適用於:![]() SQL Server 2017(14.x)及更新版本
SQL Server 2017(14.x)及更新版本
本文描述使用 SQL Server 機器學習服務來執行外部 Python 指令碼的 Python 延伸模組。 此延伸模組會新增:
- Python 執行環境
- 包含 Python 3.5 執行階段和解譯器的 Anaconda 發行版本
- 標準程式庫與工具
- Microsoft Python 套件:
- 用於大規模分析的 revoscalepy。
- 用於機器學習演算法的 microsoftml。
安裝 Python 3.5 執行階段和解譯器可確保與標準 Python 解決方案幾乎完全相容。 Python 會在與 SQL Server 不同的程序中執行,以確保資料庫作業不會受到危害。
Python 元件
SQL Server 包含開放原始碼和專屬套件。 安裝程式所安裝的 Python 執行階段是 Anaconda 4.2 與 Python 3.5。 Python 執行階段是獨立於 SQL 工具安裝的,並在擴充性架構中於核心引擎處理序外部執行。 在安裝包含 Python 的 Machine Learning 服務期間,您必須同意 GNU 公用授權的條款。
SQL Server 不會修改 Python 可執行檔,但您必須使用安裝程式所安裝的 Python 版本,因為該版本是專屬套件據以建立和測試的版本。 如需 Anaconda 發佈所支援的套件清單,請參閱 Continuum Analytics 網站:Anaconda 套件清單。
與特定資料庫引擎實例關聯的 Anaconda 發行版,可以在與該實例相關的資料夾中找到。 例如,如果您已在預設執行個體上使用 Machine Learning 服務和 Python 安裝 SQL Server 2017 資料庫引擎,請查看 C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES。
Microsoft 為平行和分散式工作負載新增的 Python 套件包含下列程式庫。
| 程式庫 | 描述 |
|---|---|
| revoscalepy | 支援資料來源物件和資料探索、操作、轉換和視覺化。 RevoScaleR 支援建立遠端計算環境,以及多種可擴展的機器學習模型,例如 rxLinMod。 如需詳細資訊,請參閱 revoscalepy 模組與 SQL Server。 |
| microsoftml | 包含已針對速度和正確性最佳化的機器學習演算法,以及適用於處理文字和影像的內嵌轉換。 如需詳細資訊,請參閱 microsoftml 模組與 SQL Server。 |
Microsoftml 和 revoscalepy 緊密結合;在 microsoftml 中使用的資料來源會定義為 revoscalepy 物件。 Revoscalepy 傳送至 microsoftml 的計算內容限制。 也就是說,所有功能都可供本機作業使用,但切換到遠端計算內容需要 RxInSqlServer。
在 SQL Server 中使用 Python
您會將 revoscalepy 模組匯入 Python 程式碼,然後從模組呼叫函式,就像任何其他 Python 函式一樣。
系統支援 ODBC 資料庫、SQL Server 和 XDF 檔案格式等資料來源,以便與其他來源或 R 解決方案交換資料。 Python 的輸入資料必須是表格式。 所有 Python 結果都必須以 pandas 資料框架的形式傳回。
支援的計算內容包括本機或遠端 SQL Server 計算內容。 遠端計算內容是指在某一部電腦 (例如工作站) 上啟動的程式碼執行,但接著將指令碼執行切換至遠端電腦的情況。 若要切換計算內容,這兩個系統都需要具備相同的 revoscalepy 程式庫。
如您所預期,本機計算環境是指在資料庫引擎實例同一台伺服器上執行的 Python 程式碼,並且這些程式碼可以是作為 T-SQL 中的一部分,或嵌入在預存程序中的。 您可以透過定義遠端計算內容,從本機 Python IDE 執行程式碼,並在 SQL Server 電腦上執行指令碼。
執行架構
下圖說明在每個支援案例中,SQL Server 元件與 Python 執行階段的互動情況:使用 SQL Server 計算內容、在資料庫中執行指令碼,以及從 Python 終端機遠端執行。
在資料庫內執行的 Python 指令碼
當執行 Python「內部」SQL Server 時,您必須將 Python 指令碼封裝在特殊的預存程序中,sp_execute_external_script。
將指令碼內嵌在預存程序中之後,任何可進行預存程序呼叫的應用程式都可以起始 Python 程式碼的執行。 之後,SQL Server 會依下圖摘要說明的方式來管理程式碼執行。
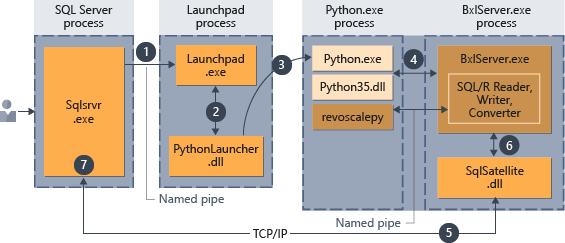
- Python 執行階段的要求是由傳遞至預存程序的
@language='Python'參數所表示。 SQL Server 會將此要求傳送到啟動控制板服務。 在 Linux 中,SQL 會使用啟動控制板服務來與每個使用者的不同啟動控制板程序通訊。 如需詳細資料,請參閱擴充性架構圖表。 - 啟動控制板服務會啟動適當的啟動器,在此案例中為 PythonLauncher。
- PythonLauncher 會啟動外部 Python35 程序。
- BxlServer 會與 Python 執行階段合作,以管理資料交換,以及處理結果的儲存。
- SQL Satellite 會管理與 SQL Server 之間相關工作和處理序的通訊。
- BxlServer 會使用 SQL Satellite 來與 SQL Server 進行狀態和結果的通訊。
- SQL Server 會取得結果,並關閉相關工作和處理序。
從遠端用戶端執行的 Python 指令碼
您可以從遠端電腦 (例如膝上型電腦) 執行 Python 指令碼,且只要符合以下條件,這些指令碼就能在 SQL Server 主機上執行:
- 請適當地設計指令碼
- 遠端電腦已安裝 Machine Learning 服務所使用的擴充性程式庫。 需要 revoscalepy 套件,才能使用遠端計算內容。
下圖摘要說明從遠端電腦傳送指令碼時的整體工作流程。
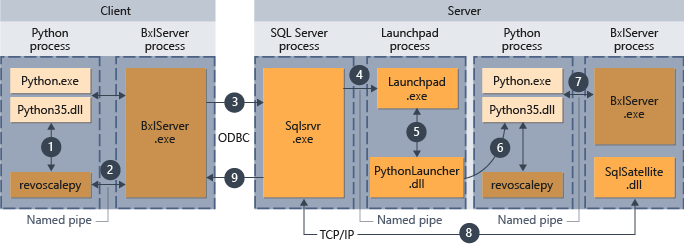
- 針對 revoscalepy 支援的函式,Python 執行階段會呼叫連結函式,而該函式會接著呼叫 BxlServer。
- BxlServer 隨附於 Machine Learning 服務 (資料庫內),且會在 Python 執行階段的個別程序中執行。
- BxlServer 會判斷連線目標並使用 ODBC 初始化連線,並在 Python 指令碼中將認證作為連接字串的一部分來傳遞。
- 由 BxlServer 建立對 SQL Server 實例的連線。
- 呼叫外部指令碼執行階段時會叫用啟動控制板服務,而這會接著啟動適當的啟動程式:在此案例中為 PythonLauncher.dll。 之後,當從 T-SQL 中的預存程序叫用 Python 程式碼時,就會在類似的工作流程中處理 Python 程式碼。
- PythonLauncher 會呼叫安裝在 SQL Server 電腦上 Python 的執行個體。
- 結果會傳回 BxlServer。
- 由 SQL Satellite 管理與 SQL Server 的通訊,並清理相關的工作物件。
- SQL Server 將結果傳回至用戶端。