SQL Server 巨量資料叢集中的計算集區簡介
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
此文章說明 SQL Server 巨量資料叢集中「SQL Server 計算集區」的角色。 計算集區為 SQL Server 巨量資料叢集提供向外延展的計算資源。 其可用來卸載 SQL Server 主要執行個體的計算工作或中繼結果集。 以下各節會描述計算集區的架構、功能和使用案例。
您也可以觀看這段 5 分鐘的影片,以取得計算集區簡介:
計算集區架構
計算集區是由在 Kubernetes 中執行的一或多個計算 Pod 所組成。 這些 Pod 的自動建立和管理是由 SQL Server 主要執行個體進行協調。 每個 Pod 會包含一組基本服務和一個 SQL Server 資料庫引擎執行個體。
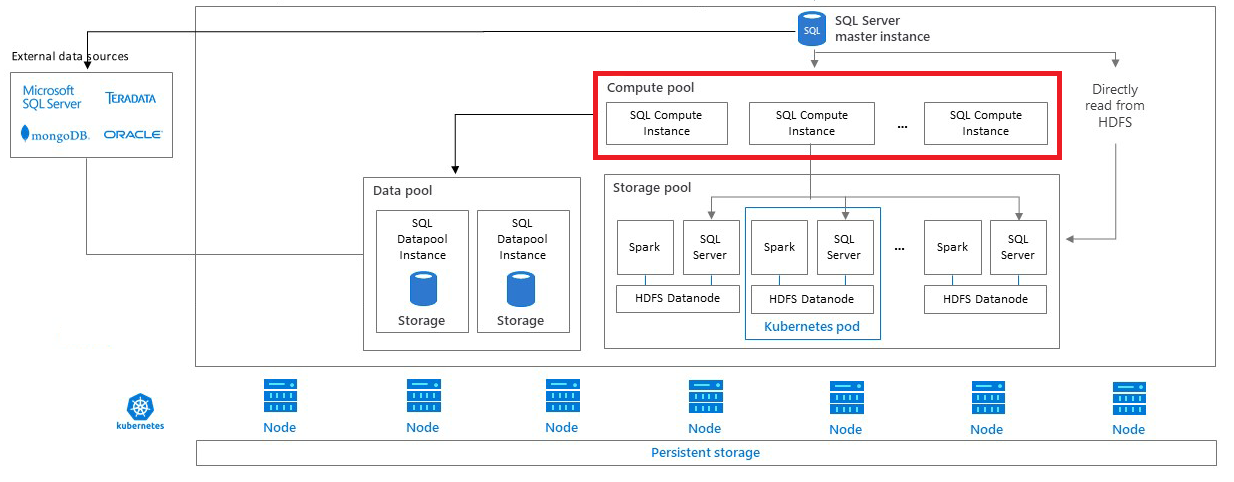
向外延展群組
計算集區可作為 PolyBase 向外延展群組,以便在不同的外部資料來源 (例如 SQL Server、Oracle、MongoDB、Teradata 和 HDFS) 上進行分散式查詢。 使用 Kubernetes 中的計算 Pod,SQL Server 巨量資料叢集可將為 PolyBase 向外延展群組建立和設定計算 Pod 的流程自動化。
計算集區案例
使用計算集區的案例包括:
當查詢提交至主要執行個體時,使用位於存放集區中的一或多個資料表。
當查詢提交至主要執行個體時,使用位於資料集區中具有循環配置資源散發的一或多個資料表。
提交至主要執行個體的查詢,使用具有 SQL Server、Oracle、MongoDB 和 Teradata 外部資料來源的資料分割資料表時。 本案例必須啟用查詢提示 OPTION (FORCE SCALEOUTEXECUTION)。
當查詢提交至主要執行個體時,使用位於 HDFS 階層處理中的一或多個資料表。
不使用計算集區的案例包括:
提交至主要執行個體的查詢,使用外部 Hadoop HDFS 叢集中的一或多個資料表時。
提交至主要執行個體的查詢,使用 Azure Blob 儲存體中的一或多個資料表時。
提交至主要執行個體的查詢,使用具有 SQL Server、Oracle、MongoDB 和 Teradata 外部資料來源的非資料分割資料表時。
啟用查詢提示 OPTION (DISABLE SCALEOUTEXECUTION) 時。
提交至主要執行個體的查詢,套用至主要執行個體的資料庫時。
後續步驟
若要深入了解 SQL Server 巨量資料叢集,請參閱下列資源: