本文提供有關如何在高並行系統上的 SQL Server 應用程式中識別和解決同步鎖定爭用相關問題的深入資訊。
備註
這裡記載的建議和最佳做法是根據實際 OLTP 系統開發和部署期間的實際體驗。 它最初由Microsoft SQL Server 客戶諮詢小組 (SQLCAT) 小組發佈。
背景
過去,商用 Windows Server 計算機只利用一或兩個微控制器/CPU 晶片,而 CPU 只設計成單一處理器或「核心」。 計算機處理能力的增加是透過使用更快的CPU來實現的,而這主要得益於電晶體密度的進步。 繼《摩爾法》之後,自1971年開發第一個通用單晶元 CPU 以來,可在積體電路上放置的晶體管密度或晶體管數量一直翻一番。 近年來,透過更快速的CPU來增加電腦處理容量的傳統方法已被並且透過建置具有多個CPU的電腦而增強。 截至撰寫本文時,Intel Nehalem CPU 架構每個 CPU 最多可容納八個核心,使用八個插槽系統時,可以利用超執行緒技術,將其提高到 128 個邏輯處理器。 在 Intel CPU 上,SMT 被稱為超執行緒。 隨著 x86 相容電腦上的邏輯處理器數目增加,並行相關問題隨著邏輯處理器競爭資源而增加。 本指南說明如何在具有某些工作負載的高並行系統上執行SQL Server 應用程式時所觀察到的特定資源爭用問題。
在本節中,我們會分析 SQLCAT 小組在診斷和解決自旋鎖爭用問題中所學到的經驗教訓。 在高擴展性系統中,Spinlock 爭用是觀察到的一種並行性問題,特別表現在真實客戶的工作負載中。
自旋鎖定爭用的癥狀和原因
本節說明如何診斷 同步鎖定爭用的問題,這不利於 SQL Server 上的 OLTP 應用程式效能。 自旋鎖診斷和故障排除應被視為高階的主題,這需要具備偵錯工具和 Windows 系統內部的知識。
自旋鎖是輕量型同步原語,用於保護資料結構的存取。 自旋鎖並非 SQL Server 所特有。 當需要在短時間內存取特定數據結構時,作業系統就會使用它們。 當線程嘗試獲取自旋鎖但無法取得存取權時,它會在迴圈中定期執行,以檢查資源是否可用,而不是立即放棄。 經過一段時間之後,等待自旋鎖的線程將讓出執行,然後才能取得資源。 讓位可讓其他線程有機會在同一個CPU上執行。 此行為稱為輪詢,本文稍後會更深入地討論。
SQL Server 會利用微調鎖定來保護對某些內部數據結構的存取。 在引擎內會使用自旋鎖,以類似鎖存的方式來串行化對特定資料結構的存取。 自旋鎖和閂鎖之間的主要差異在於,當線程嘗試取得由自旋鎖保護之資料結構的存取權時,自旋鎖會進行一段時間的迴圈檢查,以確保數據結構的可用性;而當線程試圖獲得由閂鎖保護之結構的存取權時,如果資源不可用,閂鎖會立即讓出而不等待。 讓步需要將線程從 CPU 切換出來,以便執行另一個線程。 這是一項相對昂貴的作業,對於短期內保留的資源而言,整體上更有效率,可讓線程定期在迴圈中執行,以檢查資源的可用性。
SQL Server 2022 (16.x)中導入的資料庫引擎內部調整,使自旋鎖更有效率。
癥狀
在任何忙碌的高並行系統上,通常會在經常存取的結構上看到受線程同步鎖定保護的作用中競爭。 只有在爭用造成大量 CPU 額外負荷時,才會將此使用量視為有問題。 旋轉鎖統計數據由 SQL Server 內的sys.dm_os_spinlock_stats動態管理檢視(DMV)公開。 例如,此查詢會產生下列輸出:
