診斷與解決 SQL Server 的閂鎖競爭
本指南會說明在具有某些工作負載的高並行系統上,執行 SQL Server 應用程式時,如何找出並解決所觀察到的閂鎖競爭問題。
隨著伺服器 CPU 核心的數目持續增加,相關聯的並行執行增加,會在資料庫引擎內造成必須以序列方式存取的資料結構爭用點。 尤其是高輸送量/高並行交易處理 (OLTP) 工作負載。 有許多工具、技術和方法可以解決這些挑戰,在設計應用程式時也有一些做法,有助於避免所有問題。 本文將討論使用執行緒同步鎖定,將這些資料結構存取序列化的資料結構特定競爭類型。
注意
此內容是由 Microsoft SQL Server 客戶諮詢小組 (SQLCAT) 所撰寫,基於他們對高並行系統的 SQL Server 應用程式中頁面閂鎖競爭問題,所進行的識別及解決流程。 文中記載的建議與最佳做法,來自於真實世界中實際開發及部署 OLTP 系統的經驗。
SQL Server 閂鎖競爭是什麼?
閂鎖是 SQL Server 引擎所使用的輕量型同步處理基本資料,以保證記憶體內部結構一致性,包括索引、資料頁和 B 型樹狀結構非分葉頁面等內部結構。 SQL Server 使用緩衝區閂鎖保護緩衝集區中的頁面,並使用 I/O 閂鎖保護尚未載入到緩衝集區的頁面。 每次在 SQL Server 緩衝集區的頁面中寫入或讀取資料時,背景工作執行緒必須先取得該頁面的緩衝區閂鎖。 有各種緩衝區閂鎖類型可供存取緩衝集區的頁面,包括獨佔閂鎖 (PAGELATCH_EX) 和共用閂鎖 (PAGELATCH_SH)。 當 SQL Server 嘗試存取還未出現在緩衝集區中的頁面時,會公佈非同步的 I/O,將頁面載入緩衝集區。 如果 SQL Server 必須等候 I/O 子系統的回應,其會等待獨佔 (PAGEIOLATCH_EX) 或共用 (PAGEIOLATCH_SH) I/O 閂鎖,視要求的類型而定;這是為了防止另一個背景工作執行緒將相同的頁面載入具有不相容閂鎖的緩衝集區。 閂鎖也可以用來保護對緩衝集區頁面以外的內部記憶體結構存取,這些稱為非緩衝區閂鎖。
頁面閂鎖競爭最常見於多 CPU 系統,因此本文會著重於此。
當多個執行緒同時嘗試取得同一記憶體內部結構的閂鎖不相容時,就會發生閂鎖競爭。 因為閂鎖是內部控制機制,所以 SQL 引擎會自動判斷使用閂鎖的時機。 因為閂鎖行為具有決定性,所以包括結構描述設計在內的應用程式決策都會影響此行為。 本文旨在提供下列資訊:
- SQL Server 如何使用閂鎖的背景資訊。
- 調查閂鎖競爭時所使用的工具。
- 如何判斷觀察中的競爭量是否有問題。
我們會討論一些常見案例以及如何處理,以減輕競爭問題的最佳做法。
SQL Server 如何使用閂鎖?
SQL Server 的頁面有 8 KB,可以儲存多筆資料列。 為提高並行工作量及效能,緩衝區閂鎖僅於頁面實體作業期間保持,不同於鎖定,在邏輯交易期間都要保持。
閂鎖是 SQL 引擎的內部機制,可用於提供記憶體一致性,而 SQL Server 使用的鎖定則可提供邏輯交易一致性。 以下為閂鎖與鎖定的比較表:
| 結構 | 目的 | 控制者 | 效能成本 | 公開者 |
|---|---|---|---|---|
| 閂鎖 | 保證記憶體內部結構的一致性。 | 僅限 SQL Server 引擎。 | 效能成本低。 為允許最大並行工作量並提供最高效能,閂鎖僅於記憶體內部結構實體作業期間內保持,不同於鎖定,在邏輯交易期間都要保持。 | sys.dm_os_wait_stats (Transact-SQL) - 提供 PAGELATCH、PAGEIOLATCH 和 LATCH 等候類型 (LATCH_EX 和 LATCH_SH 用於將所有非緩衝區閂鎖等候予以分組) 的相關資訊。 sys.dm_os_latch_stats (Transact-SQL) – 提供非緩衝區閂鎖等候的詳細資訊。 sys.dm_db_index_operational_stats (Transact-SQL):此動態管理檢視 (DMV) 提供每個索引的彙總等候,這有助於針對閂鎖相關的效能問題進行疑難排解。 |
| 鎖定 | 保證交易的一致性。 | 可由使用者控制。 | 因為在交易期間必須保持鎖定,所以鎖定的效能成本高於閂鎖。 | sys.dm_tran_locks (Transact-SQL)。 sys.dm_exec_sessions (Transact-SQL)。 |
SQL Server 閂鎖模式及相容性
有些閂鎖競爭會被視為 SQL Server 引擎作業的正常情況。 在高並行系統中發生多個不相容的並行閂鎖要求,是不可避免的。 SQL Server 會要求不相容的閂鎖要求在佇列中等候,直到未完成的閂鎖要求完成為止,藉此執行閂鎖相容性。
有五種模式可以取得閂鎖,每種模式的存取層級不同。 SQL Server 閂鎖模式摘要如下:
KP -- 保留閂鎖,以確保參考結構無法被終結。 當執行緒想要查看緩衝區結構時使用。 因為除終結 (DT) 閂鎖外,KP 閂鎖與所有閂鎖皆相容,所以 KP 閂鎖被視為「輕量型」,表示使用時對效能的影響最小。 也因為 KP 閂鎖與 DT 閂鎖不相容,所以會防止任何其他執行緒終結參考的結構。 例如,KP 閂鎖會防止 lazywriter 程序終結其參考的結構。 如需如何使用 lazywriter 程序搭配 SQL Server 緩衝區頁面管理的詳細資訊,請參閱撰寫頁面。
SH :共用閂鎖,若要讀取參考的結構 (例如讀取資料頁面) 就必須使用。 多個執行緒可以同時存取資源,以在共用閂鎖下讀取。
UP -- 更新閂鎖,與 SH (共用閂鎖) 和 KP 相容,但與其他閂鎖不相容,所以不允許 EX 閂鎖寫入參考的結構。
EX -- 獨佔閂鎖,禁止其他執行緒寫入或讀取參考的結構。 其中一個使用範例,就是修改頁面的內容,以進行損毀頁保護。
DT -- 終結閂鎖,必須先取得此閂鎖,才能終結參考結構的內容。 例如,lazywriter 程序必須取得 DT 閂鎖以釋放完好頁面,然後才能將其新增至緩衝區清單,以供其他執行緒使用。
