在多部電腦上設定 Kubernetes 以進行 SQL Server 巨量資料叢集部署
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本文提供範例說明如何使用 kubeadm 來設定多部電腦上的 Kubernetes,以進行 SQL Server 巨量資料叢集部署。 在此範例中,會以多部 Ubuntu 16.04 或 18.04 LTS 電腦 (實體或虛擬) 為目標。 如果您要部署到不同的 Linux 平台,您必須改變一些命令以符合您的系統。
提示
如需設定 Kubernetes 的範例指令碼,請參閱在 Ubuntu 20.04 LTS 上使用 Kubeadm 建立 Kubernetes 叢集 (英文)。
如需在 VM 上自動部署單一節點 kubeadm 部署,然後在其中部署巨量資料叢集之預設組態的範例指令碼,請參閱部署單一節點 kubeadm 叢集。
必要條件
- 至少三部 Linux 實體機器或虛擬機器
- 每部電腦的建議設定:
- 8 個 CPU
- 64 GB 的記憶體
- 100 GB 的儲存空間
重要
在開始進行巨量資料叢集部署之前,請先確定作為部署目標的所有 Kubernetes 節點上時鐘已同步。 巨量資料叢集針對仰賴正確時間的各項服務具有內建健全狀況屬性,而時鐘誤差可能會導致狀態不正確。
準備電腦
每部電腦都有幾個必要條件。 在每部電腦上的 Bash 終端機執行下列命令:
將目前的電腦新增至
/etc/hosts檔案:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hosts停用所有裝置上的交換。
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -a匯入金鑰並註冊 Kubernetes 的存放庫。
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.list在電腦上設定 Docker 和 Kubernetes 必要條件。
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bash設定
net.bridge.bridge-nf-call-iptables=1。 在 Ubuntu 18.04 上,下列命令會先啟用br_netfilter。. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
設定 Kubernetes 主機
在每部電腦上執行上述命令之後,請選擇其中一部電腦作為您的 Kubernetes 主機。 然後在該電腦上執行下列命令。
首先,使用下列命令在您目前的目錄中建立 rbac.yaml 檔案。
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOF初始化這部電腦上的 Kubernetes 主機。 下面的範例指令碼指定 Kubernetes 版本
1.15.0。 您使用的版本取決於您的 Kubernetes 叢集。KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSION您應該會看到 Kubernetes 主機已成功初始化的輸出。
請注意
kubeadm join命令,您需要將其用來在其他伺服器上聯結 Kubernetes 叢集。 複製此命令以供稍後使用。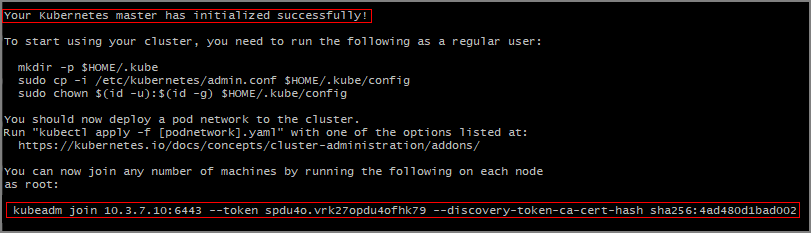
在您的主目錄中設定 Kubernetes 設定檔。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config設定叢集和 Kubernetes 儀表板。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
設定 Kubernetes 代理程式
其他機器將會用作叢集中的 Kubernetes 代理程式。
在其他每部電腦上執行您在上一節中複製的 kubeadm join 命令。

檢視叢集狀態
若要驗證針對您叢集的連線,請使用 kubectl get 命令來傳回叢集節點的清單。
kubectl get nodes
後續步驟
本文中的步驟已在多部 Ubuntu 電腦上設定 Kubernetes 叢集。 下一個步驟是部署 SQL Server 2019 巨量資料叢集。 如需指示,請參閱下列文章: