讀取分頁
適用於:![]() SQL Server
SQL Server
SQL Server 資料庫引擎執行個體中的 I/O 包括邏輯和實體讀取。 每當資料庫引擎向緩衝快取要求分頁時,便會發生邏輯讀取。 如果頁面目前不在緩衝快取中,實體讀取會先從磁碟複製頁面到快取中。
Database Engine 執行個體所產生的讀取要求,是由關聯式引擎所控制,並由儲存引擎最佳化。 關聯式引擎會決定最有效的存取方法 (例如資料表掃描、索引掃描或索引讀取);儲存引擎的存取方法和緩衝區管理員元件會決定一般讀取模式,以執行並最佳化實作存取方法所需的讀取。 執行批次的執行緒會排程讀取。
預先讀取
資料庫引擎支援稱為「預先讀取」的效能最佳化機制。 預先讀取會預先準備執行 查詢執行計畫所需的資料和索引頁,並在查詢實際使用頁面之前,將之帶入緩衝快取。 這將允許計算與 I/O 重疊,達到充分利用 CPU 和磁碟的目的。
預先讀取機制允許資料庫引擎從一個檔案最多讀取 64 個連續頁面 (512 KB)。 讀取的執行方式是在緩衝快取中,針對適當數目的 (可能不連續的) 緩衝區進行單一散佈與收集讀取。 如果範圍中的任何頁面已經存在於緩衝快取,則會在讀取完成時捨棄讀取的對應頁面。 如果對應的頁面已經存在於快取中,也可能會從兩端「刪減」頁面的範圍。
有兩種類型的預先讀取:一個用於資料頁,另一個用於索引頁。
讀取資料頁
用來讀取資料頁的資料表掃描,在資料庫引擎中非常有效率。 SQL Server 資料庫中的索引配置對應 (IAM) 頁面會列出資料表或索引所使用的範圍。 儲存引擎可以讀取 IAM,以建立必須讀取之磁碟位址的排序清單。 如此可讓儲存引擎根據磁碟上的讀取位置,將其 I/O 最佳化為在序列中執行的大型循序讀取。 如需關於 IAM 頁面的詳細資訊,請參閱 管理由物件所使用的空間。
讀取索引頁
儲存引擎會依照索引鍵順序循序讀取索引頁。 例如,下圖所示為一組簡化的分葉頁,分頁上含有一組索引鍵值,以及對應分葉頁的中繼索引節點。 如需有關索引中分頁結構的詳細資訊,請參閱 叢集索引結構。
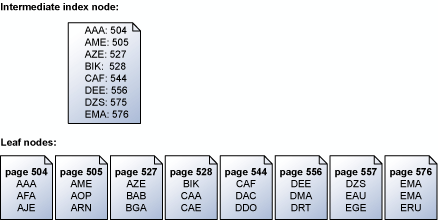
儲存引擎使用分頁層級以上中繼索引頁中的資訊,排程包含索引鍵之頁面的序列預先讀取。 如果要求 ABC 到 DEF 之間的所有索引鍵值,則儲存引擎會先讀取分葉頁以上的索引頁。 不過,它不只會依序讀取第 504 到 556 分頁 (在指定範圍內有索引鍵值的最後一頁) 間的每個資料頁。 否則,儲存引擎會掃描中繼索引頁,然後建立必須讀取之分葉頁的清單。 儲存引擎接著依索引鍵值順序排程所有的讀取。 同時儲存引擎也識別出 504/505 和 527/528 頁是連續的,並執行單一的散佈與收集讀取,來擷取某個單一作業中的相鄰分頁。 當序列作業中有許多要擷取的分頁時,儲存引擎會一次排程一個讀取區塊。 當這些讀取的子集完成時,儲存引擎會排程同樣數目的新讀取,直到全部所需的讀取皆完成排程為止。
儲存引擎使用預先提取加速對非叢集索引的基底資料表查閱。 非叢集索引的葉資料列包含指向內含各特定索引鍵值之資料列的指標。 當儲存引擎讀完非叢集索引的分葉頁時,它也會開始排定已擷取資料指標之資料列的非同步讀取。 這使儲存引擎能夠在完成非叢集索引的掃描前就開始從基礎資料表中擷取資料列。 不論資料表有沒有叢集索引,都會使用預先提取。 SQL Server Enterprise 會比其他 SQL Server 版本使用更多的預先提取,以便預先讀取更多的分頁。 預先提取的層級無法在任何版本中設定。 如需有關非叢集索引的詳細資訊,請參閱 非叢集索引結構。
進階掃描
在 SQL Server Enterprise 中,進階掃描功能允許多個工作共用完整資料表掃描。 如果 Transact-SQL 陳述式的執行計畫需要掃描資料表中的資料頁,而資料庫引擎偵測到該資料表已經由另一項執行計畫進行掃描,資料庫引擎會在第二個掃描的目前位置上將第二個掃描聯結至第一個掃描。 資料庫引擎一次會讀取一頁,並將每個分頁的資料列同時傳送給這兩項執行計畫。 這樣一直繼續到資料表結束為止。
到那時候,第一個執行計畫已取得掃描的完整結果,但第二個執行計畫還必須擷取與進行中掃描聯結之前的資料頁。 所以第二個執行計畫的掃描會繞回資料表的第一個資料頁,然後往前掃描,直到與第一個掃描聯結那一點。 任何數量的掃描都可以如上述結合。 資料庫引擎將會持續對資料頁進行迴圈,直到完成所有掃描為止。 這個機制也稱為「旋轉木馬式掃描」,並且示範為什麼不使用 ORDER BY 子句,就無法保證從 SELECT 陳述式傳回之結果的順序。
例如,假設有一個 500,000 個分頁的資料表。 UserA 執行需要掃描資料表的 Transact-SQL 陳述式。 當該掃描處理過 100,000 個分頁後,UserB 執行另一個掃描同一資料表的 Transact-SQL 陳述式。 資料庫引擎會排定一組讀取要求,讀取 100,001 以後的分頁,並將每個分頁的資料列同時傳回給兩個掃描。 等掃描到達第 200,000 個分頁時,UserC 執行另一個掃描同一資料表的 Transact-SQL 陳述式。 所以從第 200,001 個分頁起,資料庫引擎會將每個分頁的資料列傳回給三個掃描。 讀取了第 500,000 個分頁之後,UserA 的掃描已完成,而 UserB 和 UserC 的掃描會繞回並從第 1 頁開始讀取分頁。 當資料庫引擎到達第 100,000 個分頁時,UserB 的掃描便完成。 UserC 的掃描於是獨自繼續進行,直到讀取第 200,000 頁為止。 這個時候,就完成了所有的掃描。
如果沒有進階掃描,每個使用者都必須爭取緩衝區空間,而造成競爭磁碟讀寫臂的情況。 所以每個使用者都會各讀取同一頁面一次,而不是只讀取一次,再由多個使用者共用,如此會降低效能並消耗資源。