閂鎖模式具有不同的相容性等級,例如共用閂鎖 (SH) 與更新 (UP) 或保留 (KP) 閂鎖相容,但與終結閂鎖 (DT) 不相容。 只要閂鎖彼此相容,就可以在相同的結構上同時取得多個閂鎖。 當執行緒嘗試取得模式不相容的閂鎖時,會排進佇列,等候指示資源可用的訊號。 SOS_Task 類型的執行緒同步鎖定是透過實施對佇列的序列化存取,用以保護等候佇列。 您必須取得此執行緒同步鎖定,才能將項目新增至佇列。 當釋放不相容的閂鎖時,SOS_Task 執行緒同步鎖定也會通知佇列中的執行緒,讓等候中的執行緒取得相容的閂鎖並繼續工作。 在釋放閂鎖要求時,會依先進先出 (FIFO) 的順序處理等候佇列。 閂鎖遵循此 FIFO 系統以確保公平,並防止耗盡執行緒。
下表列出閂鎖模式相容性 (Y 表示相容,N 表示不相容):
| 閂鎖模式 | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
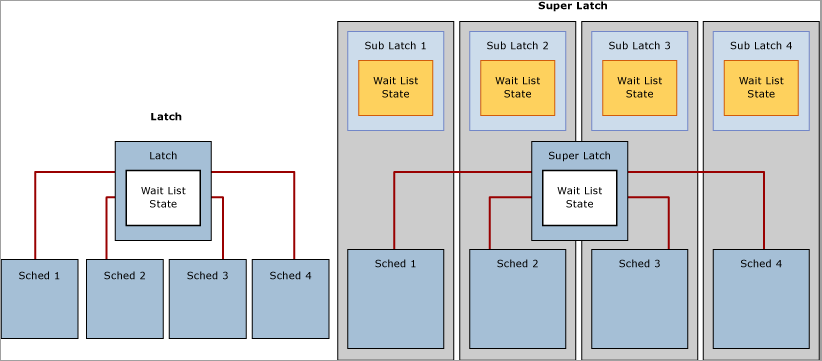
SQL Server superLatch 和 sublatch
隨著 NUMA 型的多通訊端/多核心系統逐漸增加,SQL Server 2005 引進了 SuperLatch (也稱為 sublatch),僅對具備 32 或更多邏輯處理器的系統有效。 Superlatch 改善了高度並行 OLTP 工作負載中某些使用模式的 SQL 引擎效率,例如,當某些頁面有繁重的唯讀共用 (SH) 存取的模式,卻很少寫入時。 例如 B 型樹狀結構 (即索引) 的根頁面,即為具有這類存取模式的頁面,SQL 引擎要求 B 型樹狀結構在任何層級發生頁面分割時,根頁面都能保持共用閂鎖。 在大量插入和高並行 OLTP 工作負載中,頁面分割的數目會隨著輸送量大幅增加,從而降低效能。 Superlatch 可以提高存取共用頁面的效能,而共用頁面上多個同時執行的背景工作執行緒都需要 SH 閂鎖。 為達此目的,SQL Server 引擎會將這類頁面上的閂鎖動態升級至 SuperLatch。 SuperLatch 會將單一閂鎖分割成 sublatch 結構的陣列,每個 CPU 核心的每個資料分割只能有一個 sublatch,因此主要閂鎖會變成 Proxy 重新導向器,而且唯讀閂鎖不需要全域狀態同步處理。 如此一來,一律指派給特定 CPU 的背景工作,只需要取得指派給本機排程器的共用 (SH) sublatch 即可。
注意
SQL Server 文件通常會使用「B 型樹狀結構」一詞來指稱索引。 在資料列存放區索引中,SQL Server 會實作 B+ 樹狀結構。 這不適用於資料行存放區索引或記憶體內部資料存放區。 如需詳細資訊,請參閱 SQL Server 和 Azure SQL 索引架構和設計指南。
取得相容閂鎖 (例如共用 Superlatch) 使用資源較少,而且比非分割共用閂鎖更能調整對熱門頁面的存取,因為只要存取本機 NUMA 記憶體,就能移除全域狀態同步處理需求,大幅改善效能。 相形之下,取得獨佔 (EX) SuperLatch 比取得 EX 一般閂鎖更昂貴,因為 SQL 必須在所有 sublatch 間發出訊號。 當觀察到 SuperLatch 使用繁重的 EX 存取模式時,SQL 引擎可以在緩衝集區捨棄頁面後,降級該頁面。 下圖描述一般閂鎖和資料分割 SuperLatch:
在效能監視器中使用 SQL Server:Latches 物件和相關聯計數器收集有關 Superlatch 的資訊,包括 SuperLatch 的數目、每秒升級的 SuperLatch 數目,以及每秒降級的 SuperLatch 數目。 如需 SQL Server:Latches 物件和相關聯計數器的詳細資訊,請參閱 SQL Server,閂鎖物件。
閂鎖等候類型
累計等候資訊是由 SQL Server 追蹤,可用動態管理檢視 (DMW) sys.dm_os_wait_stats 存取。 SQL Server 採用 sys.dm_os_wait_stats DMV 中對應之 wait_type 所定義的三種閂鎖等候類型:
緩衝區 (BUF) 閂鎖: 用來保證索引和使用者物件資料頁的一致性。 也可以用來保護 SQL Server 用於系統物件的資料頁存取權。 例如,管理配置的頁面可以受到緩衝區閂鎖的保護。 這些包括頁面可用空間 (PFS)、全域配置對應 (GAM)、共用全域配置對應 (SGAM) 及索引配置對應 (IAM) 頁面。 緩衝區閂鎖會以
sys.dm_os_wait_stats報告,使用的wait_type為 PAGELATCH_*。非緩衝區 (非 BUF) 閂鎖: 用來保證緩衝集區頁面以外,所有記憶體內部結構的一致性。 所有非緩衝區閂鎖的等待都會回報
wait_type為 LATCH_*。IO 閂鎖: 緩衝區閂鎖的子集,當受到緩衝區閂鎖保護的相同結構,需要使用 I/O 作業載入緩衝集區時,保證這些結構的一致性。 IO 閂鎖可防止其他執行緒將相同的頁面載入具有不相容閂鎖的緩衝集區。 與
wait_typePAGEIOLATCH_* 相關聯。注意
如果看到大量的 PAGEIOLATCH 等候,即表示 SQL Server 正在等候 I/O 子系統。 雖然一定的 PAGEIOLATCH 等候時間量是預期的正常行為,但如果平均 PAGEIOLATCH 等候時間持續超過 10 毫秒 (ms),建議您調查 I/O 子系統的運作忙碌情形。
如果在檢查 sys.dm_os_wait_stats DMV 時遇到非緩衝區閂鎖,則必須檢查 sys.dm_os_latch_stats,以取得非緩衝區閂鎖的累計等候資訊明細。 所有緩衝區閂鎖等候都會分類在「緩衝區」閂鎖類別下,其餘則用來分類非緩衝區閂鎖。
SQL Server 閂鎖競爭的徵兆和成因
在忙碌的高並行系統中,在經常受到 SQL Server 的閂鎖和其他控制機制存取及保護的結構中,發生主動競爭是正常的。 當與取得頁面閂鎖相關聯的競爭和等候時間足以減少資源 (CPU) 使用率,卻因而阻礙輸送量時,即視為問題。
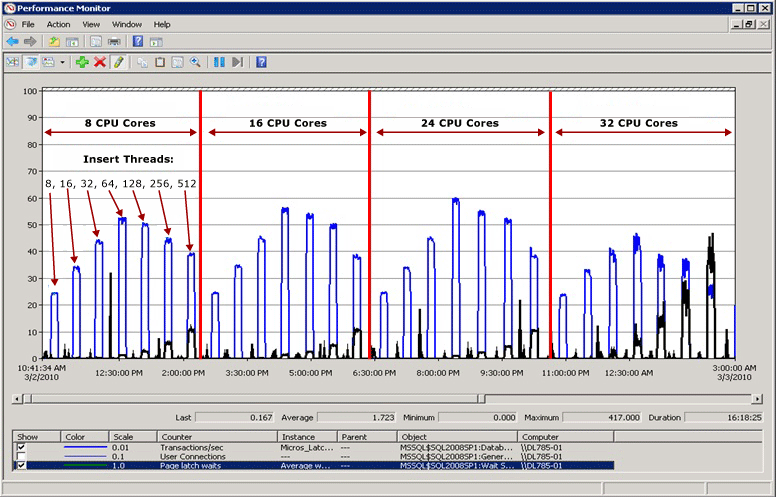
閂鎖競爭範例
在下圖中,藍線代表 SQL Server 的輸送量 (依每秒交易量測量),黑線代表平均頁面閂鎖等候時間。 在本例中,每次交易都會以依序遞增的前置值對叢集索引執行 INSERT 作業,例如,填寫 Bigint 資料類型的 IDENTITY 欄位時。 當 CPU 數目增加到 32 時,整體輸送量會明顯下降,而頁面閂鎖等候時間則增加至約 48 毫秒,如黑線所示。 輸送量和頁面閂鎖等候時間之間的這種反向關聯性,是很容易診斷的常見案例。
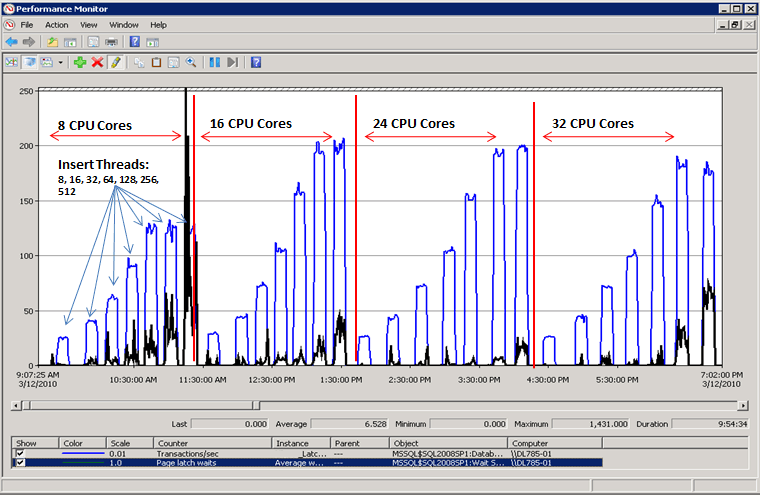
解決閂鎖競爭後的效能
如下圖所示,SQL Server 不再出現頁面閂鎖等候的瓶頸,而按每秒交易量測量的輸送量增加了 300%。 這是使用搭配計算資料行使用雜湊分割技術所完成,本文稍後會說明此技術。 這項效能改進會在具有大量核心和大量並行要求的系統中實施。
影響閂鎖競爭的因素
阻礙 OLTP 環境效能的閂鎖競爭,一般是因為下列一或多個與高並行要求相關的因素所造成:
| 因素 | 詳細資料 |
|---|---|
| SQL Server 使用了大量的邏輯 CPU | 閂鎖競爭會發生在任何多核心系統上。 閂鎖競爭過度,致應用程式效能影響超過可接受程度的 SQLCAT 體驗,最常出現在 CPU 核心超過 16 個,而且可能還會增加其他核心的系統上。 |
| 結構描述設計與存取模式 | B 型樹狀結構的深度、叢集和非叢集索引的設計、每頁的資料列大小和密度,以及存取模式 (讀取/寫入/刪除活動) 都是造成頁面閂鎖競爭過度的因素。 |
| 應用層級的高度並行要求 | 過多的頁面閂鎖競爭一般會與應用層的大量並行要求一起發生。 某些程式設計實務也可能會對特定頁面帶來大量的要求。 |
| SQL Server 資料庫所使用的邏輯檔案配置 | 邏輯檔案配置會影響因配置結構而造成的頁面閂鎖競爭層級,例如頁面可用空間 (PFS)、全域配置對應 (GAM)、共用全域配置對應 (SGAM) 和索引配置對應 (IAM) 頁面。 如需詳細資訊,請參閱 TempDB 監視和疑難排解:配置瓶頸 (英文)。 |
| I/O 子系統效能 | 大量的 PAGEIOLATCH 等候表示 SQL Server 正在等候 I/O 子系統。 |
診斷 SQL Server 閂鎖競爭
本節提供可診斷 SQL Server 閂鎖競爭的資訊,以判斷其是否會對您的環境造成問題。
診斷閂鎖競爭的工具和方法
診斷閂鎖競爭的主要工具如下:
效能監視器,用來監視 SQL Server 的 CPU 使用率和等候時間,並證實 CPU 使用率與閂鎖等候時間之間是否有關聯性。
SQL Server DMV 可用來判斷造成問題的特定閂鎖類型,以及受影響的資源。
在某些情況下,必須使用 Windows 偵錯工具取得及分析 SQL Server 程序的記憶體傾印。
注意
一般只有在針對非緩衝區閂鎖競爭進行疑難排解時,才需要進行這種層級的進階疑難排解。 您可能想要和 Microsoft 產品支援服務合作,處理這種類型的進階疑難排解。
用於診斷閂鎖競爭的技術流程,可總結為下列步驟:
判斷是否有與閂鎖相關的競爭。
使用附錄:SQL Server 閂鎖競爭指令碼提供的 DMV 檢視,判斷受影響的閂鎖和資源類型。
使用針對不同的資料表模式處理閂鎖競爭所述的其中一項技術,減緩競爭。
閂鎖競爭指標
如前所述,只有當 CPU 資源可用,但與取得頁面閂鎖相關聯的競爭和等候時間會阻礙輸送量增加時,閂鎖競爭才會造成問題。 判斷可接受的競爭量需要全面考量效能和輸送量需求,以及可用的 I/O 和 CPU 資源。 本節將逐步引導您判斷閂鎖競爭對工作負載的影響,如下所示:
測量代表性測試期間的整體等候時間。
依序排列其次序。
判斷與閂鎖相關的佔比。
累計等候資訊可自 sys.dm_os_wait_stats DMV 取得。 最常見的閂鎖競爭類型就是緩衝區閂鎖競爭,觀察到 wait_type 為 PAGELATCH_* 的閂鎖等候時間增加。 非緩衝區閂鎖會分組在 LATCH* 等候類型下。 如下圖所示,您應該先使用 sys.dm_os_wait_stats DMV 查看系統的累計等候時間,以判斷緩衝區或非緩衝區閂鎖所造成的整體等候時間百分比。 如果遇到非緩衝區閂鎖,則也必須檢查 sys.dm_os_latch_stats DMV。
下圖說明 sys.dm_os_wait_stats 和 sys.dm_os_latch_stats DMV 傳回的資訊關聯性。

如需 sys.dm_os_wait_stats DMV 的詳細資訊,請參閱 SQL Server 說明中的 sys.dm_os_wait_stats (Transact-SQL)。
如需 sys.dm_os_latch_stats DMV 的詳細資訊,請參閱 SQL Server 說明中的 sys.dm_os_latch_stats (Transact-SQL)。
下列閂鎖等候時間的量值,是閂鎖競爭過量會影響應用程式效能的指標:
平均頁面閂鎖等候時間會隨輸送量增加而增加:如果平均頁面閂鎖等候時間隨輸送量增加而增加,且平均緩衝區閂鎖等候時間也增加超過預期的磁碟回應時間,建議您使用
sys.dm_os_waiting_tasksDMV 檢查目前的等候中工作。 如果在隔離的情況下進行分析,平均值可能會產生誤導,因此可能時請務必查看系統的實際狀況,以了解工作負載的特性。 尤其要檢查任何頁面上的 PAGELATCH_EX 及/或 PAGELATCH_SH 要求等候是否很多。 請遵循下列步驟,診斷隨輸送量增加的平均頁面閂鎖等候時間:- 使用範例指令碼查詢依工作階段識別碼排序的 sys.dm_os_waiting_tasks 或計算一段時間內的等候時間,查看目前等待的工作並測量平均閂鎖等候時間。
- 使用範例指令碼查詢緩衝區描述項以判斷造成閂鎖競爭的物件,以判斷發生競爭的索引和基礎資料表。
- 使用效能監視器計數器 MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time,或執行
sys.dm_os_wait_statsDMV,以測量平均頁面閂鎖等候時間。
注意
若要計算特定等候類型 (
sys.dm_os_wait_stats傳回為 wt_:type) 的平均等候時間,請將總等候時間 (傳回為wait_time_ms) 除以等待工作的數目 (傳回為waiting_tasks_count)。尖峰負載期間耗在閂鎖等候類型的總等候時間百分比:如果整體等候時間的平均閂鎖等候時間百分比與應用程式負載的增加呈正比,則閂鎖競爭可能會影響效能,應予調查。
使用 SQLServer:等候統計資料物件效能計數器測量頁面閂鎖等候和非頁面閂鎖等候。 然後比較這些效能計數器的值,及 CPU、I/O、記憶體和網路輸送量相關效能計數器的值。 例如,交易數/秒和批次要求數/秒,是兩個很好的資源使用率量值。
注意
因為此 DMW 會測量自上次 SQL Server 執行個體啟動後的等候時間,或使用 DBCC SQLPERF 重設的累計等候統計資料,所以
sys.dm_os_wait_statsDMV 不包含每個等候類型的相對等候時間,。 若要計算每個等候類型的相對等候時間,請拍攝sys.dm_os_wait_stats在尖峰負載前後的快照集,然後計算差異。 範例指令碼計算一段時間內的等候時間可用於此用途。僅限非實際執行環境,請使用下列命令清除
sys.dm_os_wait_statsDMV:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')您可以執行類似的命令,以清除
sys.dm_os_latch_statsDMV:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')輸送量不會隨著應用程式負載增加以及可供 SQL Server 使用的 CPU 數目增加而增加,還會在某些情況下減少:閂鎖競爭範例中會說明這一點。
CPU 使用率不會隨應用程式工作負載增加而增加:如果系統上的 CPU 使用率未同時間隨著應用程式輸送量增加而增加,這就表示 SQL Server 正在等待什麼,亦即閂鎖競爭的徵兆。
分析根本原因。 即使前文的每項條件都成立,造成效能問題的根本原因仍可能在他處。 事實上,在大多數情況下,不那麼理想的 CPU 使用率是由其他類型的等候所造成,例如封鎖鎖定、I/O 相關的等候或網路相關問題。 根據經驗法則,在繼續進行更深入的分析之前,最好先解決佔整體等候時間最大比例的資源等候。
分析目前的等候緩衝區閂鎖
如 sys.dm_os_wait_stats DMV 所示,對於 wait_type 為 PAGELATCH_* 或 PAGEIOLATCH_* 的情況,緩衝區閂鎖競爭都會表現為使這類閂鎖的等候時間增加。 若要即時查看系統,請在系統上執行下列查詢,以聯結 sys.dm_os_wait_stats、sys.dm_exec_sessions 和 sys.dm_exec_requests DMV。 此結果可用以判斷目前伺服器的執行工作階段等候類型。
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
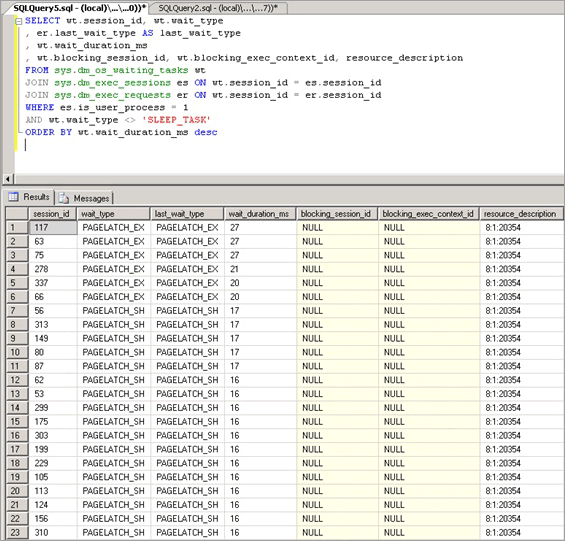
此查詢所公開的統計資料說明如下:
| 統計資料 | 描述 |
|---|---|
| Session_id | 與這項工作相關聯的工作階段識別碼。 |
| Wait_type | SQL Server 記錄在引擎中的等候類型,可阻止執行目前的要求。 |
| Last_wait_type | 如果這個要求先前被封鎖,這個資料行會傳回上次等候的類型。 不可為 Null。 |
| Wait_duration_ms | 自 SQL Server 執行個體啟動,或自累計等候統計資料重設後,耗費在此等候類型上的總等候時間 (毫秒)。 |
| Blocking_session_id | 封鎖要求之工作階段的識別碼。 |
| Blocking_exec_context_id | 與這項工作相關聯的執行內容識別碼。 |
| Resource_description | resource_description 資料行會列出所等候的確切頁面,格式如下:<database_id>:<file_id>:<page_id> |
下列查詢會傳回所有非緩衝區閂鎖的資訊:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
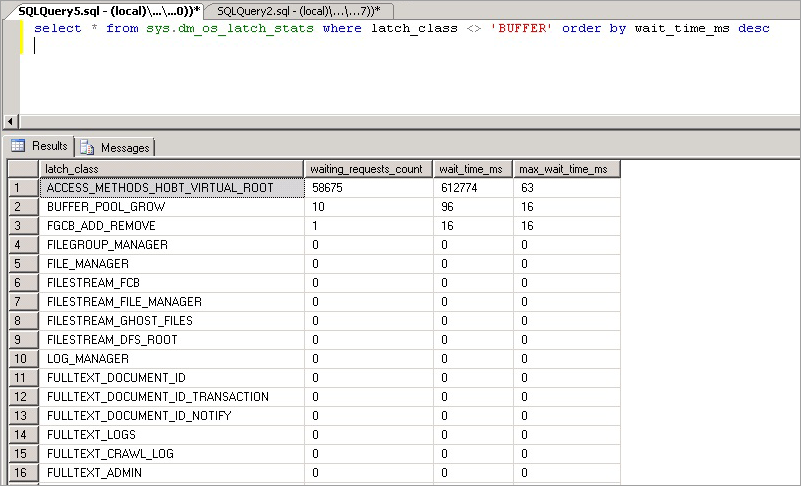
此查詢所公開的統計資料說明如下:
| 統計資料 | 描述 |
|---|---|
| latch_class | SQL Server 記錄在引擎中的閂鎖類型,可阻止執行目前的要求。 |
| waiting_requests_count | 自 SQL Server 重新開機後,此類別的閂鎖等候數。 這個計數器是從開始閂鎖等候時逐量遞增計算。 |
| wait_time_ms | 耗費在此閂鎖類型上的總等候時間 (毫秒)。 |
| max_wait_time_ms | 任何要求耗費在此閂鎖類型上的最長時間 (毫秒)。 |
注意
這個 DMV 傳回的值,是自上次資料庫引擎重新啟動或 DMV 重設後的累計值。 使用 sys.dm_os_sys_info 中的 sqlserver_start_time 資料行,來尋找最近一次資料庫引擎啟動時間。 在長時間執行的系統上,這表示有些統計資料 (例如 max_wait_time_ms) 不太實用。 下列命令可以用來重設此 DMV 的等候統計資料:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
SQL Server 閂鎖競爭案例
已觀察到下列會造成閂鎖競爭過多的案例。
最後一頁/末頁插入競爭
常見的 OLTP 做法是在身分識別或日期資料行上建立叢集索引。 這有助於維護良好的索引實體組織,可大幅提升讀取和寫入索引的效能。 不過,此結構描述會不慎導致閂鎖競爭。 這個問題最常出現在包含小型資料列的大型資料表中,而且會插入包含依序增加前置索引鍵資料行的索引,例如遞增的整數或日期時間索引鍵。 在此案例中,應用程式幾乎很少執行更新或刪除,這是用於封存作業的例外狀況。
在下列範例中,執行緒 1 和執行緒 2 都想要插入一筆將儲存在第 299 頁的記錄。 從邏輯鎖定的觀點來看,因為會使用資料列層級鎖定,而且可以同時保留同頁兩筆記錄的獨佔鎖定,所以沒有問題。 不過,為確保實體記憶體的完整性,一次只能有一個執行緒可以取得獨佔閂鎖,所以存取頁面會被序列化,以免遺失記憶體中的更新。 在本例中,執行緒 1 會取得獨佔閂鎖,而執行緒 2 則等待,這會在等候統計資料中登錄此資源有一筆 PAGELATCH_EX 等待。 這會透過 sys.dm_os_waiting_tasks DMV 中的 wait_type 值顯示。
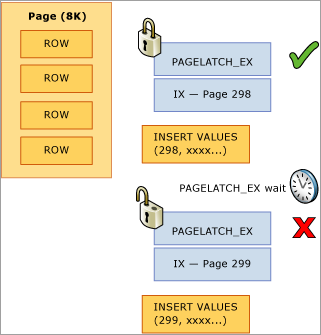
這項競爭因為發生在 B 型樹狀結構的最右邊,所以通常稱為「最後一頁插入」競爭,如下圖所示:
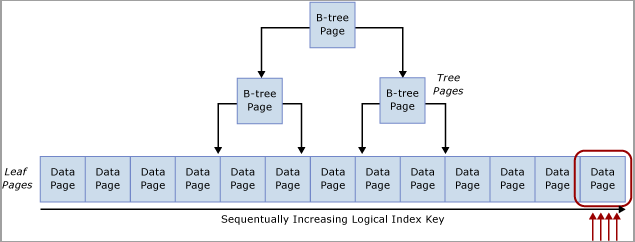
這種類型的閂鎖競爭會在下文中說明。 將新的資料列插入索引中時,SQL Server 會使用下列演算法執行修改:
周遊 B 型樹狀結構,找出要保存新記錄的正確頁面。
使用 PAGELATCH_EX 來閂鎖頁面,防止其他人修改,並取得所有非分葉頁面的共用閂鎖 (PAGELATCH_SH)。
注意
在某些情況下,SQL 引擎也需要取得非分葉 B 型樹狀結構頁面的 EX 閂鎖。 例如,發生頁面分割時,任何受到直接影響的頁面都需要以獨佔方式加上閂鎖 (PAGELATCH_EX)。
記錄資料列經修改的記錄項目。
將資料列新增至頁面,並將頁面標示為「中途」。
取消所有頁面的閂鎖。
如果資料表索引是以依序遞增索引鍵為基礎,則每個新的插入項目都會移至 B 型樹狀結構結尾的同一頁,直到該頁面填滿為止。 在高並行作業案例中,這可能會導致 B 型樹狀結構最右邊發生競爭,而且可能會發生在叢集和非叢集索引中。 受此類競爭影響的資料表主要會接受 INSERT,而有問題索引的頁面通常相對密集 (例如,包含資料列額外負荷的資料列大小為 165 個位元組時,等於每個頁面有 49 個資料列)。 在這類大量插入的範例中,可預期會發生 PAGELATCH_EX/PAGELATCH_SH 等候,這是典型的觀察結果。 若要檢查頁面閂鎖等候與樹狀頁面閂鎖等候,請使用 sys.dm_db_index_operational_stats DMV。
下表會摘要說明此類閂鎖競爭主要因素的觀察結果:
| 因素 | 典型觀察結果 |
|---|---|
| SQL Server 所使用的邏輯 CPU | 此類閂鎖競爭主要發生於具有 16 個以上 CPU 核心的系統上,且最常發生於具有 32 個以上 CPU 核心的系統上。 |
| 結構描述設計與存取模式 | 使用依序遞增的識別值,作為交易資料資料表索引中的前置資料行。 該索引具有遞增的主索引鍵,且具有較高的插入率。 該索引至少有一個依序遞增的資料行值。 通常每頁會具有許多資料列,但資料列大小較小。 |
| 觀察到的等候類型 | 許多執行緒會爭用具有獨佔 (EX) 或共用 (SH) 閂鎖等候的相同資源,這些閂鎖等候會與 sys.dm_os_waiting_tasks DMV 中的 resource_description (與由「等候持續時間」所排序的查詢 sys.dm_os_waiting_tasks 傳回) 建立關聯。 |
| 設計考量因素 | 如果可確保在整個 B 型樹狀結構中,將插入始終均於分佈,請如非循序索引風險降低策略中所述,考慮變更索引資料行的順序。 如果使用雜湊分割風險降低策略,則該策略會移除任何針對其他用途 (例如,滑動視窗封存) 使用資料分割的能力。 使用雜湊分割風險降低策略可能會導致應用程式所使用的 SELECT 查詢出現分割區刪除問題。 |
使用非叢集索引與隨機插入 (佇列資料表) 的小型資料表上發生閂鎖競爭
當將 SQL 資料表作為暫存佇列 (例如,在非同步訊息系統中) 使用時,通常會出現這種情況。
在此案例中,可能會在下列情況中發生獨佔 (EX) 與共用 (SH) 閂鎖競爭:
- 在高並行處理的狀態下進行插入、選取、更新或刪除作業。
- 資料列大小相對較小 (導致密集頁面)。
- 資料表中的資料列數目相對較少,導致形成淺層 B 型樹狀結構 (其定義為只有 2 到 3 個索引深度)。
注意
即使是較深的 B 型樹狀結構,如果資料操作語言 (DML) 頻率與系統的並行程度夠高,這種存取模式也可能會發生競爭。 當 16 個以上的 CPU 核心在系統中運作而導致並行增加時,閂鎖競爭的程度可能會變得更加顯著。
即使在 B 型樹狀目錄中的存取為隨機 (例如,當非循序資料行是叢集索引的前置索引鍵),也可能發生閂鎖競爭。 下列螢幕擷取畫面是系統中出現這類閂鎖競爭時的情況。 在此範例中,因為小型資料列與較淺層 B 型樹狀結構導致頁面密集,進而引發競爭。 當並行增加時,因為 GUID 是索引中的前置資料行,所以即使在 B 型樹狀結構中的插入為隨機,也會在頁面上引發閂鎖競爭。
在下列螢幕擷取畫面中,緩衝區資料頁面與分頁可用空間 (PFS) 頁面上皆發生等候。 如需 PFS 頁面閂鎖競爭的詳細資訊,請參閱下列 SQLSkills 的協力廠商部落格文章:Benchmarking:Multiple data files on SSDs (效能評定:SSD 上的多重資料檔案。)。 即使已增加資料檔案的數目,緩衝區資料頁上同樣很容易發生閂鎖競爭。
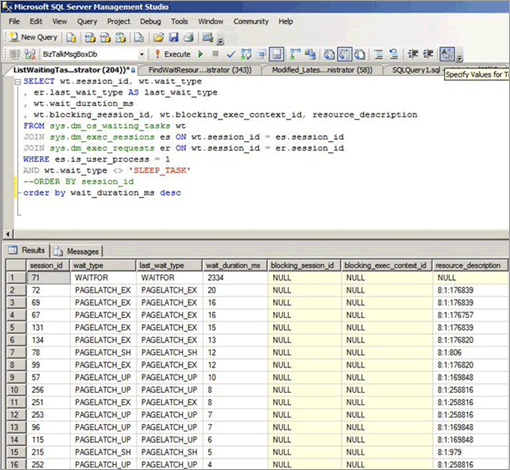
下表會摘要說明此類閂鎖競爭主要因素的觀察結果:
| 因素 | 典型觀察結果 |
|---|---|
| SQL Server 所使用的邏輯 CPU | 閂鎖競爭主要發生在具有 16 個以上 CPU 核心的電腦上。 |
| 結構描述設計與存取模式 | 針對小型資料表進行插入/選取/更新/刪除的存取模式發生率偏高。 淺層 B 型樹狀結構 (2 到 3 個索引深度)。 小型資料列 (每頁多筆記錄)。 |
| 並行程度 | 只有在來自應用程式層的高並行要求下才會發生閂鎖競爭。 |
| 觀察到的等候類型 | 由於根分割而在緩衝區 (PAGELATCH_EX and PAGELATCH_SH) 與非緩衝區閂鎖 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 上發生等候。 PFS 頁面上亦會發生 PAGELATCH_UP 等候。 如需非緩衝區閂鎖等候的詳細資訊,請參閱 SQL Server 說明中的 sys.dm_os_latch_stats (Transact-SQL)。 |
索引中淺層 B 型樹狀結構與隨機插入的組合,很容易在 B 型樹狀結構中造成頁面分割。 為了執行分頁分割,SQL Server 必須取得所有層級的共用 (SH) 閂鎖,然後在頁面分割所涉及的 B 型樹狀結構中,取得頁面上的獨佔 (EX) 閂鎖。 此外,當並行程度很高且資料不斷地插入與刪除時,B 型樹狀結構就可能會發生根分割。 在此情況下,其他插入就必須等候在 B 型樹狀結構上取得的非緩衝區閂鎖。 這將體現為在 sys.dm_os_latch_stats DMV 所觀察到的大量 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 閂鎖類型等候。
您可修改下列指令碼,以決定受影響資料表上索引的 B 型樹狀結構深度。
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
分頁可用空間 (PFS) 頁面上發生閂鎖競爭
PFS 表示分頁可用空間,SQL Server 會為每個資料庫檔案中的每 8088 張頁面 (從 PageID = 1 開始) 配置一張 PFS 頁面。 PFS 頁面中的每個位元組都會記錄資訊,包括該頁面上有多少可用空間、該頁面是否已配置,以及該頁面是否儲存准刪除記錄。 當插入或更新作業需要新的頁面時,PFS 頁面即會包含可供配置的頁面相關資訊。 在大多數情況下,PFS 頁面皆必須進行更新,包括所有配置或取消配置的發生時間。 由於需要使用更新 (UP) 閂鎖來保護 PFS 頁面,因此當檔案群組中的資料檔案相對較少,但 CPU 核心數較多時,就可能在 PFS 頁面上發生閂鎖競爭。 解決此問題的簡單方法為增加每個檔案群組其檔案數目。
警告
增加每個檔案群組其檔案數目可能會對某些負載的效能造成不良影響,例如具有多個大型排序作業的負載,而這些作業會將記憶體溢出到磁碟。
如果 tempdb 中的 PFS 或 SGAM 頁面發生許多 PAGELATCH_UP 等候,請完成下列步驟以消除此瓶頸:
將資料檔案新增至 tempdb,讓 tempdb 資料檔案的數目等於您伺服器中的處理器核心數目。
啟用 SQL Server 追蹤旗標 1118。
如需系統頁面競爭造成配置瓶頸的詳細資訊,請參閱部落格文章什麼是配置瓶頸?(英文)。
tempdb 上的資料表值函數與閂鎖競爭
除了配置競爭以外,還有其他因素也可能會導致 tempdb 發生閂鎖競爭,例如在查詢內大量使用 TVF。
針對不同的資料表模式處理閂鎖競爭
下列各節會描述可用於解決過度閂鎖競爭所導致效能問題的一些技術。
使用非循序的前置索引鍵
其中一個處理閂鎖爭用的方法是使用非循序索引鍵來取代循序索引鍵,以將插入平均分散到整個索引範圍。
做法通常是在索引中建立一個按比例分配工作負載的前置資料行。 有幾個可用選項:
選項:使用資料表中的資料行,在索引鍵範圍內分配值
評估工作負載,以取得可用於在索引鍵範圍間分配插入的自然值。 例如,假設案例為 ATM 銀行業務,因為一名客戶每次只能使用一台 ATM,所以若考慮將插入分配到交易資料表來進行提款,ATM_ID 可能是理想選擇。 同樣地,在銷售點系統中,Checkout_ID 或 Store ID 可能為自然值,其可用來在索引鍵範圍間分配插入。 這項技術需要建立具有前置索引鍵資料行的複合索引鍵,其為所識別資料行的值,或該值的部分雜湊與一或多個其他資料行結合,藉此提供唯一性。 在大部分情況下,值的雜湊最為適合,因為過多不同的值會導致實體組織不佳。 例如,在銷售點系統中,可從 Store ID (即模數) 建立雜湊,其與 CPU 核心數目相符。 這項技術會導致資料表內的範圍相對較小,但足以分配插入以避免閂鎖競爭。 下方為此技術的圖解。
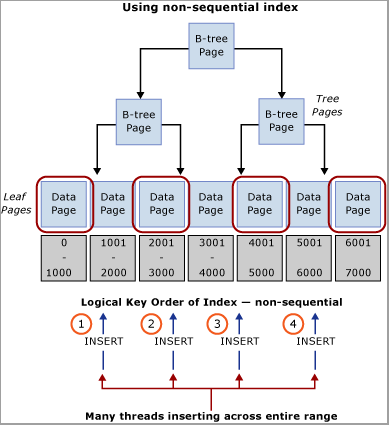
重要
此模式與傳統的索引編制最佳做法互相矛盾。 雖然這項技術有助於確保在 B 型樹狀結構中統一分佈插入,但也可能需要在應用程式層級變更結構描述。 此外,對於需要使用叢集索引進行範圍掃描的查詢,此模式也可能會對查詢效能造成負面影響。 需要分析工作負載模式才能判斷這種設計方法是否合適。 如果能夠犧牲某些循序掃描的效能以獲得插入輸送量與規模,即應該執行此模式。
此模式是在效能實驗室參與期間所實作,並解決了具有 32 個實體 CPU 核心系統上的閂鎖競爭。 資料表是用來儲存交易結尾的最終結餘,每筆商務交易都會在該資料表中插入一次。
原始資料表定義
使用原始資料表定義時,在叢集索引 pk_table1 上會發生過多的閂鎖競爭:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
注意
資料表定義中的物件名稱已從其原始值變更。
重新排列索引定義
使用 UserID 作為主索引鍵中的前置資料行,來重新排列索引的索引鍵資料行,這可讓插入幾乎隨機分佈於頁面上。 因為並非所有使用者都同時上線,所以產生的分佈並非 100% 隨機,但分佈的隨機度已足以緩解過多閂鎖競爭。 重新排列索引定義的其中一個注意事項是,針對此資料表的任何選取查詢都必須修改,以便能夠將 UserID 與 TransactionID 同時作為等號述詞使用。
重要
在實際執行環境中執行之前,請確定已徹底測試測試環境中的所有變更。
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
使用雜湊值作為主索引鍵中的前置資料行
您可使用下列資料表定義來產生與 CPU 數目相符的模數,使用循序增加值 TransactionID 所產生的 HashValue,以確保 B 型樹狀結構中具有統一分佈:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
選項:使用 GUID 作為索引的前置索引鍵資料行
如果沒有自然分隔符號,則可使用 GUID 資料行作為索引的前置索引鍵資料行,以確保插入具有統一分佈。 儘管在索引鍵方法中,使用 GUID 作為前置資料行可供使用資料分割來處理其他功能,但這項技術也可能導致更多頁面分割、實體組織不佳,以及低頁密度等潛在缺點。
注意
使用 GUID 作為索引的前置索引鍵資料行極具爭議性。 此方法的優缺點深入探討不在本文範圍之內。
搭配計算資料行使用雜湊分割
SQL Server 內的資料表分割可用來緩解過多閂鎖競爭。 使用資料分割資料表上的計算資料行來建立雜湊分割配置為常見方法,其可透過下列步驟來完成:
建立新的檔案群組,或使用現有的檔案群組來保存分割區。
如果正在使用新的檔案群組,請在 LUN 上平衡個別檔案,並留意是否已使用最佳配置。 如果存取模式涉及較高的插入率,請務必建立與 SQL Server 電腦實體 CPU 核心數目相同的檔案數目。
使用 CREATE PARTITION FUNCTION 命令,將資料表分割成 X 個分割區,其中 X 為 SQL Server 電腦實體 CPU 核心的數目。 (最多 32 個分割區)
注意
您一律無須讓分割區與 CPU 核心的數目維持在 1:1。 在多數情況下,分割區數目可能會小於 CPU 核心數目。 因為查詢需要搜尋所有分割區,所以較多的分割區可能會對查詢產生額外負荷,而在這類情況下,分割區較少對查詢較有幫助。 在透過實際客戶工作負載以針對 64 與 128 個邏輯 CPU 系統進行的 SQLCAT 測試中,32 個分割區足以解決過多的閂鎖競爭並達成調整目標。 您仍須透過測試來決定最終的理想分割區數目。
使用 CREATE PARTITION SCHEME 命令:
- 將資料分割函數繫結至檔案群組。
- 將 tinyint 或 smallint 類型的雜湊資料行新增至資料表。
- 計算適當的雜湊分佈。 例如,使用 hashbytes 搭配模數或 binary_checksum。
您可自訂下列範例指令碼來進行實作:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
此指令碼針對因最後一頁/末頁插入競爭而產生問題的資料表進行雜湊分割。 這項技術會使用雜湊值模數作業來分割資料表,並將插入分佈至資料表分割區,藉此移除最後一頁的競爭。
搭配計算資料行使用雜湊分割的作用
如下圖所示,這項技術會在雜湊函數上重建索引,並建立與 SQL Server 電腦實體 CPU 核心相同數目的分割區,藉此移除最後一頁的競爭。 插入仍會進入邏輯範圍 (循序增加的值) 其結尾,但雜湊值模數作業可確保插入會分割至不同的 B 型樹狀結構中,以緩解瓶頸。 下圖提供相關說明:
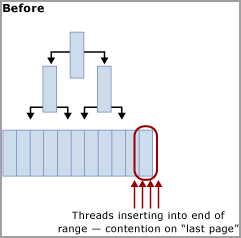
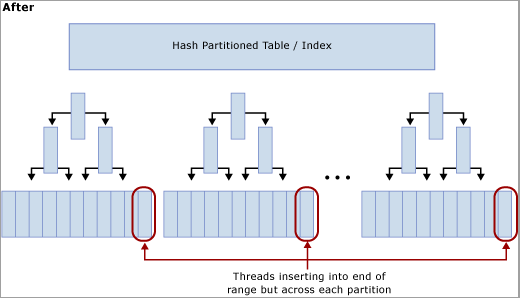
使用雜湊分割時的取捨考量
雖然雜湊分割可消除插入之間的競爭,但在決定使用這項技術之前,仍須考量幾項取捨:
在大多數情況下,您必須修改選取查詢以在述詞中包含雜湊分割,並導致查詢計劃在發出這些查詢時,未消除任何分割區。 下列螢幕擷取畫面顯示不適當的計畫,且在執行雜湊分割之後,並未消除任何分割區。
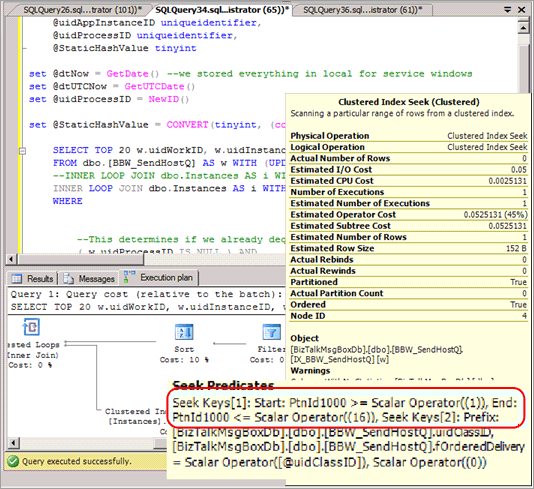
雜湊分割會消除在其他某些查詢 (例如基於範圍的報告) 中消除分割區的可能性。
將雜湊分割資料表聯結至另一個資料表時,為了消除分割區,第二個資料表必須以相同的索引鍵進行雜湊分割,而雜湊索引鍵必須符合聯結準則。
雜湊分割會使得無法使用資料分割來進行其他管理功能 (例如滑動視窗封存與分割切換功能)。
雜湊分割是緩解過度閂鎖競爭的有效策略,這項技術確實能夠減輕插入中的競爭,進而增加整體系統輸送量。 由於您必須做出某些取捨,因此這項技術對於某些存取模式而言,可能不是最佳解決方案。
總結:解決閂鎖競爭的技術
下列兩節會針對可用於解決過度閂鎖競爭的技術提供總結:
非循序索引鍵/索引
優點:
- 允許使用其他資料分割功能,例如使用滑動視窗配置及分割切換功能來封存資料。
缺點:
- 在選擇索引鍵/索引以確保全部的插入一律「足夠」統一分佈時,可能會面臨困難。
- 作為前置資料行的 GUID 可用來保證統一分佈,但可能會產生過多的頁面分割作業。
- B 型樹狀結構中的隨機插入可能會產生過多的頁面分割作業,並導致非分葉頁面上發生閂鎖競爭。
搭配計算資料行的雜湊分割
優點:
- 對於插入而言是透明的。
缺點:
- 資料分割無法用於預期的管理功能,例如使用分割區切換選項來封存資料。
- 可能會出現分割區消除問題,包括個別以及以範圍為基礎的選取/更新查詢,以及執行聯結的查詢皆會受到影響。
- 新增保存的計算資料行為離線作業。
提示
如需其他技術,請參閱 PAGELATCH_EX 等候與大量插入 (英文) 部落格文章。
逐步解說:診斷閂鎖競爭
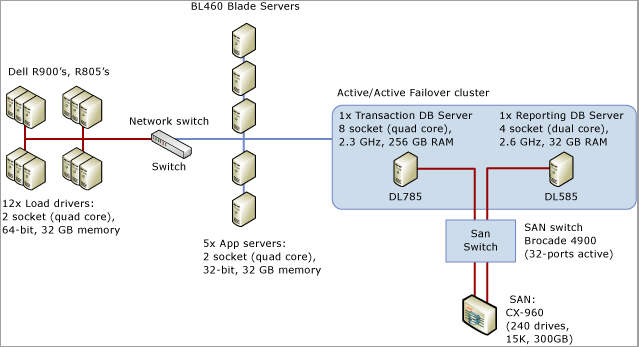
下列逐步解說會示範在診斷 SQL Server 閂鎖競爭以及 處理不同資料表模式的閂鎖競爭中的工具與技術,以解決真實世界案例中的問題。 此案例描述的是客戶參與的銷售點系統負載測試,該系統模擬了大約 8,000 間商店在 SQL Server 應用程式上執行交易的情況,該 SQL Server 應用程式具有 8 個通訊端、32 個搭配 256 GB 記憶體的實體核心系統。
下圖詳述用來測試銷售點系統的硬體:
徵兆:經常性閂鎖
在此案例中,我們發現 PAGELATCH_EX 的等待時間很長 (通常,平均大於 1 毫秒即定義為長等待時間)。 在此案例中,我們不斷觀察到超過 20 毫秒的等候。
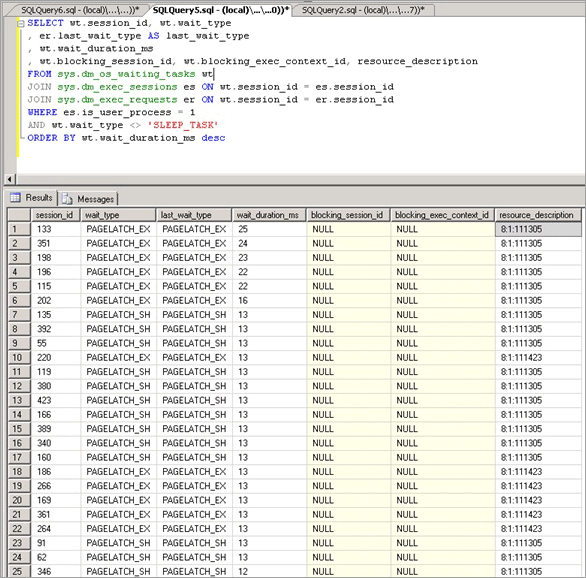
一旦確定閂鎖競爭中存在問題,我們便著手判斷造成閂鎖競爭的原因。
找出造成閂鎖競爭的物件
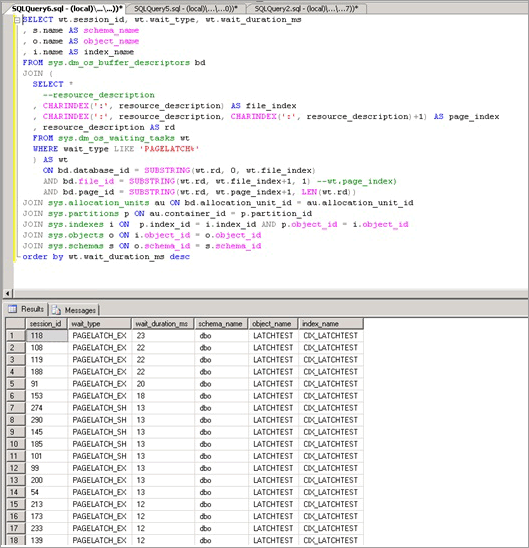
下列指令碼會使用 resource_description 資料行來找出造成 PAGELATCH_EX 競爭的索引:
注意
此指令碼所傳回的 resource_description 資料行會提供格式為 <DatabaseID,FileID,PageID> 的資源描述,其中與 DatabaseID 建立關聯的資料庫名稱可藉由將 DatabaseID 值傳遞至 DB_NAME () 函數來加以判斷。
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
如這裡所示,競爭位於資料表 LATCHTEST 與索引名稱 CIX_LATCHTEST 上。 請注意,為了將工作負載匿名化,已變更名稱。
如需重複輪詢的更進階指令碼,並使用暫存資料表來判斷可設定時段內的總等候時間,請參閱附錄中的判斷造成閂鎖競爭物件的查詢緩衝區描述項。
找出造成閂鎖競爭物件的替代技術
有時候查詢 sys.dm_os_buffer_descriptors 可能有點不切實際。 隨著系統中記憶體,以及可供緩衝集區使用的記憶體增加,執行此 DMV 所需的時間也隨其增加。 在 256 GB 的系統上,此 DMV 最多可能需要 10 分鐘以上的時間來執行。 你可使用另一項替代技術 (大致如下敘述),我們曾在實驗室中以不同的工作負載加以說明:
查詢目前的等候工作,使用附錄指令碼依等候持續時間排序的查詢 sys.dm_os_waiting_tasks。
找出發生阻塞的索引鍵頁面,當多個執行緒在相同頁面上競爭時,就會發生阻塞。 在此範例中,執行插入的執行緒是在 B 型樹狀結構中其末頁上競爭,且會等候至取得 EX 閂鎖為止。 這在第一個查詢中是以 resource_description 表示,在本案例中則為 8:1:111305。
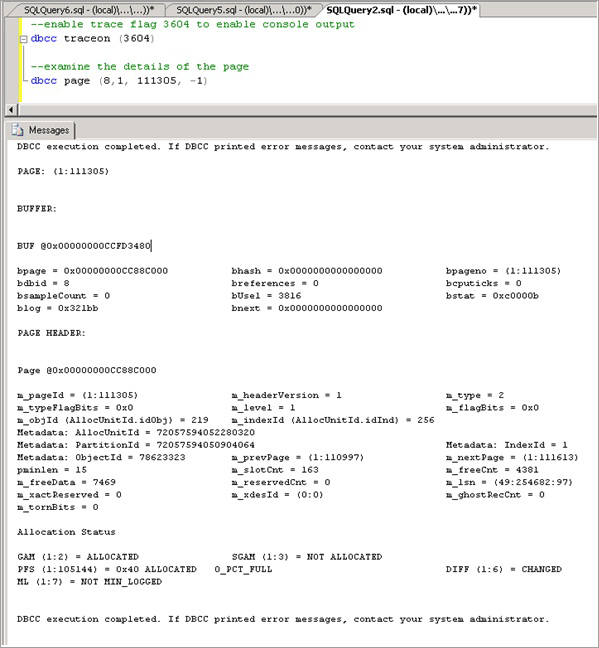
啟用追蹤旗標 3604,此旗標會使用下列語法,透過 DBCC PAGE 公開頁面的進一步資訊,請將括弧中的值取代為透過 resource_description 所取得值:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);檢查 DBCC 輸出。 應會出現相關聯的中繼資料 ObjectID,在本例中即為 '78623323'。
我們現在可執行下列命令來判斷造成競爭的物件名稱,且預期該物件為 LATCHTEST。
注意
請確定您是在正確的資料庫內容中,否則查詢會傳回 Null。
--get object name select OBJECT_NAME (78623323);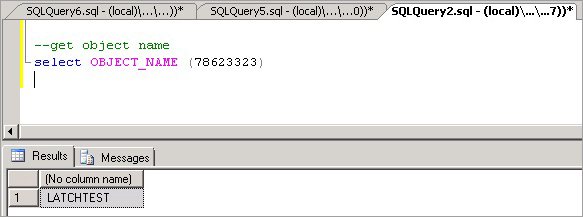
總結與結果
使用上述技術,即可確認競爭發生於叢集索引的資料表上,該資料表上存在具有最多次插入的循序增加金鑰值。 對於具有循序增加索引鍵值 (例如 datetime、identity 或應用程式產生的 transactionID) 的索引而言,這類競爭並不罕見。
為了解決此問題,我們使用了雜湊分割搭配計算資料行,並發現效能改善了 690%。 下表摘要說明在搭配計算資料行實作雜湊分割的前後,所產生的應用程式效能差異。 在移除閂鎖競爭瓶頸後,CPU 使用率與輸送量的增加幅度大致上會與預期一致:
| 測量 | 在進行雜湊分割之前 | 在進行雜湊分割之後 |
|---|---|---|
| 商務交易數/秒 | 36 | 249 |
| 平均頁面閂鎖等候時間 | 36 毫秒 | 0.6 毫秒 |
| 閂鎖等候時間/秒 | 9,562 | 2,873 |
| SQL 處理器時間 | 24% | 78% |
| SQL 批次要求數/秒 | 12,368 | 47,045 |
如上表所示,正確地識別及解決過度分頁閂鎖競爭所造成的效能問題,可能會對整體應用程式效能產生正面的影響。
附錄:替代技術
其中一項可避免過度分頁閂鎖競爭的可能策略,是填補具有 CHAR 資料行的資料列,以確保每個資料列都會使用完整的頁面。 當整體資料大小較小,且您必須解決下列因素組合所造成的 EX 頁面閂鎖競爭時,此策略是一個可行選項:
- 較小資料列大小
- 淺層 B 型樹狀結構
- 具有高比率隨機插入、選取、更新及刪除作業的存取模式
- 暫存佇列資料表等的小型資料表
如果要填補資料列來佔用完整頁面,您需要 SQL 配置額外的頁面、讓更多頁面可供插入,以及減少 EX 頁面閂鎖競爭。
填補資料列,以確保每個資料列都佔用完整的頁面
您可以使用類似於以下的指令碼來填補資料列,以佔用整個頁面:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
注意
盡可能運用強制一個資料列只能使用一個頁面的最小 Char,以減少填補值的額外 CPU 需求,以及記錄資料列所需的額外空間。 在高效能系統中,每個位元組都很重要。
這項技術是用於完整說明;而在實務上,SQLCAT 只在單一效能參與中,於具有 10,000 個資料列的小型資料表上使用此技術。 因為這項技術會增加 SQL Server 上大型資料表的記憶體壓力,且可能導致非分葉頁面上發生非緩衝區閂鎖競爭,所以其應用有限。 額外的記憶體壓力可能是應用這項技術的重要限制因素。 伴隨新式伺服器中可用的記憶體數量,OLTP 工作負載的大部分工作集通常會保存在記憶體中。 當資料集的大小增加到無法再容納到記憶體時,效能將會大幅下降。 因此,這項技術只適用於小型資料表。 SQLCAT 不會在大型資料表的最後一頁/末頁插入競爭等案例中使用這項技術。
重要
因為此策略可能會導致在 B 型樹狀結構的非分葉層級中發生大量頁面分割,所以採用這項策略可能會導致 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 閂鎖類型等候時間過久。 如果發生這種情況,SQL Server 必須在所有層級取得共用 (SH) 閂鎖,然後在可能進行頁面分割的 B 型樹狀結構頁面上,取得獨佔 (EX) 閂鎖。 檢查 sys.dm_os_latch_stats DMV,以了解在填補資料列之後,ACCESS_METHODS_HOBT_VIRTUAL_ROOT 閂鎖類型等候時間過久的情形。
附錄:SQL Server 閂鎖競爭指令碼
本節包含可用來協助診斷及疑難排解閂鎖競爭問題的指令碼。
查詢依工作階段識別碼排序的 sys.dm_os_waiting_tasks
下列範例指令碼會查詢 sys.dm_os_waiting_tasks,並傳回依工作階段識別碼排序的閂鎖等候時間:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
查詢依等候持續時間排序的 sys.dm_os_waiting_tasks
下列範例指令碼會查詢 sys.dm_os_waiting_tasks,並傳回依等候時間排序的閂鎖等候時間:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
計算一段時間內的等候時間
下列指令碼會計算並傳回一段時間內的閂鎖等候時間。
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
查詢緩衝區描述項,用以判斷造成閂鎖競爭的物件
下列指令碼會查詢緩衝區描述項,以判斷哪些物件與最長閂鎖等候時間相關聯。
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
雜湊分割指令碼
使用具有計算資料行的雜湊分割會說明此指令碼的使用方式,且應針對您的實作目的加以自訂。
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
後續步驟
如需效能監視工具的詳細資訊,請參閱效能監視及微調工具。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應