備註
本文稍後將討論解譯此 DMV 所傳回之資訊的詳細資訊。
SELECT *
FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
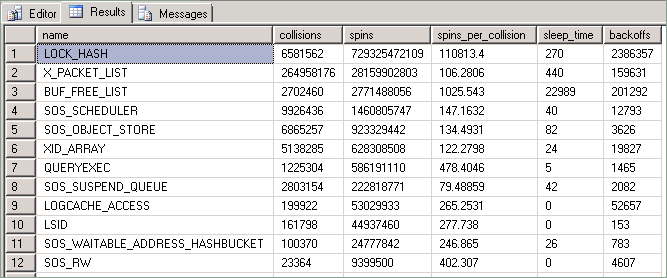
此查詢所公開的統計資料描述如下:
| 資料行 | 說明 |
|---|---|
| 碰撞 | 每次線程遭到封鎖而無法存取受線程同步鎖定保護的資源時,就會遞增此值。 |
| 旋轉 | 每當線程在等待自旋鎖變得可用時執行迴圈,這個值就會遞增。 這是線程嘗試取得資源時所執行的工作量量值。 |
| 每次碰撞旋轉次數 | 每次衝突的旋轉比例。 |
| 睡眠時間 | 與退場事件相關;不過,與本文所述的技術無關。 |
| 退避 | 發生於嘗試存取保留資源的「旋轉」線程已判斷它需要允許相同 CPU 上的其他線程執行時。 |
為了進行此討論,特別感興趣的統計數據是系統在負載沉重的特定期間內發生的碰撞、自旋和試退事件數目。 當線程嘗試存取受線程同步鎖定保護的資源時,就會發生衝突。 發生衝突時,衝突計數會遞增,線程會開始在迴圈中旋轉,並定期檢查資源是否可用。 每次線程運行(迴圈),迴圈計數都會遞增。
每次衝突的自旋次數是衡量線程持有自旋鎖期間發生的自旋數量的指標,並告訴您線程持有自旋鎖期間出現多少次自旋。 例如,每次衝突的小次數的自旋和較高的碰撞次數表示在自旋鎖下發生少量的自旋,而且有許多線程在爭用它。 大量的自旋表示在自旋鎖代碼中花費的時間相對較長壽(也就是說,代碼在散列桶中處理大量條目)。 隨著競爭增加(因此導致碰撞次數增多),自旋的數量也會增加。
退避可以類似於旋轉這樣去理解。 根據設計,為了避免過多的 CPU 浪費,自旋鎖在可以訪問被持有的資源之前,不會無限期地繼續旋轉。 為了確保自旋鎖不會過度使用 CPU 資源,自旋鎖會退讓或停止旋轉並進入「睡眠」狀態。 不論其是否取得目標資源的擁有權,自旋鎖都會退避。 這樣做是為了允許將其他線程排程在CPU上,希望這可讓更有生產力的工作發生。 引擎的預設行為是先旋轉固定時間間隔,再執行退避。 嘗試取得同步鎖定需要維護快取並行狀態,這是相對於旋轉 CPU 成本的 CPU 密集作業。 因此,嘗試取得自旋鎖時會謹慎執行,而不會在每次線程自旋時執行。 在 SQL Server 中,某些自旋鎖類型(例如,LOCK_HASH)藉由將嘗試獲取自旋鎖的間隔時間以指數方式增加(直到某個限制),從而得到了改善,這通常會減少對 CPU 效能的影響。
下圖提供自旋鎖算法的概念圖:

一般案例
自旋鎖爭用可能會因為與資料庫設計決策無關的任何原因而發生。 由於自旋鎖閘道存取內部資料結構,因此自旋鎖爭用與緩衝閂鎖爭用的呈現方式並不相同,後者會直接受到架構設計選擇和資料存取模式的影響。
主要與自旋鎖競爭相關的徵兆是,由於大量的自旋和許多執行緒嘗試取得相同的自旋鎖,導致 CPU 使用率很高。 一般而言,這已在具有 24 個和更多 CPU 核心的系統上觀察到,而且最常在具有 32 個 CPU 核心的系統上。 如前所述,在自旋鎖上的某種程度爭用對於承載著顯著負載的高並行 OLTP 系統是正常的,並且在長時間運行的系統上,經常從 sys.dm_os_spinlock_stats DMV 報告出大量的自旋次數(達到十億/萬億次)。 同樣地,僅觀察任一指定類型的自旋鎖的高旋轉次數,並不足以判斷工作負載效能是否受到負面影響。
下列幾種症狀的組合可能表示自旋鎖競爭。 如果上述所有條件都成立,請對可能的自旋鎖爭用問題進行進一步研究。
針對某種特定的自旋鎖,觀察到大量的旋轉等待和退避現象。
系統遇到大量 CPU 使用率或 CPU 耗用量尖峰。 在高負載CPU情境中,您會看到在
SOS_SCHEDULER_YIELD上有高訊號等候(由DMVsys.dm_os_wait_stats報告)。系統遇到高併發量。
CPU 使用量和 CPU 忙碌程度的增加與輸送量不成比例。
容易診斷的一個常見現象是輸送量和CPU使用量的顯著差異。 許多 OLTP 工作負載在 (系統上的輸送量/用戶數目) 與 CPU 耗用量之間有關聯性。 伴隨著 CPU 耗用量和輸送量大幅差異觀察到的高自旋次數,可能是導致 CPU 額外負擔的自旋鎖爭用的指示。 這裡要注意的一個重要事項是,當某些查詢隨著時間變得更昂貴時,在系統中也常常出現這類差異。 例如,針對一段時間執行更多邏輯讀取的數據集發出的查詢可能會導致類似的徵兆。
這很重要
針對這類問題進行疑難解答時,請務必排除其他較常見的高 CPU 原因。
即使上述每個條件都成立,仍有可能是高CPU耗用量的根本原因位於別處。 事實上,在絕大多數情況下,增加CPU是由於線程同步鎖定爭用以外的原因。
增加 CPU 耗用量的一些較常見原因包括:
- 查詢因基礎數據的增長需要額外的記憶體常駐數據邏輯讀取,隨著時間推移而變得更加昂貴。
- 查詢計劃中的變更導致不理想的執行。
範例
在下列範例中,CPU 耗用量與每秒交易測量的輸送量之間有一個近乎線性的關聯性。 這裡通常會看到一些分歧,因為任何工作負載增加時會產生額外負荷。 如這裡所述,這種分歧變得很重要。 一旦 CPU 耗用量達到 100%,輸送量也會急劇下降。

在測量每隔 3 分鐘的旋轉次數時,我們看到旋轉次數增加的情況更接近指數增長而不是線性增長,這表示自旋鎖的爭用可能會有問題。
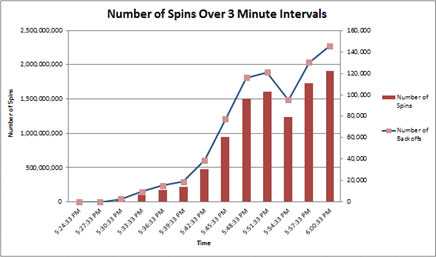
如先前所述,自旋鎖在負載過重的高併發系統中最為常見。
一些容易發生此問題的案例包括:
無法完整限定物件名稱所造成的名稱解析問題。 如需詳細資訊,請參閱 編譯鎖定所造成的 SQL Server 封鎖描述。 本文會更詳細地說明此特定問題。
鎖定管理員中對於經常存取相同鎖定的工作負載,發生鎖定哈希桶的爭用,例如在經常讀取的資料列上進行共用鎖定。 這種爭用類型會以自旋鎖的形式
LOCK_HASH出現。 在一個特定案例中,我們發現此問題因測試環境中的模型存取模式不正確而呈現。 在此環境中,由於測試參數設定不正確,線程數目超過預期的線程會持續存取完全相同的數據列。當 MSDTC 交易協調器之間有高度延遲時,DTC 交易的發生率會很高。 此特定問題已詳細記載於 SQLCAT 部落格文章《解決 DTC 相關等待問題及調整 DTC 可擴展性》中。
診斷自旋鎖爭用
本節提供診斷 SQL Server 同步鎖定爭用的資訊。 用來診斷自旋鎖競爭的主要工具如下:
| 工具 | 使用 |
|---|---|
| 效能監視器 | 尋找高 CPU 條件或輸送量與 CPU 耗用量之間的差異。 |
| 自旋鎖統計數據 | 查詢 sys.dm_os_spinlock_stats DMV,以檢查一段時間內自旋次數和退避事件的高峰狀況。 |
| 等候統計數據 | 從 SQL Server 2025 (17.x) 預覽版開始,使用等候類型查詢sys.dm_os_wait_stats和SPINLOCK_EXT DMV。 需要 追蹤旗標 8134。 如需詳細資訊,請參閱 SPINLOCK_EXT。 |
| SQL Server 擴充事件 | 用來追蹤發生大量微調之線程同步鎖定的呼叫堆疊。 |
| 記憶體轉儲 | 在某些情況下,SQL Server 進程的記憶體轉儲和 Windows 偵錯工具。 一般而言,當Microsoft支援小組參與時,就會執行此層級的分析。 |
診斷 SQL Server Spinlock 爭用的一般技術程式如下:
步驟 1:判斷可能有與自旋鎖相關的爭用。
步驟 2:從
sys.dm_os_spinlock_stats擷取統計數據,以尋找發生最多爭用的旋轉鎖類型。步驟 3:取得 sqlservr.exe 的偵錯符號(sqlservr.pdb),並將符號放在與 SQL Server 服務相同的目錄中,.exe 檔案(sqlservr.exe),以供 SQL Server 實例使用。\ 若要查看輪詢事件的呼叫堆棧,您必須具有所執行之 SQL Server 特定版本的符號。 MICROSOFT符號伺服器上提供 SQL Server 的符號。 如需如何從Microsoft符號伺服器下載符號的詳細資訊,請參閱 使用符號進行偵錯。
步驟 4:使用 SQL Server 擴充事件來追蹤您感興趣的自旋鎖類型的退避事件。 要擷取的事件為
spinlock_backoff和spinlock_backoff_warning。
擴充事件可讓您追蹤退避事件,並擷取這些作業最常嘗試取得自旋鎖的呼叫堆疊。 藉由分析呼叫堆疊,可以判斷哪一種作業類型會促成任何特定線程鎖定的爭用。
診斷操作指引
下列操作指南示範如何使用技術與工具,在現實世界案例中診斷自旋鎖競爭問題。 本操作指南是基於一個執行基準測試的客戶專案設計而成,該測試模擬在擁有8個插槽、64個實體核心以及1 TB記憶體的伺服器上大約6,500名同時用戶。
癥狀
觀察到 CPU 定期的尖峰,使得 CPU 使用率幾乎達到 100%。 觀察到輸送量與CPU耗用量之間的差異導致問題。 在發生顯著 CPU 尖峰之前,已經確立了一種模式,即在高 CPU 使用量期間,於特定間隔發生大量旋轉的情況。
這是一個極端情況,因為爭用導致了旋轉鎖車隊情況的發生。 當線程無法再進行處理工作負載,而是花費所有嘗試取得鎖定存取權的處理資源時,就會發生車隊。 效能監視器記錄說明事務歷史記錄輸送量與CPU耗用量之間的這種差異,最後是CPU使用率大幅飆升。
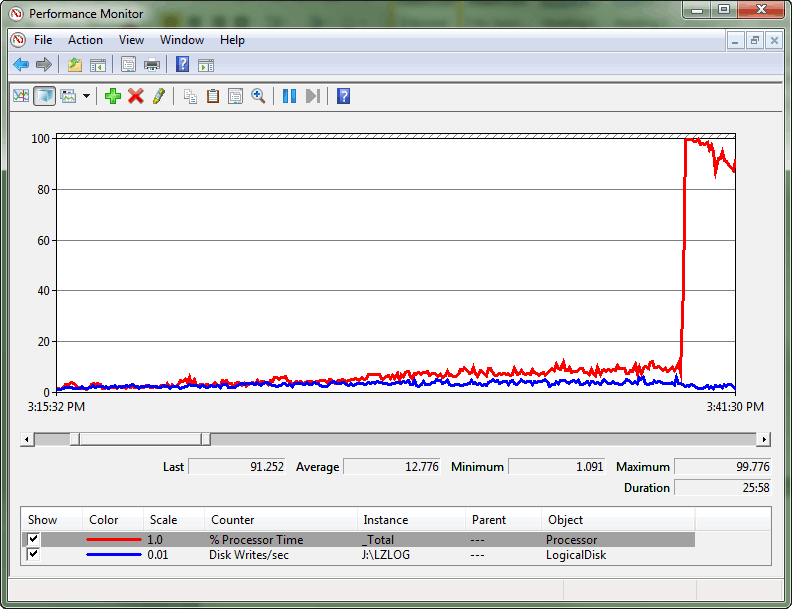
查詢 sys.dm_os_spinlock_stats 以確定 SOS_CACHESTORE 是否存在重大衝突後,使用擴充事件腳本來測量感興趣的自旋鎖類型的退避事件數目。
| 名稱 | 碰撞 | 旋轉 | 每次衝突的旋轉 | 退避策略 |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
量化自旋影響的最直接方式,就是查看自旋鎖類型中自旋次數最多的類型在相同 1 分鐘時間間隔內由 sys.dm_os_spinlock_stats 揭露的退避事件數量。 這個方法最適合偵測重大爭用,因為它顯示了線程在閒置時為獲取自旋鎖而耗盡旋轉限制的情況。 下列腳本闡述了一種利用延伸事件來測量相關退避事件的進階技巧,並識別出存在爭用的特定程式碼路徑。
如需 SQL Server 中擴充事件的詳細資訊,請參閱 擴充事件概觀。
指令碼
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketizer target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
藉由分析輸出,我們可以看到 SOS_CACHESTORE 的旋轉最常見的程式碼路徑呼叫堆疊。 腳本在 CPU 使用率偏高時執行了幾次,以檢查傳回呼叫堆疊中的一致性。 具有最高時槽桶數的呼叫堆疊在兩個結果中均出現(35,668 和 8,506)。 這些呼叫堆疊的槽位數量比下一個最高項目多兩個數量級。 此條件表示感興趣的程式代碼路徑。
備註
查看前一個腳本所傳回的呼叫堆疊並不罕見。 當腳本執行 1 分鐘時,我們觀察到,插槽計數 > 1,000 的呼叫堆疊有問題,但插槽計數 > 10,000 的呼叫堆疊更有可能有問題,因為它是較高的插槽計數。
備註
已針對可讀性目的清除下列輸出的格式設定。
輸出 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
輸出 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
在上一個範例中,最有趣的堆疊擁有最高的槽數(35,668 和 8,506)。事實上,其槽數大於 1,000。
現在問題可能是「我該怎麼處理這項資訊」? 一般而言,需要對 SQL Server 引擎有深入的瞭解,才能使用 callstack 資訊,因此此時疑難解答程式會移至灰色區域。 在此特定案例中,藉由查看呼叫堆疊,我們可以看到發生問題的程式代碼路徑與安全性和元數據查閱有關(如下列堆棧框架 CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)所示。
單獨使用這項資訊很難解決問題,但它確實給我們一些想法,讓我們知道應將後續的疑難排解集中在哪裡,以便進一步隔離問題。
由於此問題看起來與執行安全性相關檢查的程式代碼路徑相關,因此我們決定執行測試,讓聯機到資料庫的應用程式使用者獲授與 sysadmin 許可權。 雖然在生產環境中絕不建議使用這項技術,但在我們的測試環境中,它被證明是有用的疑難解答步驟。 當會話使用提高的許可權執行時,sysadmin與爭用相關的 CPU 尖峰會消失。
選項和因應措施
顯然,疑難解答同步鎖定爭用可能是一項非簡單的工作。 沒有“一個常見的最佳方法”。 疑難解答和解決任何效能問題的第一個步驟是找出根本原因。 使用本文所述的技術和工具,是執行瞭解線程同步鎖定相關爭用點所需的分析的第一個步驟。
隨著新版 SQL Server 的開發,引擎會藉由實作更妥善針對高並行系統優化的程式代碼,繼續改善延展性。 SQL Server 為高並行系統推出了多項優化,其中一項是針對最常見的資源爭用點採用指數回退策略。 從 SQL Server 2012 開始,有一些增強功能會利用引擎內所有自旋鎖的指數退避演算法,特別改善這個特定區域。
設計需要極端效能和規模的高階應用程式時,請考慮如何儘可能縮短 SQL Server 內所需的程式代碼路徑。 較短的程式代碼路徑表示資料庫引擎會執行較少的工作,而且自然會避免爭用點。 許多最佳做法的副作用是減少引擎的工作量,從而改善工作負載的效能表現。
以本文稍早的幾個最佳做法為例:
完整名稱: 為所有物件使用完整名稱能夠避免 SQL Server 必須執行用以解析名稱的程式代碼路徑。 我們觀察到當在呼叫儲存過程時未使用完全限定名稱時,旋轉鎖類型
SOS_CACHESTORE上也出現了衝突點。 無法完整限定這些名稱會導致 SQL Server 需要查詢使用者的預設架構,這會導致執行 SQL 所需的較長程式碼路徑。參數化查詢: 另一個範例是利用參數化查詢和預存過程調用來減少產生執行計劃所需的工作。 這再次導致執行的程式代碼路徑較短。
LOCK_HASH爭用: 在某些情況下,某些鎖定機制或哈希桶衝突的爭用是不可避免的。 雖然 SQL Server 引擎分割了大部分的鎖定結構,但取得鎖定時仍會導致存取相同的哈希貯體。 例如,應用程式會同時由許多線程存取相同的數據列(也就是參考數據)。 這些類型的問題可透過在資料庫架構內擴展此參考數據,或盡可能使用樂觀式並行控制及優化鎖定的技術來達成。
調整 SQL Server 工作負載的第一道防線一律是標準微調做法(例如索引編製、查詢優化、I/O 優化等等)。 不過,除了標準微調之外,遵循減少執行作業所需程式代碼數量的做法是一個重要的方法。 即使遵循最佳做法,仍有可能在忙碌的高並行系統上發生自旋鎖爭用。 使用本文中的工具和技術有助於隔離或排除這些類型的問題,並判斷何時必須參與正確的Microsoft資源來協助。
附錄:自動化記憶體轉儲擷取
下列擴展事件腳本已被證明,在自旋鎖爭用變得顯著時,用於自動收集記憶體轉儲是相當實用的。 在某些情況下,可能需要記憶體轉儲來進行問題的全面診斷,或者它們可能是由 Microsoft 團隊要求的以便進行深入分析。
下列 SQL 腳本可用來自動化擷取記憶體轉儲的程式,以協助分析線程同步鎖定爭用:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs;
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
附錄:擷取隨時間變化的旋轉鎖統計資料
下列腳本可用來查看特定時間段的自旋鎖統計數據。 每次執行時,它都會傳回目前值與先前收集的值之間的差異。
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;