在 Azure Data Studio 中於 SQL Server 巨量資料叢集上提交 Spark 作業
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
巨量資料叢集的其中一個主要案例,是可讓您提交適用於 SQL Server 的 Spark 作業。 Spark 作業提交功能可讓您提交參考 SQL Server 2019 巨量資料叢集的本機 Jar 或 Py 檔案。 也可讓您執行已位於 HDFS 檔案系統中的 Jar 或 Py 檔案。
Prerequisites
-
- Azure Data Studio
- SQL Server 2019 延伸模組
- kubectl
開啟 Spark 作業提交對話方塊
有數種方式可開啟 Spark 作業提交對話方塊。 包括儀表板、[物件總管] 中的操作功能表以及命令選擇區等等。
若要開啟 Spark 作業提交對話方塊,請按一下儀表板中的 [新增 Spark 作業]。
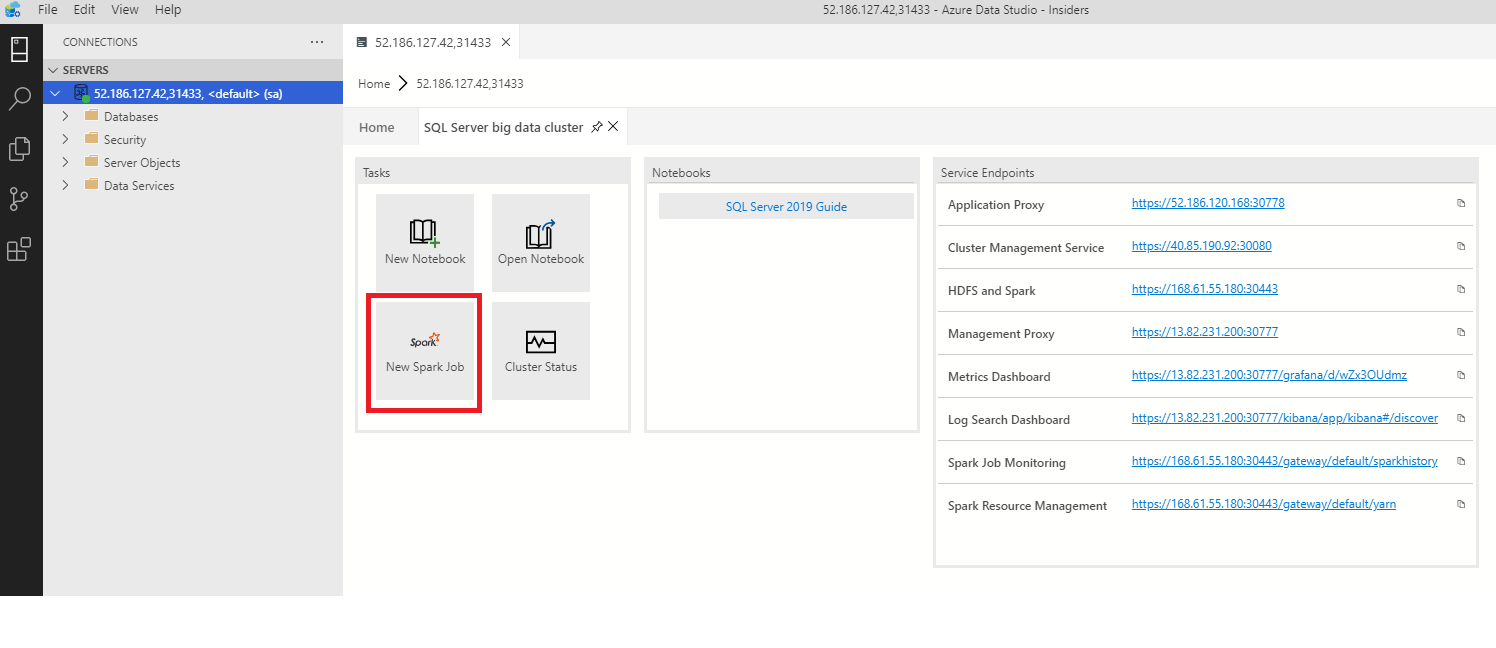
