用資訊,而且無法訓練分類器。 我們的結果顯示,即使只有報表標題可用,SBR 識別仍能以高精確度執行。 我們的分類模型使用 TF-IDF 和羅吉斯回歸的組合,達到了 AUC 0.9831 的表現。
其次,我們分析了錯誤標記訓練和驗證數據的影響。 我們比較了三種知名的機器學習分類技術(朴素貝葉斯、羅吉斯回歸和 AdaBoost),以針對不同噪聲類型和噪聲等級的穩定性。 這三個分類器對單類噪音具有強健的抵抗力。 定型數據中的雜訊對產生的分類器沒有顯著的影響。 在 50%的雜訊水準下,AUC 的降幅非常小(0.01)。 針對同時存在於兩個類別且與類別無關的雜訊,只有當貝氏機率和 AdaBoost 模型在訓練資料集中的雜訊等級大於 40%時,AUC 才會呈現顯著變化。
最後,類別相依雜訊只有在這兩個類別中有超過 35 個% 雜訊時,才會顯著影響 AUC。 AdaBoost 表現出最強固性。 即使正類別中有50%的標籤是模糊的(%),只要負類別中包含不超過45%的模糊標籤(%),AUC的影響仍然非常小。 在此情況下,AUC 中的下降小於 0.03。 據我們所知,這是針對安全性 Bug 報告識別的嘈雜數據集效果進行的第一個系統研究。
未來工程
在本文中,我們已開始系統性地研究雜訊對機器學習分類器效能的影響,旨在識別安全漏洞。 這項工作有幾個有趣的研究方向,包括:檢查嘈雜數據集在判斷安全性漏洞嚴重性等級時的影響;理解類別不平衡對訓練模型抗噪能力的影響;了解數據集中對抗性引入的噪聲效果。
引用
[1] 約翰·安維克、林登·希尤和蓋爾·墨菲。 誰應該修正此錯誤? 第28屆軟體工程 國際會議第361-370頁。 ACM, 2006。
[2] Diksha Behl、Sahil Handa 和 Anuja Arora。 利用貝氏機率和 tf-idf 技術來識別和分析安全漏洞的挖掘工具。 在 優化、可靠性和資訊技術(ICROIT),2014年國際會議論文集,第 294 至 299 頁。 IEEE, 2014。
[3] 尼古拉·貝滕堡、拉胡爾·普雷姆拉傑、湯瑪斯·齊默爾曼和宋順·金。 重複的錯誤報告真的會被視為有害嗎? 在 軟體維護中,2008 年。ICSM 2008。IEEE 國際會議,第 337-345 頁。 IEEE, 2008。
[4] Andres Folleco、Taghi M Khoshgoftaar、Jason Van Hulse 和 Lofton Bullard。 識別對低品質數據具有韌性的學習者。 在 資訊重複使用和整合中,2008 年 IRI 2008 IEEE 國際會議,第 190 至 195 頁。 IEEE, 2008。
[5] Benoˆıt Frenay. 機器學習中的不確定性和標籤噪聲。 2013年比利時盧文-拉諾夫天主教大學盧汶新城博士論文。
[6] 貝諾伊·弗雷內和米歇爾·維爾萊森。 存在標籤噪音時的分類:综述。 神經網路和學習系統上的 IEEE 交易,25(5):845–869,2014。
[7] 邁克爾·格吉克、彼特·羅泰拉和陶謝。 透過文字採礦識別安全性錯誤報告:產業案例研究。 在 採礦軟體存放庫 (MSR), 2010 第 7 屆 IEEE 工作會議,,第 11-20 頁。 IEEE, 2010。
[8] 凱蒂娜·Goseva-Popstojanova 和雅各·蒂約。 使用受監督和未監督分類,透過文字採礦識別安全性相關 Bug 報告。 在 2018 年 IEEE 軟體品質、可靠性和安全性國際會議,第 344-355 頁,2018 年。
[9] 艾哈邁德·拉姆坎菲、謝爾蓋·德邁爾、伊曼紐爾·吉格和巴特·戈多亞斯。 預測回報 Bug 的嚴重性。 在 採礦軟體存放庫 (MSR), 2010 第 7 屆 IEEE 工作會議,,第 1-10 頁。 IEEE, 2010。
[10] 納雷什·曼瓦尼和 PS 薩斯特裡。 風險最小化下的雜訊承受能力。 IEEE 控制論匯刊, 43(3):1146–1151, 2013。
[11] G 墨菲和 D 庫布拉尼克。 使用文本分類自動化錯誤管理。 在 第十六屆軟體工程 & 知識工程國際會議上。 Citeseer,2004年。
[12] Mykola Pechenizkiy、Alexey Tsymbal、Seppo Puuronen 和 Oleksandr Pechenizkiy。 醫學領域中的類別雜訊和監督式學習:特徵擷取的效果。 在 null中,頁面 708–713。 IEEE, 2006。
[13] 夏洛特·佩萊蒂埃、西爾維亞·瓦列羅、約迪·英格拉達、尼古拉斯冠軍、克萊爾·馬萊斯·西克里和傑拉德·迪厄。'訓練班標籤噪音對土地覆蓋測繪與衛星圖像時間序列的分類性能的影響。 遙感, 9(2):173, 2017年。
[14] PS Sastry、GD Nagendra 和 Naresh Manwani。 用於半空間噪聲容忍學習的連續動作學習自動機團隊。 IEEE 系統、人、及控制論匯刊,第 B 部分(控制論),40(1):19–28,2010。
[15] Choh-Man Teng。 雜訊處理技術的比較。 在 FLAIRS 會議,頁 269–273 (2001)。
[16] 杜米杜·維賈亞塞卡拉、米洛斯·馬尼奇和邁爾斯·麥昆。 透過文字採礦 Bug 資料庫進行弱點識別和分類。 在 工業電子學會中,IEEE IECON 2014 第 40 屆年會,頁 3612–3618。IEEE,2014。
[17] 新麗楊、大衛·羅、喬黃、新霞、建陵孫。 利用不平衡學習策略自動識別高影響 Bug 報告。 在 電腦軟體與應用程式會議(COMPSAC),2016 IEEE 第40屆年會,第1卷,第227-232頁。 IEEE, 2016。
[18] 德慶祖、志軍鄧、珍麗、海金。 透過多重類型功能分析自動識別安全性錯誤報告。 在 澳大利亞資訊安全與隱私權會議上,第 619–633 頁。 斯普林格,2018年。