由安德魯·馬歇爾、朱加爾·帕利赫、埃米爾·基西曼和拉姆·尚卡爾·西瓦·庫瑪律撰寫
特別感謝勞爾·羅賈斯和 AETHER 安全工程工作小組
2019年11月
本檔是 AI 工作組的 AETHER 工程實務交付專案,並提供 AI 和 Machine Learning 空間專屬威脅列舉和風險降低的新指引,以補充現有的 SDL 威脅模型化做法。 在下列安全性設計檢閱期間,其用途是做為參考:
與 AI/ML 型服務互動或取得相依性的產品/服務
以 AI/ML 為核心所建置的產品/服務
傳統安全性威脅緩解比以往更加重要。 安全性開發生命週期所建立的需求對於建立本指導方針所建置的產品安全性基礎至關重要。 無法解決傳統安全威脅,使得本文件中涵蓋的 AI/ML 特定攻擊在軟體和實體領域更為可能,並且 讓軟體堆疊的下層更容易受到侵害。 如需取得此領域中全新安全威脅的簡介,請參閱 在 Microsoft 保護 AI 和 ML 的未來。
安全性工程師和數據科學家的技能集通常不會重疊。 本指南提供這兩個專業領域在這類新威脅/風險降低上建立結構化對話的方式,而不需要安全性工程師成為數據科學家,反之亦然。
本檔分成兩個區段:
- 「威脅模型化的重要新考慮」著重於新的思維方式,以及威脅模型化 AI/ML 系統時要問的新問題。 數據科學家和安全性工程師都應該檢閱這一點,因為這將會是其威脅模型化討論和風險降低優先順序的劇本。
- 「AI/ML 特定威脅及其風險降低」提供特定攻擊的詳細數據,以及目前使用的特定風險降低步驟,以保護Microsoft產品和服務免受這些威脅。 本節主要針對可能需要實作特定威脅防護功能的數據科學家,作為威脅模型化/安全性檢閱程序的輸出。
本指南是圍繞由 Ram Shankar Siva Kumar、David O'Brien、Kendra Albert、Salome Viljoen 和 Jeffrey Snover 所建立的、名為《機器學習中的故障模式》的對抗性機器學習威脅分類法所組織的。 如需有關分類本文件詳述之安全性威脅的事件管理指引,請參閱 適用於 AI/ML 威脅的 SDL Bug 列。 所有這些都是隨著威脅形勢而演變的活生生的檔。
威脅模型化的重要新考慮:變更檢視信任界限的方式
假設您用來訓練的數據和數據提供者遭到入侵或中毒。 瞭解如何偵測異常和惡意的數據項目,並能夠分辨並復原這些異常和惡意數據
總結
訓練數據存儲和承載它們的系統是您威脅建模範圍的一部分。 現今機器學習服務中最大的安全性威脅是數據中毒,因為此空間中缺少標準偵測和風險降低,再加上依賴不受信任/未壓縮的公用數據集作為訓練數據的來源。 追蹤數據的來源和譜系,對於確保數據的可信度,並避免「垃圾進出」訓練周期至關重要。
安全性檢閱中要詢問的問題
如果您的數據遭到有害或竄改,您該如何知道?
- 您擁有哪些遙測數據可以偵測訓練數據品質的偏差?
您要從使用者提供的輸入進行訓練嗎?
-您在該內容上執行何種輸入驗證/清理?
-此數據的結構是否有記錄,並類似於 數據集資料表?
如果您針對在線數據存放區定型,您需要採取哪些步驟來確保模型與數據之間的連線安全性?
-他們有向飼料消費者報告危害的方法嗎?
-他們甚至有能力嗎?
您訓練的資料有多敏感?
-您是否將它編錄或控制新增/更新/刪除數據項?
您的模型可以輸出敏感數據嗎?
-此數據是以來源的許可權取得的嗎?
模型是否只輸出達到其目標所需的結果?
您的模型是否會傳回原始信賴分數或任何其他可記錄和複製的直接輸出?
透過攻擊或反轉您的模型來恢復訓練數據 對其影響為何?
如果模型輸出的信賴等級突然下降,您可以瞭解原因,以及造成它的數據為何?
您是否為模型定義了格式正確的輸入? 您要做什麼以確保輸入符合此格式,如果輸入不符合,該怎麼辦?
如果您的輸出有錯誤,但不會導致錯誤被報告,您要怎麼知道?
您知道您的訓練算法是否具有抵抗能力以應對在數學層面上的對抗性輸入?
如何從訓練數據的對立污染中恢復?
-您是否可以隔離/隔離對立內容,並重新定型受影響的模型?
-您是否可以將模型還原或復原至舊版,以進行重新訓練?
您是否在未清理的公用內容上使用增強式學習?
開始思考您的數據來源——如果您發現問題,是否可以追蹤到問題是如何導入到數據集的? 如果不是,這是個問題嗎?
瞭解您的訓練數據來源並識別統計規範,以便開始理解異常的樣貌。
-訓練數據的哪些元素容易受到外部影響?
-誰可以貢獻您要訓練的資料集?
- 你會如何 攻擊競爭對手的訓練數據來源來造成損害?
本文件中的相關威脅和緩解措施
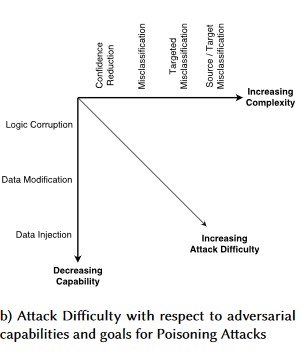
對抗性擾動 (所有變種)
資料中毒(所有變體)
範例攻擊
強制將良性電子郵件分類為垃圾郵件,或造成惡意範例無法偵測
由攻擊者精心設計的輸入,可降低正確分類的信心水準,尤其是在高風險情境下。
攻擊者會隨機將雜訊插入要分類的源數據中,以減少未來使用正確分類的可能性,有效地打亂模型
訓練數據被污染以強制錯誤分類選定的數據點,結果導致系統採取特定行動或忽略某些行動。
識別您的模型或產品/服務可能會造成在線或實體網域中客戶傷害的動作
總結
如果不加以緩解,AI/ML 系統遭受的攻擊可能會影響到實體世界。 任何可能扭曲為心理或身體傷害使用者的案例,都是您的產品/服務災難性風險。 這延伸至用於訓練和設計選擇的任何客戶敏感數據,這些選擇可能會洩露客戶的隱私數據。
安全性檢閱中要詢問的問題
您是否使用對立範例進行訓練? 它們對您的實體網域中的模型輸出有何影響?
網路霸凌對您的產品/服務有什麼樣的影響? 如何偵測及回應?
要讓您的模型返回一個結果,使您的服務拒絕合法使用者的存取,需要什麼條件?
被複製/遭竊對模型造成什麼影響?
您的模型是否可用來推斷個別人員是否為特定群組的成員,或者只是定型資料中的一部分?
攻擊者是否可以強制產品執行特定動作,造成信譽損害或PR反彈?
如何處理格式正確但明顯偏頗的數據,例如來自網路酸民的數據?
對於每一個公開的模型互動或查詢方式,可以對其進行詳細詢問以揭示訓練數據或模型功能嗎?
本文件中的相關威脅和緩解措施
成員資格推斷
模型反轉
模型竊取
範例攻擊
藉由反覆查詢模型以獲得最具信心的結果,重建並擷取訓練數據。
透過詳盡的查詢/回應比對來複製模型本身
以顯示私用數據特定元素的方式查詢模型已包含在定型集中
自動駕駛汽車被騙忽略停車標誌/紅綠燈
被操縱來騷擾良性使用者的聊天機器人
識別 AI/ML 相依性的所有來源,以及數據/模型供應鏈中的前端呈現層
總結
人工智慧和機器學習中的許多攻擊開始於合法存取 API,而這些 API 是用來提供對模型的查詢存取權。 由於此處涉及豐富的數據來源和豐富的用戶體驗,經身份驗證但「不適當」(這裡有灰色地帶)的第三方對您的模型存取是一種風險,因為它能夠充當 Microsoft 提供的服務之上的展示層。
安全性檢閱中要詢問的問題
哪些客戶/合作夥伴經過驗證,以存取您的模型或服務 API?
-他們是否可以作為服務之上的展示介面?