或以滑鼠右鍵按一下 [物件總管] 中的叢集,然後從操作功能表中選取 [提交 Spark 作業]。
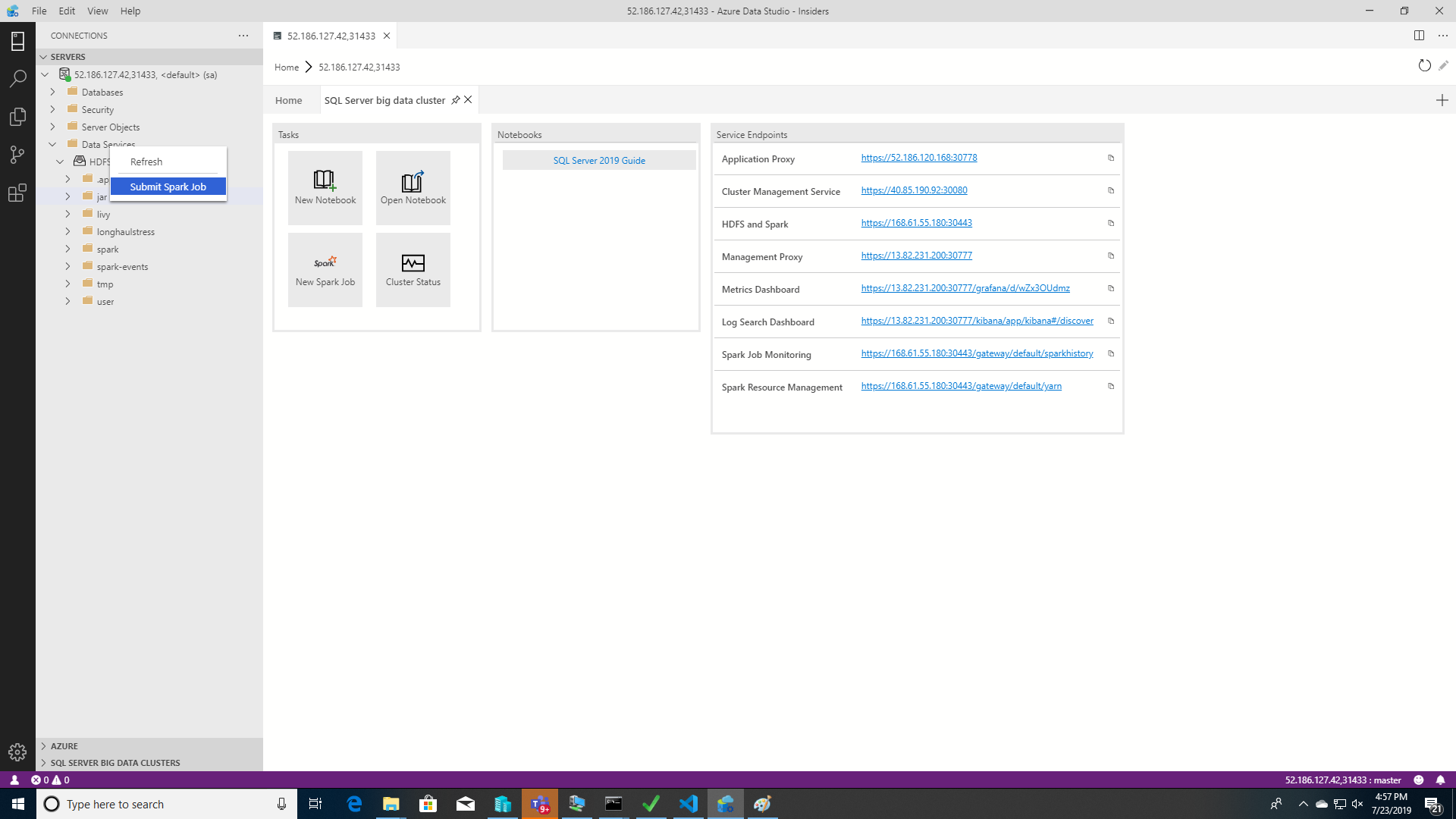
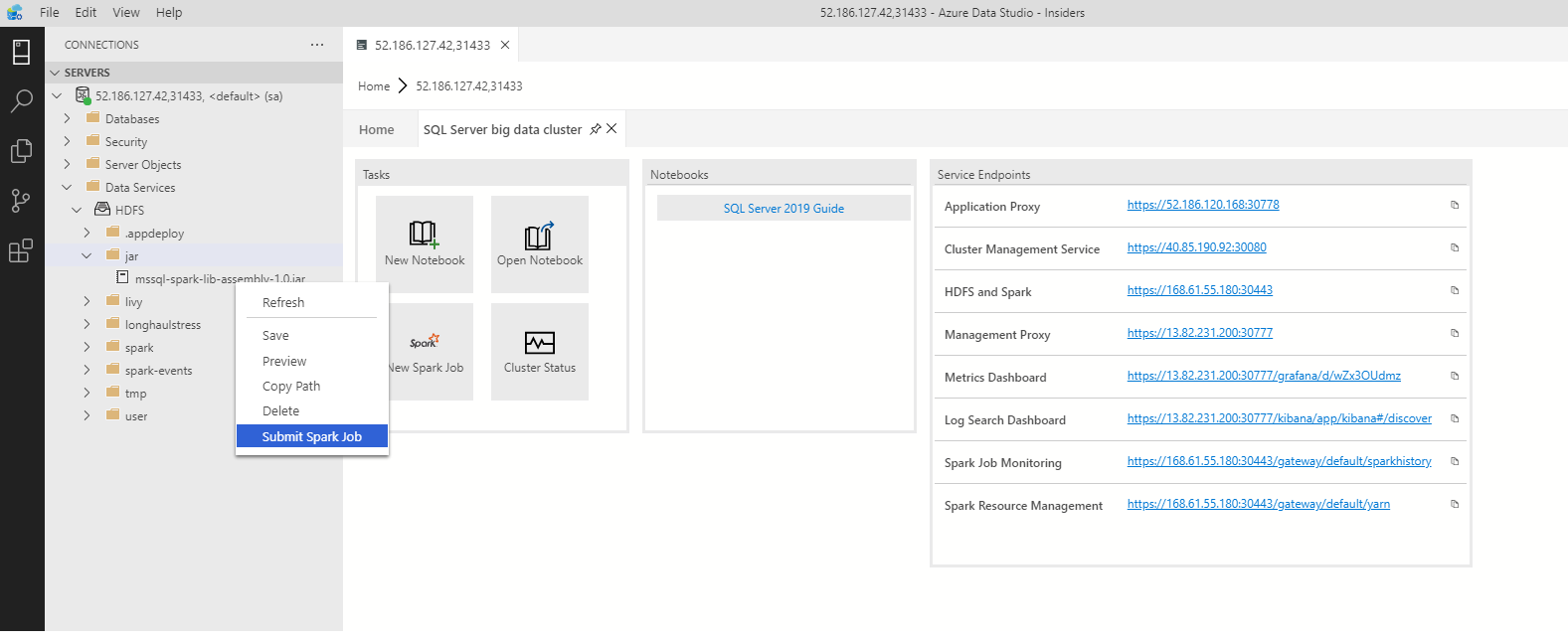
若要開啟已預先填入 Jar/Py 欄位的 Spark 作業提交對話方塊,請以滑鼠右鍵按一下 [物件總管中] 的 Jar/Py 檔案,然後從操作功能表中選取 [提交 Spark 作業]。
