適用於:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric 中的 SQL 資料庫
Microsoft Fabric 中的 SQL 資料庫
作業系統工作排程
執行緒是作業系統可以執行的最小處理單位,可讓應用程式邏輯分成數個同時執行路徑。 當複雜應用程式有許多可同時執行的工作時,執行緒就很實用。
作業系統執行應用程式的執行個體時,會建立一個稱為處理序的單位來管理這個執行個體。 程序包含一個執行緒。 這是應用程式的程式碼所執行的程式化指令序列。 例如,若簡單應用程式具有能依序執行的單一指令集,系統會以單一工作方式處理該指令集,而且整個應用程式中只有一個執行路徑 (或執行緒)。 較為複雜的應用程式可能會有多個能同時 (而非依序) 執行的工作。 若要這樣做,應用程式可以為每個工作啟動個別處理序 (不過這是資源密集作業),或啟動個別執行緒 (相較之下較不資源密集)。 另外,每個執行緒都可以獨立於與處理序相關聯的其他執行緒來排程執行。
執行緒可讓複雜應用程式以更有效率的方式使用處理器 (CPU),甚至在具有單 CPU 的電腦上也一樣。 只有一個 CPU 時,一次只能執行一個執行緒。 如果有一個執行緒執行不需使用 CPU 的長時間作業,像是磁碟讀寫,另一個執行緒便可以一直執行,直到第一個作業完成為止。 由於應用程式可在其他執行緒等待作業完成時執行一些執行緒,所以使 CPU 發揮最大功效。 特別是多使用者、需要大量磁碟 I/O 的應用程式 (例如資料庫伺服器) 更是如此。 有多個 CPU 的電腦可同時讓每個 CPU 執行一個執行緒。 例如,如果一部電腦有 8 個 CPU,就可以同時執行 8 個執行緒。
SQL Server 工作排程
在 SQL Server 的範圍中,要求是查詢或批次的邏輯表示法。 要求也代表系統執行緒所需的操作,例如檢查點或日誌寫入器。 請求在其整個生命週期中會處於各種狀態,當執行請求所需的資源(例如鎖定或閂鎖)不可用時,可以累積等待時間。 如需有關要求狀態的詳細資訊,請參閱 sys.dm_exec_requests。
任務
工作代表必須完成以滿足要求的工作單位。 您可以將一或多個任務指派給單一要求。
- 平行請求有多個任務是並行執行的,而不是以序列方式執行,其中包括一個父工作(或協調工作)和多個子工作。 平行要求的執行計畫可能會包含串行分支,即計畫中的某些區域包含不平行執行的運算子。 父任務也負責執行這些序列運算符。
- 在執行期間,序列要求在任何指定的時間點都只會有一個活動中任務。 任務在其整個生命周期中以各種狀態存在。 如需有關工作狀態的詳細資訊,請參閱 sys.dm_os_tasks。 處於「暫停」狀態的工作正在等候執行工作所需資源成為可用。 如需等候中工作的詳細資訊,請參閱 sys.dm_os_waiting_tasks。
工人
SQL Server 工作執行緒 (也稱為工作執行緒或執行緒) 是作業系統執行緒的邏輯表示法。 當執行序列要求時,SQL Server 資料庫引擎會啟動工作執行緒以執行作用中工作 (1:1)。 當執行平行要求於列模式時,SQL Server 資料庫引擎會指派一個工作執行緒來協調那些負責完成受指派工作的子工作執行緒(也是 1:1),稱為父執行緒(或協調執行緒)。 父執行緒具有與其建立關聯的父工作。 父執行緒是要求的進入點,在引擎剖析查詢之前即已存在。 父執行緒的主要責任如下:
- 協調平行掃描。
- 啟動子平行工作者。
- 從平行執行緒收集資料列,並傳送至用戶端。
- 執行本機和全域彙總。
注意
如果查詢計劃有序列和平行分支,則其中一項平行工作會負責執行序列分支。
為每個任務產生的工作執行緒數目取決於:
要求是否符合平行處理原則的資格 (由查詢最佳化工具判斷)。
根據目前的工作負載,系統中實際可用的平行處理度 (DOP) 為何。 這可能會與預估 DOP 有所差異,後者是以平行處理原則的最大程度 (MAXDOP) 伺服器組態為基礎。 例如,MAXDOP 伺服器組態選項可能是 8,執行階段的可用 DOP 只能是 2,這會影響查詢效能。 記憶體壓力和工人不足是運行期間降低可用 DOP 的兩個條件。
注意
平行處理原則的最大程度 (MAXDOP) 限制是以個別工作 (而非個別要求) 為基礎所設定的。 這表示在平行查詢執行期間,(在 MAXDOP 限制下)單一要求可以衍生出多個任務,且每個任務都會使用一個工作執行緒。 如需有關 MAXDOP 的詳細資訊,請參閱 設定 max degree of parallelism 伺服器組態選項。