如果遭到入侵,您可以立即撤銷其存取權嗎?
-發生服務或相依性惡意使用時,您的復原策略為何?
第三方能否在模型周圍建置幕,以重新利用模型,並損害 Microsoft 或其客戶?
客戶是否直接向您提供訓練數據?
-如何保護該數據?
-如果它是惡意的,而您的服務是目標,該怎麼辦?
誤判在這裡的表現形式是什麼樣的? 偽陰性的影響是什麼?
您可以追蹤和測量跨多個模型之真判與誤判率的偏差嗎?
您需要哪種遙測,才能向客戶證明模型輸出的可信度?
識別您的 ML/訓練數據供應鏈中的所有第三方依賴性 – 不只是開放原始碼軟體,還包括數據提供者。
-為什麼您使用它們,以及如何驗證其可信度?
您是否使用第三方預先建立的模型,或將訓練數據提交至第三方 MLaaS 提供者?
盤點有關類似產品/服務攻擊事件的新聞報導。 了解許多 AI/ML 威脅在不同模型類型間的轉移,這些攻擊會對您自己的產品造成什麼影響?
本文件中的相關威脅和緩解措施
類神經網路重新程式撰寫
實體網域中的對抗範例
惡意 ML 提供者正在復原訓練數據
攻擊 ML 供應鏈
後門模型
受損的機器學習特定相依性
範例攻擊
惡意的MLaaS提供者使用特定的方法將您的模型植入特洛伊木馬程式。
對抗者客戶在您使用的常見 OSS 相依性中發現弱點,上傳精心設計的訓練數據載荷來破壞您的服務
無良合作夥伴會使用臉部辨識 API,並透過您的服務建立呈現層來產生 Deep Fakes。
AI/ML 特定威脅及其風險降低
#1: 對立的擾動
說明
在干擾式攻擊中,攻擊者會偷偷修改查詢,以從生產部署的模型取得所需的回應[1]。 這是模型輸入完整性的缺口,導致模糊樣式的攻擊,其中最終結果不一定是存取違規或 EOP,而是危害模型的分類效能。 這也可以透過巨魔故意使用某些目標字詞來展現,這樣AI會禁止這些字詞,有效地拒絕提供服務給名稱中包含「禁用」字詞的合法使用者。
 [24]
[24]
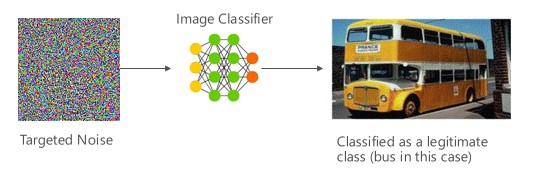
Variant #1a:目標錯誤分類
在此情況下,攻擊者會產生不在目標分類器的輸入類別中,但模型分類為該特定輸入類別的範例。 對立範例可能會像人類眼睛的隨機雜訊一樣出現,但攻擊者對目標機器學習系統有一些瞭解,以產生非隨機但正在利用目標模型的一些特定層面的白雜訊。 敵人會提供不是合法範例的輸入範例,但目標系統會將它分類為合法類別。
範例
 [6]
[6]
緩解措施
使用對立訓練所引發的模型信賴度來強化對抗強固性 [19]:作者建議高度自信近鄰(HCNN),此架構結合了信賴資訊和最近的鄰近搜尋,以強化基底模型的對立強固性。 這有助於從基礎訓練分佈中取樣的點所在鄰域區分模型的正確與錯誤預測。
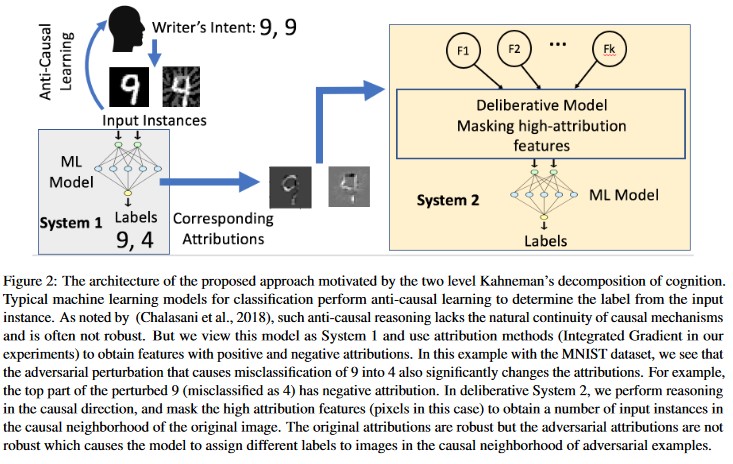
屬性導向的因果分析 [20]:作者會研究對對抗性干擾的復原能力與機器學習模型所產生個別決策的屬性型說明之間的聯繫。 他們報告說,對立輸入在屬性空間中不穩定,即遮罩掉一些具有高屬性的特徵會導致機器學習模型在對立範例上出現決策不穩。 相反地,自然輸入在屬性空間中很健全。
 [20]
[20]
這些方法可讓機器學習模型對對立攻擊更具彈性,因為愚弄這兩層認知系統不僅需要攻擊原始模型,而且可確保針對對抗範例產生的屬性與原始範例類似。 這兩個系統都必須同時遭到入侵,才能成功進行對立攻擊。
傳統類似物
遠端提高許可權,因為攻擊者現在控制您的模型
嚴重程度
危急
Variant #1b:來源/目標分類錯誤
這被描述為攻擊者試圖使模型針對指定輸入返回他們所需的標籤。 這通常會強迫模型返回假陽性或假陰性。 最終結果是對模型的分類精確度進行微妙的控制,攻擊者可以從而在必要時進行特定的迴避。
雖然此攻擊對分類準確性有重大負面影響,但由於對手不僅必須操縱源數據,使其不再正確加上標籤,還必須特別加上所需的詐騙標籤,因此執行起來也可能更加耗時。 這些攻擊通常牽涉到多個步驟/嘗試強制分類錯誤 [3]。 如果模型容易受到遷移學習攻擊,且使得目標被強制錯誤分類,則可能不會留下明顯的攻擊者流量痕跡,因為此類探查攻擊可以在離線狀態下執行。
範例
強制將良性電子郵件分類為垃圾郵件,或造成惡意範例無法偵測。 這些也稱為模型逃避或模擬攻擊。
緩解措施
反應式/防禦性偵測動作
- 實作 API 呼叫之間的最小時間閾值,以提供分類結果。 這會藉由增加尋找成功干擾所需的整體時間量來減緩多步驟攻擊測試的速度。
主動/防護動作
改善對抗性穩健性的特徵去噪[22]:作者開發了一種新的網路架構,藉由執行特徵去噪來提高對抗性穩健性。 具體來說,網路包含若干區塊,這些區塊使用非局部均值或其他濾波器來去噪特徵;整個網路是端到端訓練的。 當與對抗訓練結合時,特徵去噪網絡可在白盒和黑盒攻擊設定中顯著提升敵對魯棒性的技術水平。
對立訓練和正規化:使用已知的對立範例進行定型,以針對惡意輸入建立復原能力和強固性。 這也可以被視為正規化的形式,其會懲罰輸入漸層的常態,並使分類器的預測函式更平滑(增加輸入邊界)。 這包括信賴率較低的正確分類。
顯示在對抗訓練下,預測函數斜率變化的圖表。
投資開發單調分類技術,並選擇合適的單調特徵。 這可確保敵人無法藉由僅僅填加自負類別 [13] 的特徵來逃避分類器。
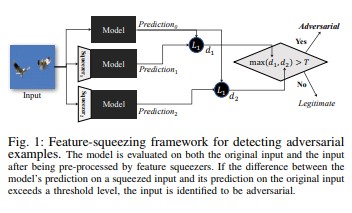
功能擠壓 [18] 可藉由偵測對立範例來強化 DNN 模型。 它藉由將原始空間中許多不同特徵向量的樣本合併為單一樣本,來減少對手可用的搜尋空間。 藉由比較 DNN 模型對原始輸入的預測與擠壓輸入上的預測,特徵擠壓有助於偵測對立範例。 如果原始和擠壓的範例產生與模型截然不同的輸出,則輸入可能是對立的。 藉由測量預測與選取臨界值之間的分歧,系統就可以針對合法範例輸出正確的預測,並拒絕對立輸入。

 [18]
[18]針對對抗範例的認證防禦 [22]:作者根據半明確放寬來建議方法,以輸出給定網路和測試輸入的憑證,任何攻擊都無法強制錯誤超過特定值。 其次,由於此證書是可區分的,作者會與網路參數共同進行優化,提供自適應正規化器,促進對所有攻擊的強固性。
回應動作
- 針對分類器之間結果差異較大的分類結果發出警示,尤其是當結果來自單一使用者或小型使用者群組時。
傳統類似物
遠端提升權限
嚴重程度
危急
變體 #1c:隨機錯誤分類
這是一種特殊的變化,攻擊者的目標分類可以是任何合法來源分類以外的分類。 攻擊通常涉及隨機將雜訊注入正在分類的來源數據中,以降低未來使用正確分類的可能性 [3]。
範例
貓的兩張照片。照片之一被歸類為虎斑貓。在對抗性擾動後,另一張照片被歸類為鱷梨醬。
緩解措施
與 Variant 1a 相同。
傳統類似物
非持久性拒絕服務攻擊
嚴重程度
這很重要
Variant #1d:信賴降低
攻擊者可以構建輸入,來降低正確分類的信心程度,尤其是在高風險情境中。 這也可以採取大量誤判的形式,意在讓系統管理員或監視系統不堪重負,而詐騙警示與合法警示不區分 [3]。
範例

緩解措施
- 除了 Variant #1a 所涵蓋的動作之外,還可以使用事件節流來減少來自單一來源的警示數量。
傳統類似物
非持久性拒絕服務攻擊
嚴重程度
這很重要
#2a 針對性數據中毒
說明
攻擊者的目標是污染 定型階段所產生的機器模型,以便在測試階段[1] 中修改對新數據的預測。 在目標中毒攻擊中,攻擊者想要錯誤分類特定範例,以造成採取或省略特定動作。
範例
將AV軟體提交為惡意代碼,以強制其誤分類為惡意,並消除在客戶端系統上使用目標AV軟體。
緩解措施
定義異常感測器,以每天查看數據分佈,並針對變化發出警示
-每天測量訓練資料的變化,監測偏差/漂移數據
輸入驗證,清理和完整性檢查
資料中毒注入偏離的訓練樣本。 反擊此威脅的兩個主要策略:
-數據清理/驗證:從訓練數據中移除有害樣本 -Bagging 以對抗中毒攻擊 [14]
拒絕啟動Negative-Impact (RONI)防禦 [15]
-健全學習:挑選在有害樣本存在時健全的學習演算法。
-其中一種方法是在 [21] 中描述,作者透過兩個步驟解決資料毒化問題:1)引進新的強固矩陣分解方法,以復原真正的子空間,2)新的強固主成分回歸,根據步驟 (1) 復原的基礎來剔除對抗性實例。 它們界定成功復原真實子空間的必要和充分條件,並提供相較於真實值的預期預測損失的界限。
傳統類似物
遭植入木馬的主機,攻擊者可以持續存在於網路上。 定型或設定數據遭到入侵,並正在被引入或被用於模型創建。
嚴重程度
危急
#2b 不分青紅皂白的數據中毒
說明
目標是破壞遭到攻擊之數據集的品質/完整性。 許多數據集都是公開的、不可信的、未經整理的,因此首先辨識出這類數據完整性問題的能力會引發額外的疑慮。 在無意中被破壞的數據上訓練就像垃圾進垃圾出一樣。 偵測到之後,優先處理必須判斷已遭入侵的數據範圍,並進行隔離和重新訓練。
範例
一家公司從一個知名且受信任的網站撷取石油期貨數據來訓練其模型。 數據提供者的網站隨後會透過 SQL 插入式攻擊遭到入侵。 攻擊者可以任意毒害數據集,而正在定型的模型並不認為數據遭到玷污。
緩解措施
與 variant 2a 相同。
傳統類似物
針對高價值資產的身份驗證拒絕服務攻擊
嚴重程度
這很重要
#3 模型反轉攻擊
說明
機器學習模型中所使用的私人功能可以復原 [1]。 這包括重新建構攻擊者無法存取的私人訓練數據。 在生物特徵辨識社群中,也被稱為「爬坡攻擊」 [16, 17]。這是透過尋找能最大化返回信心水準的輸入來達成的,前提是分類必須與目標一致 [4]。
範例
 [4]
[4]
緩解措施
從敏感數據定型的模型介面需要強式訪問控制。
模型允許的速率限制查詢
為使用者/來電者與實際模型之間實施網關,對所有提出的查詢執行輸入驗證,拒絕任何不符合模型輸入正確性的查詢,並僅返回最少量必要的資訊以確保有用。
傳統類似物
針對性、秘密資訊洩漏
嚴重程度
這會根據標準 SDL 錯誤等級預設設定為重要,但若擷取的是敏感或個人可識別的數據,則會提高至關鍵等級。
#4 會員資格推斷攻擊
說明
攻擊者可以判斷指定的數據記錄是否為模型的定型數據集的一部分[1]。 研究人員成功根據特徵(如年齡、性別、醫院)[1],預測患者的主要治療(例如:患者接受的手術)。
此圖示意會員推斷攻擊的複雜性。箭頭顯示訓練數據與預測數據之間的流向及關係。
緩解措施
示範此攻擊可行性的研究論文指出差異隱私權 [4, 9] 是有效的緩和措施。 這仍然是Microsoft的新興領域,AETHER 安全工程建議在這個領域進行研究投資來建立專業知識。 這項研究需要列舉差分隱私功能,並評估作為風險緩解措施的實際有效性,然後設計方法使這些防禦措施能夠透明地繼承到我們的線上服務平台上,類似於在Visual Studio中編譯程式碼如何提供對開發人員和使用者而言都是透明的預設安全性保護。
神經元卸除和模型堆疊的使用在一定程度上可能是有效的緩和措施。 使用神經元輟學不僅會增加神經網路對這次攻擊的復原能力,也會增加模型效能 [4]。
傳統類似物
數據隱私權。 正在推斷某個數據點是否包含在訓練集中,但不會透露訓練數據本身。
嚴重程度
這是隱私權問題,而不是安全性問題。 因為網域重疊,所以會在威脅模型化指引中加以解決,但此處的任何回應都會由隱私權驅動,而不是安全性。
#5 模型竊取
說明
攻擊者會藉由合法地查詢模型來重新建立基礎模型。 新模型的功能與基礎模型[1] 的功能相同。 重新建立模型之後,就可以反轉復原特徵資訊,或對定型數據進行推斷。
方程式解算 – 對於透過 API 輸出傳回類別機率的模型,攻擊者可以製作查詢來判斷模型中的未知變數。
路徑尋找 – 攻擊會利用 API 特殊性來擷取樹狀結構在分類輸入 [7] 時所採取的「決策」。
可轉移性攻擊 - 對手可以訓練本機模型,可能透過向目標模型發出預測查詢,並用它來打造可轉移至目標模型的對抗樣本 [8]。 如果您的模型被提取且被發現易受某種敵對輸入攻擊,攻擊者可以在完全脫機的情況下針對部署於生產環境的模型發起新攻擊。
範例
在 ML 模型用來偵測對立行為的設定中,例如識別垃圾郵件、惡意代碼分類和網路異常偵測,模型擷取有助於逃避攻擊 [7]。
緩解措施
主動/防護動作
將預測 API 中傳回的詳細數據最小化或模糊化,同時仍維持對「誠實」應用程式[7] 的實用性。
為您的模型輸入定義格式完善的查詢,並只傳回回應符合該格式的已完成且格式完善的輸入的結果。
傳回四捨五入的信賴值。 大多數合規的呼叫方不需要多位小數精度。
傳統類似物
未經驗證的系統數據竄改,僅限於讀取,目的是洩漏高價值資訊。
嚴重程度
在安全性敏感性模型中很重要,否則為中度
#6 類神經網络重新程序設計
說明
藉由來自敵人的特製查詢,機器學習系統可以重新程式設計為偏離建立者原始意圖的工作[1]。
範例
臉部辨識 API 上的弱式訪問控制可讓第三方將其納入旨在傷害 Microsoft 客戶的應用程式,例如深偽生成器。
緩解措施
針對模型介面的用戶端<->伺服器強式相互驗證和訪問控制
取消冒犯帳戶。
識別並強制執行 API 的服務等級協定。 判斷回報問題后可接受的修正時間,並確保問題在 SLA 到期后不再重現。
傳統類似物
這是濫用案例。 您比較不可能在這方面開啟安全事件,而是直接停用相關用戶的帳戶。
嚴重程度
重要至關鍵
#7 實體領域中的對抗範例 (bits->atoms)
說明
對立範例是來自惡意實體的輸入/查詢,其唯一目的是誤導機器學習系統 [1]
範例
這些範例可以顯示在實體領域,例如一輛自駕汽車被騙去運行停車標誌,因為停止標誌上有一定的光線色彩(對立輸入),迫使圖像辨識系統不再將停止標誌視為停止標誌。
傳統類似物
權限提升、遠端代碼執行
緩解措施