在命令選擇區中鍵入 Ctrl+Shift+P (Windows) 或 Cmd+Shift+P (Mac) 以使用 [提交 Spark 作業]。

提交 Spark 作業
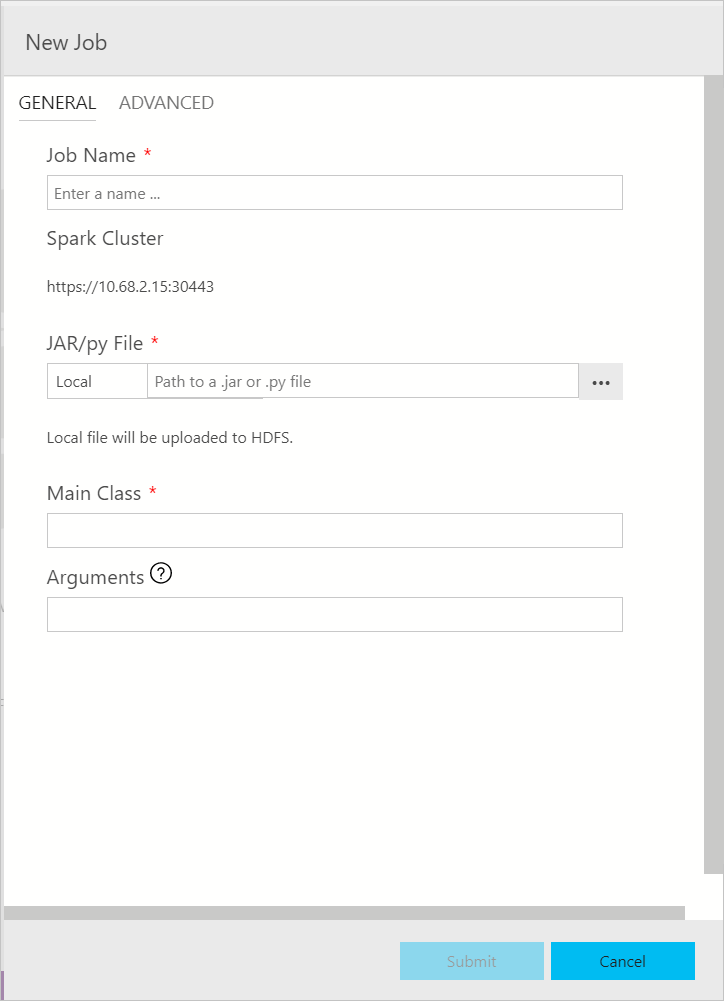
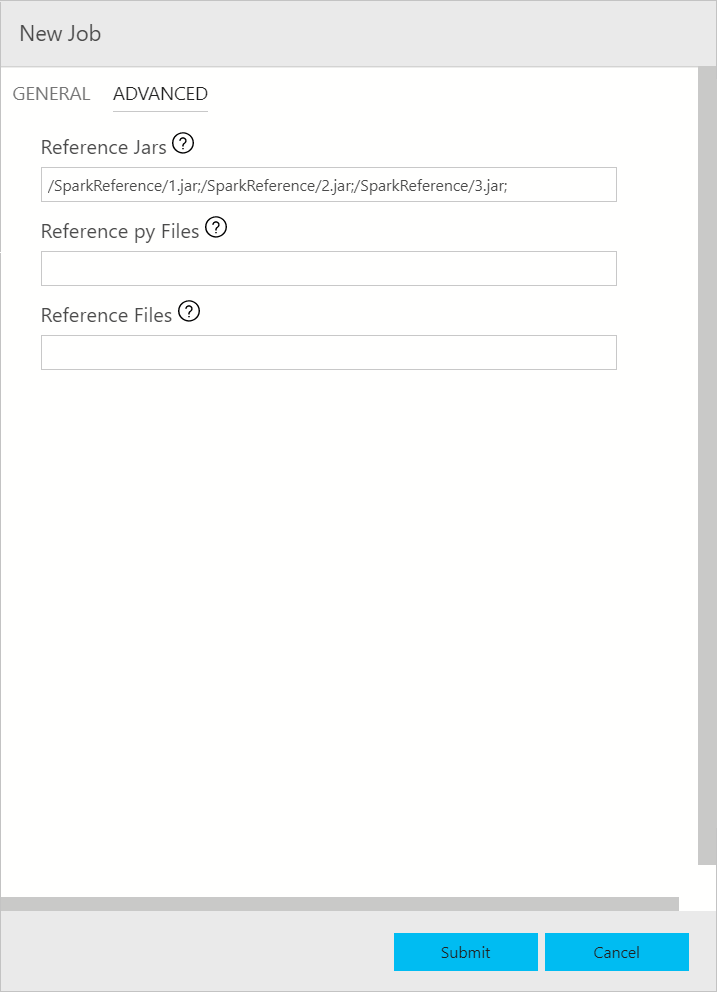
Spark 作業提交對話方塊會顯示如下。 輸入作業名稱、JAR/Py 檔案路徑、主要類別和其他欄位。 Jar/Py 檔案來源可能來自本機或 HDFS。 如果 Spark 作業具有參考 Jar、Py 檔案或其他檔案,請按一下 [進階] 索引標籤,然後輸入對應的檔案路徑。 按一下 [提交] 以提交 Spark 作業。
監視 Spark 作業提交
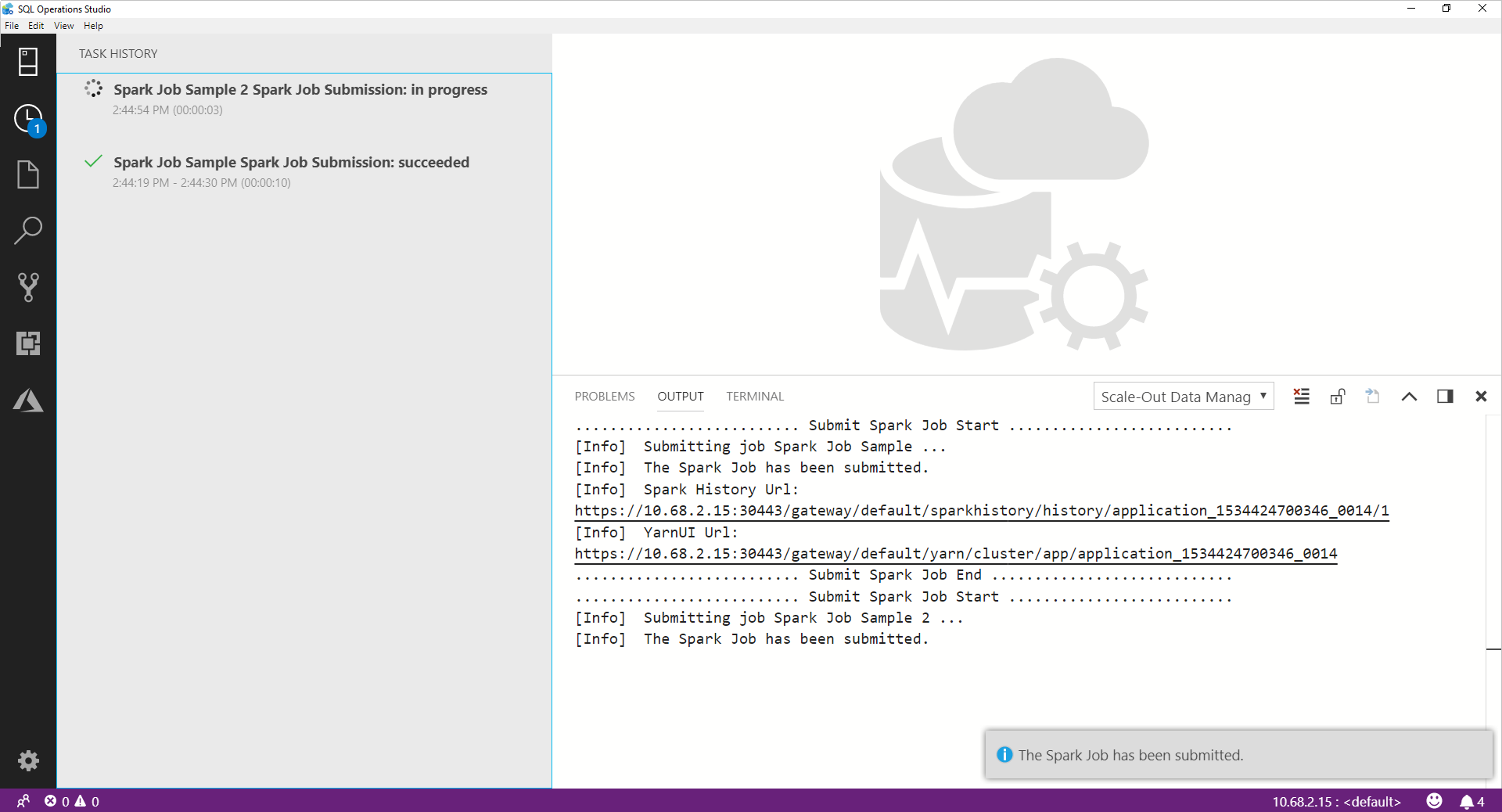
在提交 Spark 作業之後,Spark 作業提交和執行狀態資訊即會顯示在左側的 [工作歷程記錄] 中。 進度和記錄的詳細資料,也會顯示於下方的 [輸出] 視窗中。
