針對 pyspark 筆記本進行疑難排解
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本文示範如何針對失敗的 pyspark 筆記本進行疑難排解。
Azure Data Studio 下的 PySpark 作業架構
Azure Data Studio 與 SQL Server 巨量資料叢集上的 livy 端點通訊。
livy 端點會在巨量資料叢集中發出 spark-submit 命令。 每個 spark-submit 命令都有一個參數,其可將 YARN 指定為叢集資源管理員。
若要有效率地針對 PySpark 工作階段進行疑難排解,則必須收集及檢閱每一層中的記錄:Livy、YARN 與 Spark。
此疑難排解步驟需要具備:
- Azure Data CLI (
azdata) 已安裝,且已為您的叢集正確設定組態。 - 熟悉執行 Linux 命令及一些記錄疑難排解技能。
疑難排解步驟
請檢閱
pyspark中的堆疊與錯誤訊息。從筆記本中的第一個資料格取得應用程式識別碼。 使用此應用程式識別碼來調查
livy、YARN 與 Spark 記錄。SparkContext則使用此 YARN 應用程式識別碼。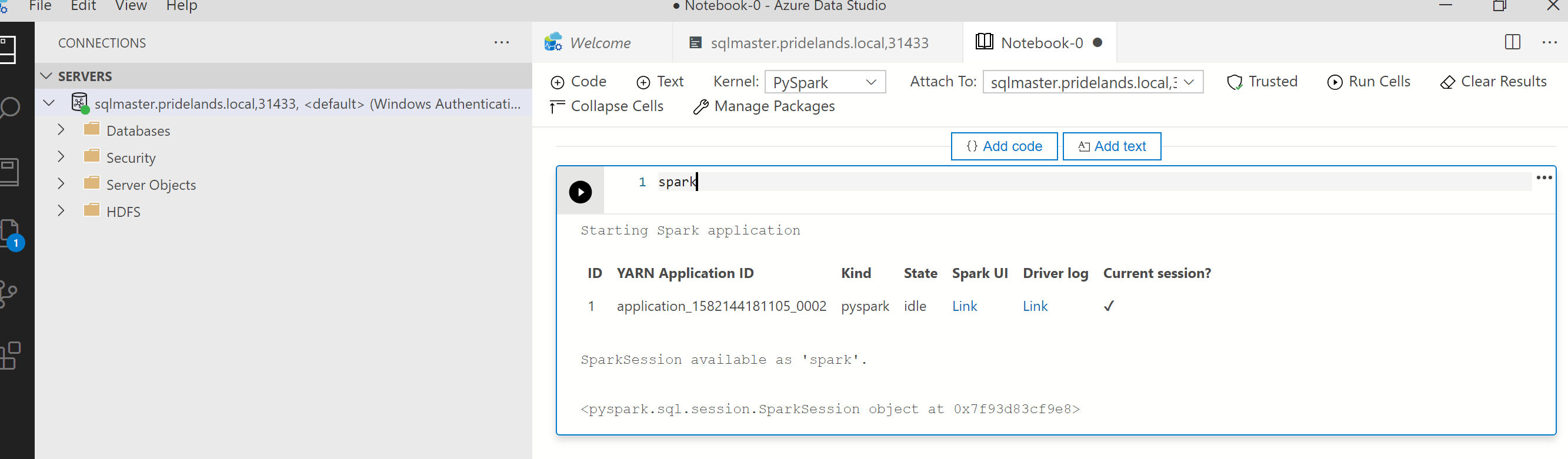
取得記錄。
使用
azdata bdc debug copy-logs調查下列範例會連線巨量資料叢集端點,以複製記錄。 在執行之前,請先更新下列範例中的值。
<ip_address>:巨量資料叢集端點<username>:巨量資料叢集名稱<namespace>:叢集的 Kubernetes 命名空間<folder_to_copy_logs>:您想要將記錄複製到其中的本機資料夾路徑
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>範例輸出
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.檢閱 Livy 記錄。 Livy 記錄在
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log。- 從 pyspark 筆記本的第一個儲存格搜尋 YARN 應用程式識別碼。
- 搜尋
ERR狀態。
具有
YARN ACCEPTED狀態的 Livy 記錄範例。 Livy 已提交 Yarn 應用程式。HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>檢閱 Yarn UI
從 Azure Data Studio 巨量資料叢集管理儀表板取得 YARN 端點 URL,或執行
azdata bdc endpoint list –o table。例如:
azdata bdc endpoint list -o table傳回值
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy https檢查應用程式識別碼與個別 application_master 與容器記錄。
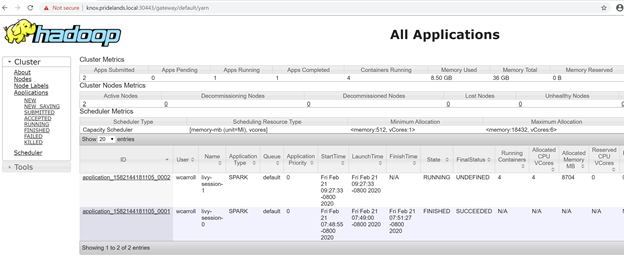
檢閱 YARN 應用程式記錄檔。
取得應用程式的應用程式記錄檔。 使用
kubectl連線至sparkhead-0Pod,例如:kubectl exec -it sparkhead-0 -- /bin/bash然後使用正確的
application_id,在該殼層中執行此命令:yarn logs -applicationId application_<application_id>搜尋錯誤或堆疊。
HDFS 的權限錯誤範例。 在 Java 堆疊中,尋找
Caused by:YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x檢閱 SPARK UI。
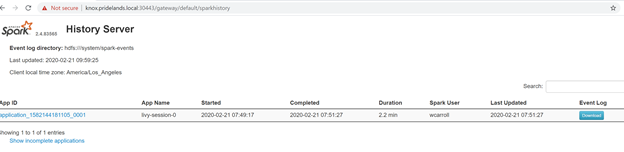
向下鑽研至尋找錯誤的階段工作。
後續步驟
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應