這些攻擊本身會顯現出來,因為機器學習層的問題(AI 驅動決策下方的數據和演算法層)並未減輕。 如同任何其他軟體 *或* 實體系統,目標下方的層一律可透過傳統向量受到攻擊。 因此,傳統安全性做法比以往更加重要,尤其是 AI 與傳統軟體之間所使用的未明確弱點層(數據/algo 層)。
嚴重程度
危急
#8 能復原訓練數據的惡意 ML 提供者
說明
惡意供應商會呈現植入後門的演算法,其中私人訓練數據將被復原。 鑒於模型本身,他們能夠重建臉部和文字。
傳統類似物
目標資訊洩漏
緩解措施
示範此攻擊可行性的研究論文表明同型加密是有效的緩和措施。 這是Microsoft目前投資很少的領域,AETHER 安全性工程建議在此空間進行研究投資來建置專業知識。 這項研究需要列舉同型加密原則,並評估其實際有效性作為面對惡意 ML 即服務提供者的風險降低措施。
嚴重程度
如果數據是 PII,則為重要,否則為中度
#9 攻擊 ML 供應鏈
說明
由於需要大量資源(數據 + 計算)來定型演算法,目前的做法是重複使用由大型公司訓練的模型,並稍微針對手邊的工作修改模型(例如:ResNet 是來自Microsoft的熱門影像辨識模型)。 這些模型是在模型動物園中策劃的(Caffe 裝載熱門影像辨識模型)。 在這次攻擊中,對手攻擊卡菲裝載的模型,從而毒害了其他人的井。 [1]
傳統類似物
第三方非安全性依賴的妥協
App Store 不知情地裝載惡意代碼
緩解措施
盡可能將模型和數據的第三方相依性降至最低。
將這些相依性併入威脅模型化程式。
利用強身份驗證、存取控制和加密來連接第一方和第三方系統。
嚴重程度
危急
#10 後門機器學習
說明
定型程式會外包給惡意第三方,該方會竄改訓練數據,並傳遞特洛伊木馬模型,以強制目標分類錯誤分類,例如將特定病毒分類為非惡意[1]。 這是 ML 即服務模型產生案例的風險。
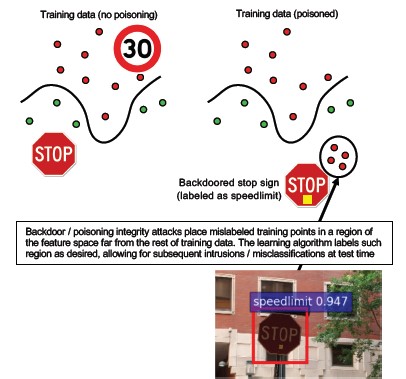 [12]
[12]
傳統類似物
第三方安全依賴的妥協
遭入侵的軟體更新機制
證書頒發機構單位遭入侵
緩解措施
反應式/防禦性偵測動作
- 一旦發現此威脅,即已造成損害,因此無法信任惡意提供者所提供的模型和任何定型數據。
主動/防護動作
在內部訓練所有敏感性模型
整理訓練數據,或確保數據來自採取強有力安全措施的可靠第三方。
建立威脅模型以評估 MLaaS 提供者與您自己系統之間的互動
回應動作
- 與外部依賴的安全漏洞相同
嚴重程度
危急
#11 利用機器學習系統的軟體依賴性
說明
在此攻擊中,攻擊者不會操控演算法。 相反地,利用軟體弱點,例如緩衝區溢出或跨站腳本[1]。 相較於直接攻擊學習層,AI/ML 下方的軟體層仍然更容易入侵,因此安全性開發生命週期中詳述的傳統安全性威脅風險降低做法至關重要。
傳統類似物
遭入侵的開放原始碼軟體依賴性
網頁伺服器弱點(XSS、CSRF、API 輸入驗證失敗)
緩解措施
請與您的安全性小組合作,遵循適用的安全性開發週期/作業安全性保證最佳做法。
嚴重程度
根據傳統軟體弱點的類型,變動性大,可能達到關鍵性。
參考書目
[1] 機器學習中的失敗模式、Ram Shankar Siva Kumar、David O'Brien、Kendra Albert、Salome Viljoen 和 Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER 安全工程工作流程,數據來源/傳承虛擬團隊