當 Spark 作業正在進行時,[工作歷程記錄] 面板和 [輸出] 視窗會重新整理進度。
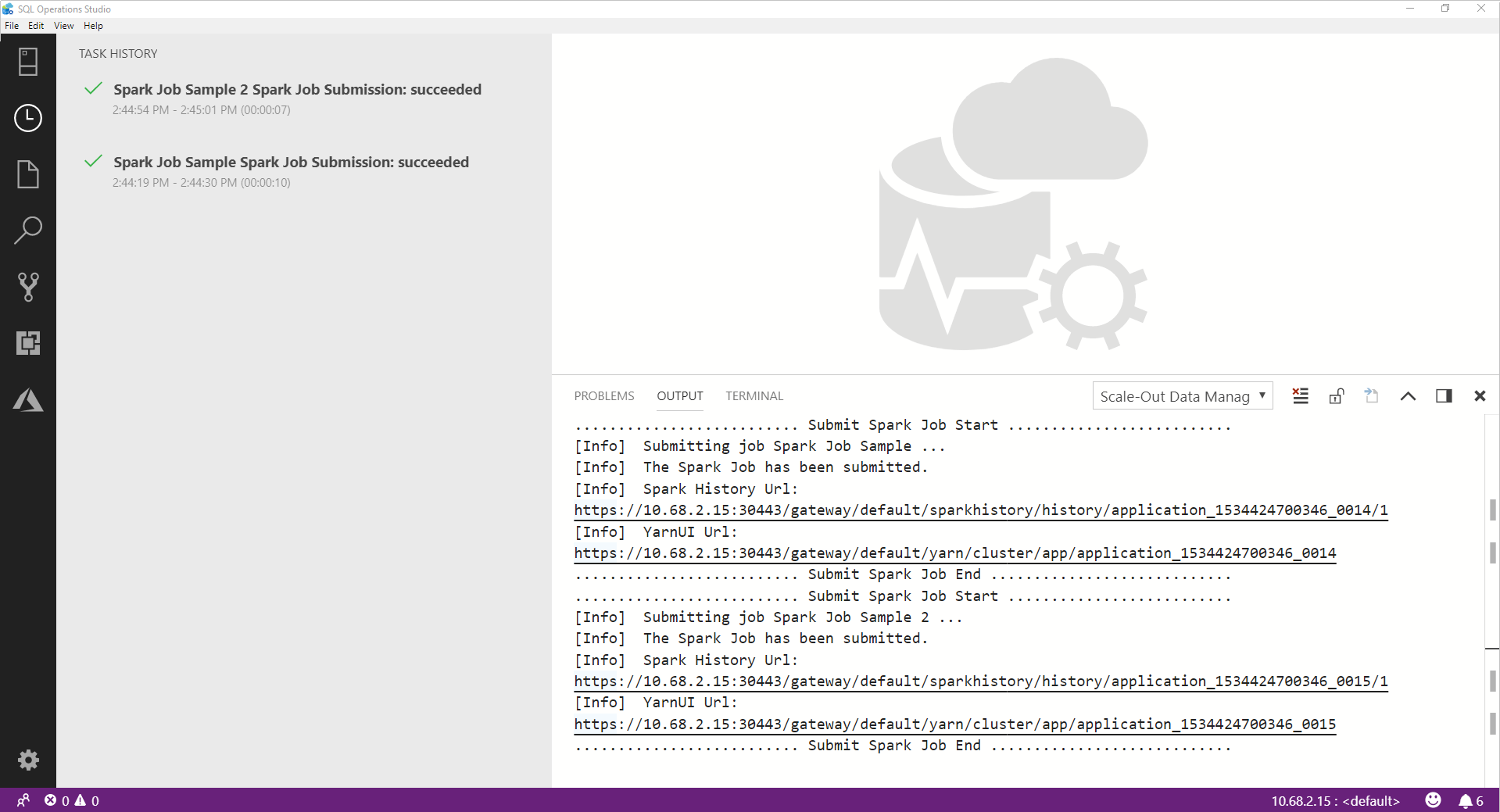
當 Spark 作業順利完成時,Spark UI 和 Yarn UI 連結會出現在 [輸出] 視窗中。 如需詳細資訊,請按一下連結。
下一步
如需 SQL Server 巨量資料叢集和相關案例的詳細資訊,請參閱 SQL Server 巨量資料叢集簡介。