適用於:![]() SQL Server 2016 (13.x)及以後版本
SQL Server 2016 (13.x)及以後版本 ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric 中的 SQL 資料庫
Microsoft Fabric 中的 SQL 資料庫
您可使用標準索引最佳化所有 JSON 文件的查詢。
Note
在 SQL Server 2025(17.x)中,您可以使用 CREATE JSON INDEX(Transact-SQL)功能。
針對 varchar/nvarchar 或 原生 json 資料類型的 JSON 資料,索引的運作方式相同。
資料庫索引可改善篩選和排序作業的效能。 若不使用索引,則 SQL Server 在您每次查詢資料時必須執行完整的資料表掃描。
Note
- 適用於具有 SQL Server 2025 或 隨時保持最新更新原則的 Azure SQL 資料庫和 Azure SQL 受控執行個體。
- 目前正處於 SQL Server 2025(17.x)的預覽版,並支援 Fabric 中的 SQL 資料庫。
使用計算資料行的索引 JSON 屬性
將 JSON 資料儲存於 SQL Server 時,通常都要依 JSON 文件的一或多個「屬性」來篩選或排序查詢結果。
Example
在此範例中,假設 AdventureWorks.SalesOrderHeader 資料表含有 Info 資料行,其中包含關於銷售訂單的各種資訊 (JSON 格式)。 例如,其中也包含客戶、銷售人員、收件和帳單地址等非結構化資料。 您可使用 Info 資料行的值來篩選客戶的銷售訂單。
根據預設,所使用的數據行 Info 不存在,可以使用下列程式代碼在 AdventureWorks 資料庫中建立。 下列範例不適用於 AdventureWorksLT 範例資料庫系列。
IF NOT EXISTS (SELECT *
FROM sys.columns
WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]')
AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader]
ADD [Info] NVARCHAR (MAX) NULL;
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c
ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p
ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
查詢最佳化
以下是要透過索引來最佳化的查詢類型的範例。
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell';
範例索引
若您想要針對 JSON 文件中的屬性加速篩選或 ORDER BY 子句處理,則可使用與其他資料行所用相同的索引。 不過,您無法「直接」參考 JSON 文件中的屬性。
- 首先,建立「虛擬資料行」來傳回要用於篩選的值。
- 然後,在該虛擬資料行建立索引。
下列範例會建立可用於索引的計算資料行。 然後它會在新的計算資料行上建立索引。 此範例會建立公開客戶名稱的資料行,其儲存於 JSON 文件中的 $.Customer.Name 路徑。
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info, '$.Customer.Name');
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName);
此陳述會傳回下列警告:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
例如,JSON_VALUE 函數可能會傳回最多 8000 個位元組的文字值 (例如 nvarchar(4000) 類型)。 不過,長度超過 1700 個字節的值無法編製索引。 如果您嘗試在超過 1700 個字節的索引計算數據行中輸入值,則數據作語言 (DML) 作業會失敗。
為了獲得更佳的效能,請嘗試將您已使用計算資料行公開的值,轉換成最小的適用資料類型。 使用 int 和 datetime2 類型,而不是字串類型。
計算資料行的詳細資訊
計算欄位不會被儲存。 只有在需要重建索引時,才會計算計算欄位。 它不會佔用數據表中的其他空間。
請務必使用您計劃在查詢中所用的相同運算式,建立計算資料行 - 在此範例中,運算式為 JSON_VALUE(Info, '$.Customer.Name')。
您無須重寫查詢。 若您使用具有 JSON_VALUE 函式的運算式 (如之前的範例查詢所示),則 SQL Server 會發現有一個具有相同運算式的同等計算資料行,並盡可能套用索引。
此範例中的執行計畫
以下是此範例中的查詢執行計畫。
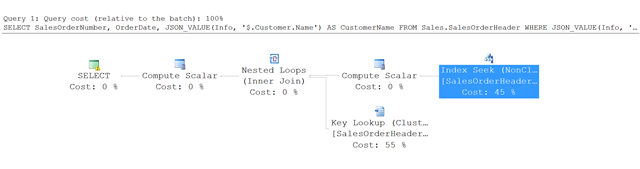
SQL Server 會使用索引搜尋非叢集索引,並尋找滿足指定條件的資料列,而不會掃描整個資料表。 接著,伺服器會在 SalesOrderHeader 資料表中使用索引鍵查詢,以擷取查詢中參考的其他資料行,在此範例中為 SalesOrderNumber 和 OrderDate。
使用包含的資料行進一步優化索引
如果您在索引中新增必要的數據行,則可以避免在數據表中進行這種額外的查閱。 您可新增這些資料行作為標準內含資料行 (如下列範例所示),以擴充之前的 CREATE INDEX 範例。
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber, OrderDate);
在此情況下,SQL Server 不需要從 SalesOrderHeader 數據表讀取更多數據,因為它所需的一切都包含在非叢集 JSON 索引中。 此索引類型是在查詢中合併 JSON 與資料行資料,以及針對工作負載建立最佳化索引的理想方法。
JSON 索引是感知定序的索引
JSON 資料索引的一個重要特性是索引具備排序感知能力。 您在建立計算資料行時所使用的 JSON_VALUE 函數的結果為文字值,其繼承來自輸入運算式的定序。 因此,在索引中的值會使用來源資料行中定義的定序規則加以排序。
為了示範索引能夠感知定序,下列範例會建立具有主索引鍵與 JSON 內容的簡單集合資料表。
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR (MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON] CHECK (ISJSON(json) > 0)
);
上述命令會針對 json 欄指定塞爾維亞文西里爾字母定序。 下列範例會在名稱屬性上填入資料表並建立索引。
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}');
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json, '$.name');
CREATE INDEX idx_name
ON JsonCollection(vName);
上述命令會在計算資料行 vName 上建立標準索引,其代表來自 JSON $.name 屬性的值。 在塞爾維亞文 (斯拉夫) 字碼頁中,字母順序如下:А、Б、В、Г、Д、Ђ、Е 等等。索引中的項目順序會與塞爾維亞文 (斯拉夫) 規則相容,這是因為 JSON_VALUE 函數的結果會繼承其來自來源資料行的定序。 下列範例會查詢此集合物件,並依名稱排序結果。
SELECT JSON_VALUE(json, '$.name'),
*
FROM JsonCollection
ORDER BY JSON_VALUE(json, '$.name');
若您查看實際執行計劃,會發現其使用來自非叢集索引的排序值。

雖然查詢具有 ORDER BY 子句,但執行計畫不會使用 Sort 運算子。 JSON 索引已根據塞爾維亞西里尔字母規則執行排序。 因此,SQL Server 可在結果已排序的情況下,使用非叢集索引。
不過,若您變更 ORDER BY 運算式的定序 (例如在 COLLATE French_100_CI_AS_SC 函式後方新增 JSON_VALUE),則會得到不同的查詢執行計畫。

由於索引中的值順序不符合法文定序規則,因此 SQL Server 無法使用索引來排序結果。 因此,會新增一個 Sort 運算子,使用法文定序規則來排序結果。
Microsoft 影片
如需內建 JSON 支援的視覺效果簡介,請參閱下列影片: