在高可用性設定中部署 HDFS 名稱節點和共用 Spark 服務
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
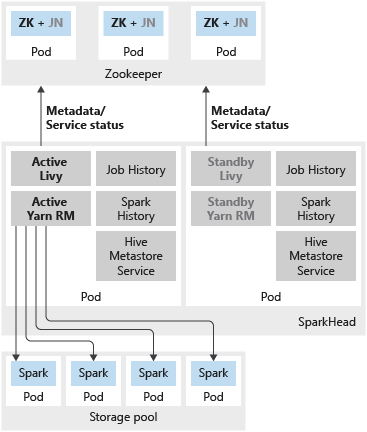
除了使用可用性群組在高可用性設定中部署 SQL Server 主要執行個體以外,您還可以在巨量資料叢集中部署其他任務關鍵性服務,以確保有更高的可靠性。 您可以設定 HDFS name node 及為分組到 sparkhead 下的共用 Spark 服務設定一個額外複本。 在此情況下,也會在巨量資料叢集中部署 Zookeeper,作為下列服務的叢集協調器和中繼資料存放區:
- HDFS 名稱節點
- Livy 和 Yarn Resource Manager。
Spark 記錄、作業記錄和 Hive 中繼資料服務都是無狀態服務。 Zookeeper 與確保這些元件的服務健全狀態無關。
針對這些服務部署多個複本可增強可用複本之間工作負載的延展性、可靠性和負載平衡。
注意
下列服務會部署為 sparkhead Pod 中的容器:
- Livy
- Yarn Resource Manager
- Spark 記錄
- 作業記錄
- Hive 中繼資料服務
下圖顯示 SQL Server 巨量資料叢集中的 Spark HA 部署:
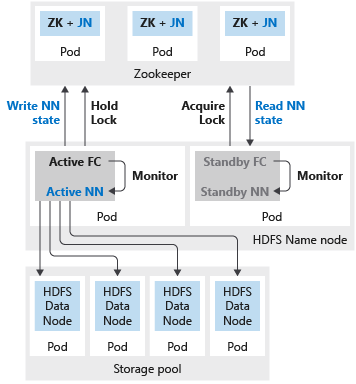
下圖顯示 SQL Server 巨量資料叢集中的 HDFS HA 部署:
部署
如果為名稱節點或 sparkhead 設定兩個複本,則您也必須為 Zookeeper 資源設定三個複本。 在 HDFS 名稱節點的高可用性設定中,會由兩個 Pod 裝載兩個複本。 這兩個 Pod 分別為 nmnode-0 和 nmnode-1。 此設定為主動-被動。 一次只能有一個主動的名稱節點。 另一個節點會處於待命狀態,並在發生容錯移轉事件之後變成主動。
您可以使用 aks-dev-test-ha 或 kubeadm-prod 內建組態設定檔來開始自訂您的巨量資料叢集部署。 這些設定檔包含為資源設定額外高可用性時所需的設定。 例如,以下是 bdc.json 設定檔中與部署高可用性 HDFS 名稱節點、Zookeeper 和共用 Spark 資源 (sparkhead) 相關的區段。
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
基於最佳做法,您也必須在生產環境部署中,將 HDFS 區塊複寫設定為 3。 aks-dev-test-ha 和 kubeadm-prod 設定檔中已指定此設定。 請參閱 bdc.json 設定檔中的以下區段:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
已知限制
在 SQL Server 巨量資料叢集中設定 Hadoop 服務高可用性時的已知問題和限制包括:
- 所有設定都必須在巨量資料叢集部署時指定。 在 SQL Server 2019 CU1 版本中,您無法在部署後啟用高可用性設定。
下一步
- 如需在巨量資料叢集部署中使用設定檔的詳細資訊,請參閱如何在 Kubernetes 上部署 SQL Server 巨量資料叢集。
- 如需巨量資料叢集中 SQL Server 主要高可用性選項的詳細資訊,請參閱部署高可用性 SQL Server 主要執行個體主題。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應