堆積 (無叢集索引的資料表)
適用於:SQL Server、Azure SQL 資料庫 和 Azure SQL 受控執行個體。
堆積是一種沒有叢集索引的資料表。 一個或多個可以建立在儲存為堆積之資料表上的非叢集索引。 資料會以無指定順序的方式儲存於堆積中。 通常數據會以插入數據列的順序來儲存。 不過,資料庫引擎 可以在堆積中移動數據,以有效率地儲存數據列。 在查詢結果中,無法預測數據順序。 為確保從堆積中傳回之資料列順序,您必須使用 ORDER BY 子句。 若要指定儲存資料列的永久邏輯順序,請於資料表上建立叢集索引,如此一來資料表便不是堆積。
注意
有些時候不建立叢集索引,而讓資料表保持為堆積反而有助於工作,但有效地使用堆積是一項進階的技巧。 除非有將資料表保留為堆積的特殊理由,否則大多數的資料表都應該選擇一個適合的叢集索引。
使用堆積的時機
堆積非常適合經常截斷和重載的數據表。 資料庫引擎會填入最早的可用空間,以優化堆積中的空間。
請考慮下列事項:
- 在堆積中尋找可用空間的成本可能很高,尤其是在有許多刪除或更新時。
- 叢集索引為不常截斷的數據表提供穩定的效能。
對於定期截斷或重新建立的數據表,例如臨時表或臨時表,使用堆積通常更有效率。
使用堆積和叢集索引之間的選擇,可能會大幅影響資料庫的效能和效率。
當資料表儲存為堆積時,參考會將各個資料列識別為 8 位元組資料列識別碼 (RID),該識別碼由檔案編號、資料頁碼及頁面上的位置 (FileID:PageID:SlotID) 所構成。 資料列識別碼是一種小型而高效率的結構。
堆積可用來作為未排序插入作業的大型暫存表格。 由於插入資料時不會強制執行嚴格的順序,因此插入作業通常會比同等的插入叢集索引作業快。 如果堆積的資料會讀取並處理到最終目的地,則建立包含讀取查詢所用搜尋述詞的窄小非叢集索引可能會很有用。
注意
資料會依資料頁的順序從堆積中擷取,但不一定是插入資料的順序。
當資料一律透過非叢集索引存取且 RID 比叢集索引鍵還小時,資料專業人員有時候也會使用堆積。
如果資料表為堆積且沒有任何非叢集索引,則必須讀取整份資料表 (資料表掃描) 才能找到資料列。 SQL Server 無法直接在堆積上尋找 RID。 當資料表很小時,此種方式是可接受的。
切勿使用堆積的情況
經常按排序順序傳回資料時,請勿使用堆積。 在排序資料行中的叢集索引,可免去進行排序作業。
當資料經常組合在一起時,請勿使用堆積。 資料組合前必須先排序,而在排序資料行中建立叢集索引,可免去排序作業。
經常要從資料表中查詢資料範圍時,請勿使用堆積。 在範圍資料行中若有叢集索引,可以免去排序整個堆積。
當沒有非叢集索引且數據表很大時,請勿使用堆積。 此設計的唯一應用程式是傳回整個數據表內容,而不需要任何指定的順序。 在堆積中,資料庫引擎 讀取所有數據列以尋找任何數據列。
如果經常更新資料,則請勿使用堆積。 如果您更新記錄,而該更新在資料頁中所使用空間比目前使用的還要更多,則必須將記錄移至具有足夠可用空間的資料頁。 此動作會建立一筆指向資料新位置的轉送記錄,且轉送指標必須寫入先前保留該資料的頁面中,以此指示新的實體位置。 這會採用堆積中的片段。 當 資料庫引擎 掃描堆積時,它會遵循這些指標。 此動作會限制讀取前的效能,而且可能會產生額外的 I/O,以減少掃描效能。
Managed 堆積
若要建立堆積,請建立不含叢集索引的資料表。 如果資料表中已有叢集索引,則請卸除叢集索引,將資料表還原為堆積。
若要移除堆積,請在堆積上建立叢集索引。
若要重建堆積以回收浪費的空間:
- 在堆積上建立叢集索引,然後卸除該叢集索引。
- 使用
ALTER TABLE ... REBUILD命令來重建堆積。
警告
建立或卸除叢集索引時必須重寫整份資料表。 若資料表具有非叢集索引,則一旦變更叢集索引之後,所有的非叢集索引都必須重建。 因此,在堆積與叢集索引結構之間的來回往返將會花費許多時間,且需要足夠的磁碟空間,才可在 tempdb 中重新排序資料。
識別堆積
下列查詢會從目前資料庫傳回堆積清單。 此清單包括:
- 資料表名稱
- 結構描述名稱
- 資料列數目
- KB 中的數據表大小
- KB 中的索引大小
- 未使用的空間
- 用來識別堆積的數據行
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
堆積結構
堆積是一種沒有叢集索引的資料表。 堆積的 sys.partitions中有一個資料列包含堆積所用之每一個資料分割的 index_id = 0 。 依預設,堆積只有一個資料分割。 當堆積有多個資料分割時,每個資料分割都有一個堆積結構來包含該特定資料分割的資料。 例如,如果堆積有四個資料分割,則有四個堆積結構;每個資料分割中各有一個堆積結構。
視堆積中的資料類型而定,每個堆積結構都會有一個或多個配置單位來儲存和管理特定資料分割的資料。 每個資料分割的每一個堆積至少會有一個 IN_ROW_DATA 配置單位。 若堆積包含大型物件 (LOB) 資料行,則每個資料分割在堆積中將會有一個 LOB_DATA 配置單位。 若堆積包含變數長度資料行,且其超過 8,060 個位元組的資料列大小限制,則每個資料分割的每個堆積也會有一個 ROW_OVERFLOW_DATA 配置單位。
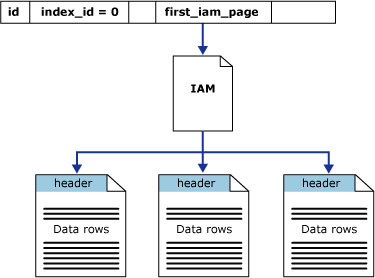
first_iam_page 系統檢視中的資料行 sys.system_internals_allocation_units 會指向 IAM 頁面鏈結中的的第一個 IAM 頁面。此頁面負責管理配置到特定資料分割中之堆積的空間。 SQL Server 使用 IAM 頁面在堆積中移動。 資料頁以及其中的資料列並沒有特定順序,也不會連結在一起。 資料頁之間的唯一邏輯連接為 IAM 頁面中所記錄的資訊。
重要
sys.system_internals_allocation_units 系統檢視僅保留供 SQL Server 內部使用。 我們無法保證未來的相容性。
堆積的資料表掃描或循序讀取可以藉著掃描 IAM 頁面找出包含堆積頁面的範圍來執行。 因為 IAM 會以範圍存在於檔案中的順序來表示它們,這代表循序的堆積掃描都將依檔案順序進行。 使用 IAM 分頁設定掃描順序也表示堆積中的資料列通常不會依插入順序傳回。
下圖顯示 SQL Server Database Engine 如何利用 IAM 頁面擷取單一資料分割堆積中的資料列。
相關內容
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
叢集與非叢集索引說明