適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
這很重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本教學課程示範如何在 SQL Server 2019 巨量數據叢集中查詢 HDFS 數據。
在本教學課程中,您將瞭解如何:
- 建立指向巨量數據叢集中 HDFS 數據的外部數據表。
- 將此數據與主要實例中的高價值數據聯結。
小提示
如果您想要的話,您可以下載並執行本教學課程中命令的腳本。 如需指示,請參閱 GitHub 上的 數據虛擬化範例 。
這段 7 分鐘的影片會逐步引導您查詢巨量資料叢集中的 HDFS 資料:
先決條件
-
巨量資料工具
- kubectl
- Azure Data Studio
- SQL Server 2019 擴充功能
- 將範例數據載入巨量數據叢集
建立 HDFS 的外部數據表
存放集區包含儲存在 HDFS 中的 CSV 檔案中的 Web 點擊流數據。 使用下列步驟來定義外部數據表,以存取該檔案中的數據。
在 Azure Data Studio 中,連線到巨量數據叢集的 SQL Server 主要實例。 如需詳細資訊,請參閱 連線到 SQL Server 主要實例。
按兩下 [ 伺服器 ] 視窗中的連線,以顯示 SQL Server 主要實例的伺服器儀錶板。 選取 [新增查詢]。
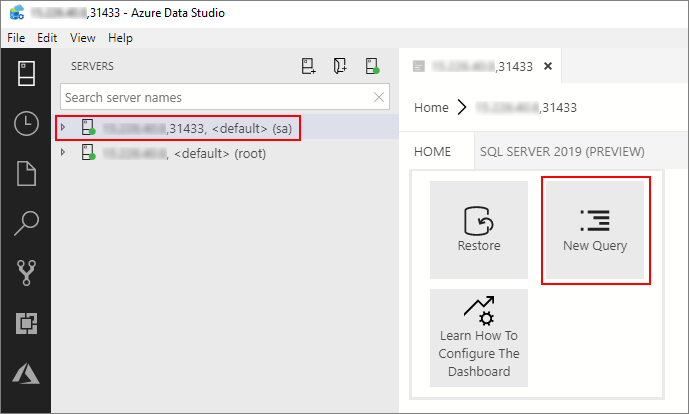
執行下列 Transact-SQL 命令,將內容變更為主要實例中的 Sales 資料庫。
USE Sales GO定義要從 HDFS 讀取的 CSV 檔案格式。 按一下 F5 鍵 執行敘述。
CREATE EXTERNAL FILE FORMAT csv_file WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2, USE_TYPE_DEFAULT = TRUE) );如果尚未存在,請建立存放集區的外部數據源。
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool') BEGIN CREATE EXTERNAL DATA SOURCE SqlStoragePool WITH (LOCATION = 'sqlhdfs://controller-svc/default'); END建立可從存放集區讀取
/clickstream_data的外部數據表。 SqlStoragePool 可從巨量數據叢集的主要實例存取。CREATE EXTERNAL TABLE [web_clickstreams_hdfs] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlStoragePool, LOCATION = '/clickstream_data', FILE_FORMAT = csv_file ); GO
查詢資料
執行下列查詢,將外部數據表中的 web_clickstream_hdfs HDFS 數據與本機 Sales 資料庫中的關係型數據聯結。
SELECT
wcs_user_sk,
SUM( CASE WHEN i_category = 'Books' THEN 1 ELSE 0 END) AS book_category_clicks,
SUM( CASE WHEN i_category_id = 1 THEN 1 ELSE 0 END) AS [Home & Kitchen],
SUM( CASE WHEN i_category_id = 2 THEN 1 ELSE 0 END) AS [Music],
SUM( CASE WHEN i_category_id = 3 THEN 1 ELSE 0 END) AS [Books],
SUM( CASE WHEN i_category_id = 4 THEN 1 ELSE 0 END) AS [Clothing & Accessories],
SUM( CASE WHEN i_category_id = 5 THEN 1 ELSE 0 END) AS [Electronics],
SUM( CASE WHEN i_category_id = 6 THEN 1 ELSE 0 END) AS [Tools & Home Improvement],
SUM( CASE WHEN i_category_id = 7 THEN 1 ELSE 0 END) AS [Toys & Games],
SUM( CASE WHEN i_category_id = 8 THEN 1 ELSE 0 END) AS [Movies & TV],
SUM( CASE WHEN i_category_id = 9 THEN 1 ELSE 0 END) AS [Sports & Outdoors]
FROM [dbo].[web_clickstreams_hdfs]
INNER JOIN item it ON (wcs_item_sk = i_item_sk
AND wcs_user_sk IS NOT NULL)
GROUP BY wcs_user_sk;
GO
收拾整理
使用下列命令移除本教學課程中使用的外部數據表。
DROP EXTERNAL TABLE [dbo].[web_clickstreams_hdfs];
GO
後續步驟
請前進到下一篇文章,以瞭解如何從巨量數據叢集查詢 Oracle。