[3] 深度學習中的對抗範例:特徵與差異、魏等 https://arxiv.org/pdf/1807.00051.pdf
[4] ML漏洞:對機器學習模型的模型獨立和數據獨立成員資格推斷攻擊及防禦,Salem 等 https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson、S. Jha 和 T. Ristenpart,“利用置信度資訊和基本對策的模型反轉攻擊”,發表於 2015 年 ACM SIGSAC 計算機與通信安全會議(CCS)中。
[6] Nicolas Papernot & Patrick McDaniel- Machine Learning AIWTB 2017 中的對抗範例
[7] 透過預測 API 竊取機器學習模型, Florian Tramèr,洛桑聯邦理工學院(EPFL);張範,康奈爾大學;Ari Juels,康奈爾科技;Michael K. Reiter,北卡羅來納大學教堂山;湯瑪斯·里斯滕巴特,康奈爾科技
[8] 可轉移對抗範例的空間,弗洛裡安·特拉梅爾,尼古拉斯·帕諾特,伊恩·古德費爾洛,丹·博尼赫和派翠克·麥克達尼爾
[9] 瞭解 Well-Generalized 學習模型上的會籍推斷 Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 , 和 Kai Chen3,4
[10] Simon-Gabriel 等,神經網路的對抗弱點隨著輸入維度的增加而提升,ArXiv 2018;
[11] Lyu et al., 對抗範例的統一漸層正規化系列,ICDM 2015
[12] 野生模式:對抗機器學習崛起十年後 - NeCS 2019 巴蒂斯塔·比吉奧亞,法比奧·羅利
[13] 使用單調分類法的對抗性強健惡意程式檢測 Inigo Incer 等。
[14] 巴蒂斯塔·比吉奧、伊吉諾·科羅納、喬治·福梅拉、喬治·賈辛托和法比奧·羅利。 在對抗性分類任務中應用集成方法抵禦中毒攻擊的分類器
[15] 改進對負面影響防禦的拒絕策略,李洪江和陳柏智
[16] Adler。 生物特徵辨識加密系統中的弱點。 第 5 屆國際會議 AVBPA, 2005
[17] Galbally、McCool、Fierrez、Marcel、Ortega-Garcia。 臉部驗證系統對於爬山攻擊的脆弱性。 派特 Rec., 2010
[18] 魏林徐,大衛·埃文斯,嚴軍齊。 特徵擠壓:偵測深度類神經網路中的對立範例。 2018 網路和分散式系統安全性研討會。 2月18-21日。
[19] 使用對抗訓練引起的模型信賴增強對立強固性 - 習吳、吳英、潔峰陳、凌焦陳、薩薩什·賈
[20] 偵測對立範例的屬性驅動因果分析、Susmit Jha、Sunny Raj、Steven Fernandes、Sumit Kumar Jha、Somesh Jha、Gunjan Verma、Brian Jalaian、Ananthram Swami
[21] 針對訓練數據中毒的強固線性回歸 – 劉暢等。
[22] 改善對抗性穩健性的特徵去噪,Cihang Xie,Yuxin Wu,Laurens van der Maaten,Alan Yuille,Kaiming He
[23] 針對對抗範例的認證防禦 - 阿迪蒂·拉古納森,雅各·斯坦哈特,珀西·梁