使用 SQL Server 巨量資料叢集部署的資源
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本文描述 SQL Server 巨量資料叢集所部署的資源。
巨量資料叢集會根據部署設定檔來部署 Pod。 如需詳細資料,請參閱預設組態。
本文描述以 aks-dev-test-ha 設定檔部署的 Pod,並包含 Spark 集區。 查詢 Kubernetes 以查看部署在叢集中的 Pod。 下列範例會傳回特定命名空間下的 Pod 清單。
kubectl get pods -n <namespace>
將 <namespace> 替換為您的巨量資料叢集名稱。
如需詳細資訊,請參閱如何在 Kubernetes 上部署 SQL Server 巨量資料叢集。
下圖顯示部署在巨量資料叢集中的元件:
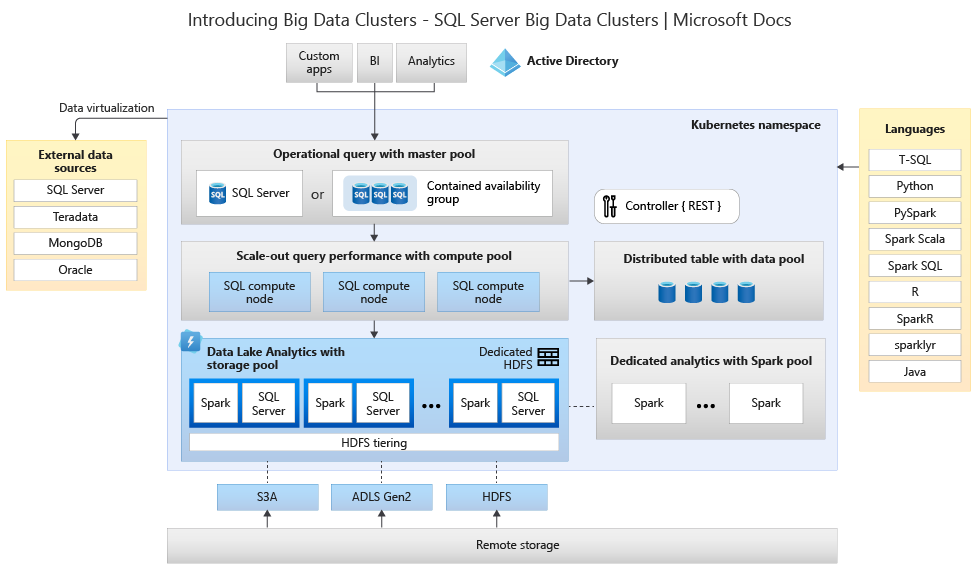
如需架構的相關資訊,請參閱 SQL Server 巨量資料叢集簡介。
部署的 Pod
下表列出部署在巨量資料叢集中的 Pod。
| 名稱 | 區域 |
|---|---|
control-<nnnn> |
控制 |
controldb-<#> |
控制 |
controlwd-<nnnn> |
控制 |
logsdb-<#> |
控制 |
logsui-<nnnn> |
控制 |
metricsdb-<#> |
控制 |
metricsdc-<nnnn> |
控制 |
metricsui-<nnnn> |
控制 |
mgmtproxy-<nnnn> |
控制 |
zookeeper-<#> |
控制 |
dns-<nnnn> |
控制 |
master-<#n> |
主要執行個體 |
operator-<nnnn> |
主要執行個體 |
compute-<#n>-<#m> |
計算集區 |
data-<#>-<#> |
資料集區 |
storage-<#>-<#> |
存放集區 |
nmnode-<#>-<#> |
存放集區 |
sparkhead-<#> |
存放集區 |
appproxy-<#m> |
應用程式集區 |
gateway-<#> |
閘道器服務 |
並非每個巨量資料叢集中都會包含所有的 Pod。 高可用性部署或 Active Directory 整合會包含特定的 Pod。
高可用性特定的 Pod:
operator-<nnnn>zookeeper-<#>
Active Directory 特定的 Pod:
dns-<nnnn>
下列各節描述這些 Pod,並列出每個 Pod 中的容器。
控制
控制 Pod 提供控制服務。
| Pod 名稱 | Count | Kubernetes 控制器類型 | 容器 |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
每個 Kubernetes 節點 1 個。 | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 或 1 (如需 Active Directory 整合) | ReplicaSet | - dns- fluentbit |
主要執行個體
master-<#n> 是 SQL Server 主要執行個體。
- 透過 DDL 管理資料集區
- 透過 DML 操作資料集區中的資料
- 將分析查詢執行卸載到資料集區
| Pod 名稱 | Count | Kubernetes 控制器類型 | 容器 |
|---|---|---|---|
master-<#n> |
1 或更多 (如需高可用性)。 | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 或 1 (如需高可用性) | ReplicaSet | - mssql-ha-operator |
* 僅限高可用性部署。 此運算子會實作及註冊 SQL Server 和可用性群組資源的自訂資源定義。 此運算子會在部署後自動註冊為接聽項,以在 Kubernetes 叢集中要部署 SQL Server 資源時收到通知。 mssql-ha-supervisor 支援可用性群組。
每個 master Pod 都會包含一個 SQL Server 執行個體。 高可用性部署包含 3 個 Pod。 每個 Pod 都會包含一個 SQL Server 執行個體,其中具有 SQL Server Always On 可用性群組中的所有資料庫。
視工作負載而定,在部署時會包含其他 Pod。
計算集區
計算集區提供用於計算的 SQL Server 執行個體。
| Pod 名稱 | Count | Kubernetes 控制器類型 | 容器 |
|---|---|---|---|
compute-<#n>-<#m> |
1 或更多。 | StatefulSet | - mssql-server- fluentbit- collectd |
#n會識別計算集區。#m會識別集區內的執行個體識別碼。
計算集區 SQL Server 執行個體為無狀態。 只需要 tempdb 的儲存空間。
視工作負載而定,在部署時會包含其他 Pod。
資料集區
資料集區提供用於儲存和計算的 SQL Server 執行個體。
| Pod 名稱 | Count | Kubernetes 控制器類型 | 容器 |
|---|---|---|---|
data-<#n>-<#m> |
0 或更多 | StatefulSet | - mssql-server - fluentbit- collectd |
#n會識別資料集區。#m會識別集區內的執行個體識別碼。
視工作負載而定,在部署時會包含其他 Pod。
儲存體集區
存放集區可供透過 Spark 進行資料擷取、在 HDFS 中儲存,以及透過 HDFS 和 SQL Server 端點進行資料存取。
| Pod 名稱 | Count | Kubernetes 控制器類型 | 容器 |
|---|---|---|---|
storage-0-# |
1 或更多。 視工作負載而定,在部署時會包含其他 Pod。 | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 或更多 (如需高可用性) | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 或更多 (如需高可用性) | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 或 3 (如需高可用性)。 | StatefulSet | - zookeeper- fluentbit |
應用程式集區
部分測試組態設定檔中包含應用程式集區。 應用程式集區會裝載在部署巨量資料叢集的應用程式時所定義應用程式服務 Proxy。
appproxy 是位於應用程式集區應用程式前方的 Web API。 其會驗證使用者,然後將要求路由傳送至應用程式。
| Pod 名稱 | Kubernetes 控制器類型 | 容器 |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
如需詳細資訊,請參閱巨量資料叢集上的應用程式部署簡介。
視工作負載而定,在部署時會包含其他 Pod。
閘道器服務
閘道服務為 Spark、HDFS、Yarn、Yarn UI 和 Spark UI 提供 Knox 閘道。
| Pod 名稱 | Kubernetes 控制器類型 | 容器 |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
僅支援一個閘道。
開放原始碼容器參考
如需特定開放原始碼專案和版本,請參閱開放原始碼軟體參考。
下一步
若要深入了解 SQL Server 巨量資料叢集,請參閱下列資源:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應