排程器
排程器(亦稱為 SOS 排程器)負責管理工作執行緒,這些執行緒需要處理時間來代表任務執行工作。 每個排程器被映射到各自的處理器 (CPU)。 在排程器中一個工作者可以維持作用的時間稱為作業系統配量,其最大值為 4 毫秒。 在經過其量子時間後,工作者會將其時間讓給其他需要存取 CPU 資源的工作者,並變更其狀態。 工人之間的合作以最大化 CPU 資源存取的機制稱為合作式排程,亦稱為非先佔式排程。 接著,工作者狀態的變更會傳播到與該工作者關聯的工作,並且傳播到與該工作關聯的請求。 如需有關工作者狀態的詳細資訊,請參閱 sys.dm_os_workers。 如需有關排程器的詳細資訊,請參閱 sys.dm_os_schedulers。
總結來說,要求可能會產生一個或多個任務以執行特定的工作單元。 每個任務都會指派給負責完成此任務的工作執行緒。 每個工作執行緒都必須排程 (放置在排程器上) 才能執行任務。
請考慮下列案例:
- 工作執行緒 1 是長時間運行的任務,例如在以磁碟為基礎的資料表上進行讀取預先讀取的查詢。 工作者 1 發現所需的資料頁已經存在於緩衝集區中,因此不需要讓出資源去等待 I/O 作業,並且可以在需要讓出之前使用其完整的執行時間配額。
- 工作者 2 執行短於一毫秒的任務,因此必須在其完整的配量耗盡之前讓步。
在此情境中,直到 SQL Server 2014 (12.x),工作者 1 基本上可以透過擁有更多的整體量子時間來獨佔排程器。
從 SQL Server 2016 (13.x) 開始,協作排程包括大型虧額優先 (LDF) 排程。 在使用 LDF 排程時,量子使用模式會被監控,並且單一工作執行緒不會獨佔一個排程器。 在相同的情況下,背景工作角色 2 可以在背景工作角色1 取用更多配量之前取用重複配量,因此可防止背景工作角色 1 在不友善的模式下獨佔排程器。
平行工作排程
假設 SQL Server 以 MaxDOP 8 設定,且 CPU 親和性設為跨 NUMA 節點 0 和 1 的 24 個 CPU (排程器)。 排程器 0 到 11 屬於 NUMA 節點 0,而排程器 12 到 23 屬於 NUMA 節點 1。 應用程式會將下列查詢 (要求) 傳送至資料庫引擎:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
提示
您可使用 AdventureWorks2016_EXT 範例資料庫 資料庫來執行範例查詢。 資料表 Sales.SalesOrderHeader 和 Sales.SalesOrderDetail 已擴大了 50 倍,並已重新命名為 Sales.SalesOrderHeaderBulk 和 Sales.SalesOrderDetailBulk。
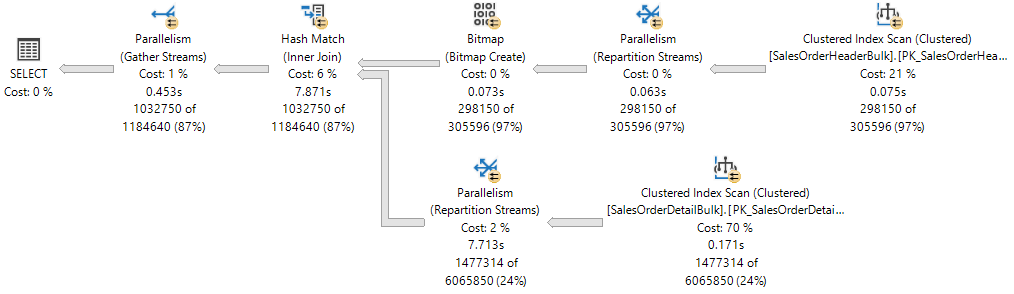
執行計畫會顯示兩個資料表之間的雜湊聯結,且每個運算子會以平行方式執行,如具有兩個箭號的黃色圓圈所指示。 每個平行處理原則運算子都是計畫中的不同分支。 因此,下列執行計畫中有三個分支。
注意
如果將執行計畫視為樹狀結構,則分支就是計畫的一個區域,其可在平行處理原則運算子 (也稱為交換迭代器) 之間將一或多個運算子分組。 如需有關方案運算子的詳細資訊,請參閱Showplan 邏輯和實體運算子參考。
雖然執行計畫中有三個分支,但在執行期間的任何時間點,只能在此執行計畫中同時執行兩個分支:
- 在聯結的組建輸入上使用叢集索引掃描的分支會單獨執行。
- 然後,使用「叢集索引掃描」的分支(聯結的探查輸入)會與建立「點陣圖」且目前正在執行「雜湊比對」的分支同時執行。
NUMA 節點 0 的 Showplan XML 顯示已保留並使用了 16 個工作執行緒:
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
執行緒保留可確保資料庫引擎擁有足夠背景工作執行緒,以執行要求所需的所有工作。 您可在數個 NUMA 節點上保留執行緒,也可以只保留在一個 NUMA 節點中。 執行緒保留會在程式運行之前於執行時完成,並相依於排程器的負載。 保留的背景工作執行緒數目通常衍生自公式 concurrent branches * runtime DOP,並排除父系背景工作執行緒。 每個分支都會受限於等同於 MaxDOP 的工作執行緒數目。 在此範例中有兩個平行分支,而 MaxDOP 設為 8,因此 2 * 8 = 16。
如需參考,請觀察即時查詢統計資料中的即時執行計畫,其中一個分支已完成,且兩個分支同時執行。
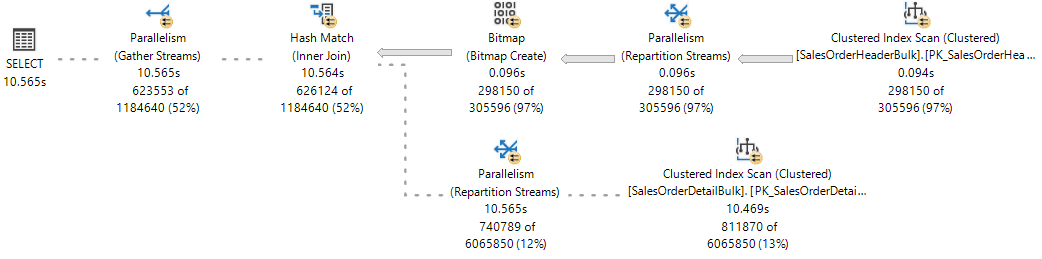
SQL Server 資料庫引擎會指派工作執行緒來執行作用中的工作 (1:1),可以在查詢執行時,透過查詢 sys.dm_os_tasks DMV 來觀察,如該範例所示:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
提示
父任務的資料行 parent_task_address 始終為 null。
提示
您可能會在非常忙碌的 SQL Server 資料庫引擎上,看到作用中工作數目超過保留執行緒所設定的限制。 這些工作可能屬於已不再使用的分支,且處於暫時性狀態,等待著清除作業。
結果集如下所示。 請注意,目前正在執行的分支有 17 個活動中的任務:對應至預留的執行緒的 16 個子任務,加上父任務或協調任務。
| 母任務位址 | 任務_地址 | 任務狀態 | 排程器_識別碼 | 員工地址 |
|---|---|---|---|---|
| 零 | 0x000001EF4758ACA8 |
已暫停 | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | 已暫停 | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | 已暫停 | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | 已暫停 | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | 已暫停 | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | 已暫停 | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | 已暫停 | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | 已暫停 | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | 已暫停 | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | 已暫停 | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | 已暫停 | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | 已暫停 | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | 已暫停 | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | 已暫停 | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | 已暫停 | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | 已暫停 | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | 已暫停 | 11 | 0x000001EF6BD72160 |
請觀察這 16 個子任務每一個都被指派了不同的工作執行緒(在 worker_address 資料行中可見),但所有工人都被分配到相同的 8 個排程器池 (0、5、6、7、8、9、10、11),而父母任務被分配到此池外的一個排程器 (3)。
重要
當在特定分支上排程了第一組平行任務後,資料庫引擎將使用同一個排程器集區來處理其他分支上的任何額外任務。 這表示同一組排程器會用於整個執行計畫中的所有平行工作,只受限於 MaxDOP。
SQL Server 資料庫引擎一律會嘗試從相同的 NUMA 節點指派排程器以執行工作,並在排程器可供使用時,(以循環配置資源的方式) 依序指派排程器。 不過,指派給父任務的工作執行緒,可能會位於與其他任務不同的 NUMA 節點中。
工作執行緒只能在其配量的持續時間(4 毫秒)於排程器中維持作用中狀態,且在該配量結束後必須讓出排程器,以便讓指派給其他任務的工作執行緒能成為作用中狀態。 當一個工作程序的時間片過期且不再活躍時,該工作將被置於 FIFO 佇列中,以 RUNNABLE 狀態等待,直到再次進入 RUNNING 狀態。假設工作不需要存取此時不可用的資源(例如閂鎖或鎖),否則,該工作將進入 SUSPENDED 狀態,而不是 RUNNABLE,直到這些資源可用為止。
提示
如上所見 DMV 的輸出中,所有活動中的任務均處於 SUSPENDED 狀態。 如需等候工作的詳細資料,請查詢 sys.dm_os_waiting_tasks DMV。
總而言之,平行要求會產生多項工作。 每項工作都必須指派給單一的工作執行緒。 每個工作執行緒都必須指派給單一排程器。 因此,每個分支的使用中排程器數目不能超過平行工作數目,此數目由 MaxDOP 組態或查詢提示所設定。 協調執行緒不會算在 MaxDOP 的限制中。
CPU 的執行緒配置
根據預設,SQL Server 的每個執行個體會啟動每個執行緒,且作業系統會根據負載從 SQL Server 的執行個體,將執行緒散發給電腦上的處理器 (CPU)。 如果已在作業系統層級啟用處理序親和性,則作業系統就會將每個執行緒指派給特定的 CPU。 相反地,SQL Server 資料庫引擎會將背景工作執行緒指派給排程器,以便將這些執行緒平均分配給 CPU。
為了執行多工作業 (例如當多個應用程式存取一組相同的 CPU 時),作業系統有時會在不同的 CPU 之間移動背景工作執行緒。 雖然從作業系統的觀點來看很有效率,但是在繁重的系統負載下,此活動可能會降低 SQL Server 效能,因為每個處理器快取都會重複地重新載入資料。 在這些情況中,將特定執行緒指定給 CPU,可降低處理器重新載入的情形並減少跨 CPU 移轉執行緒的問題 (藉此減少內容切換),進而提升效能,而執行緒與處理器之間的關聯則稱為處理器同質性。 如果已經啟用相似性,作業系統就會將每個執行緒指派給特定的 CPU。
親和性遮罩選項是使用 ALTER SERVER CONFIGURATION 設定的。 未設定親和性遮罩時,SQL Server 執行個體會將工作執行緒均勻分配給尚未遮罩的排程器。
警告
請勿在作業系統中設定 CPU 親和性,同時在 SQL Server 中設定親和性遮罩。 這些設定嘗試達到相同的結果,如果組態不一致,可能會有無法預期的結果。 如需詳細資訊,請參閱親和性遮罩選項。
當大量用戶端連接到伺服器時,執行緒集區有助於最佳化效能。 通常,會針對每一個查詢要求建立個別的作業系統執行緒。 然而,在數以百計的伺服器連接之下,若每個查詢要求都使用一個執行緒,反而會耗用大量的系統資源。 背景工作執行緒上限選項可讓 SQL Server 建立背景工作執行緒集區,以服務更多的查詢要求數量,進而改善效能。
使用輕量型共用選項
重要
自 SQL Server 2025(17.x)起,該選項啟用的lightweight pooling功能已被棄用,並計劃在未來版本的 SQL Server 中移除。 由於已知的穩定性和相容性問題,Microsoft 建議您避免在任何版本的 SQL Server 中使用這項功能。
切換執行緒內容所需的額外負荷可能不會太大。 SQL Server 大部分的執行個體,在將輕量型共用選項設為 0 或 1 時並不會察覺到任何效能上的差異。 只有擁有下列特性之電腦上的 SQL Server 執行個體,才有可能感受到 輕量型共用 的好處:
- 具有多個 CPU 的大型伺服器
- 所有 CPU 皆以接近最大容量在執行
- 高頻率的情境切換
這些系統在將輕量型共用值設定為 1 時,可能會發現效能有稍微增加。
重要
請勿針對例行作業使用 Fiber 模式排程。 這可能會抑制一般內容切換的好處而降低效能,且 SQL Server 的某些元件無法在 Fiber 模式中正確運作。 如需詳細資訊,請參閱輕量型共用。
執行緒和纖程執行
Microsoft Windows 使用數值優先權系統,從 1 到 31 的範圍來排程要執行的執行緒。 數字0是預留給作業系統使用的。 當有數個執行緒等待執行時,Windows 會先分派有最高優先順序的執行緒。
根據預設,每個 SQL Server 執行個體的優先權為 7,這稱為一般優先權。 這讓 SQL Server 執行緒有夠高的優先權,可以取得足夠的 CPU 資源,而不會影響其他的應用程式。
重要
SQL Server 的未來版本將移除此功能。 請避免在新的開發工作中使用這項功能,並規劃修改目前使用這項功能的應用程式。
使用 優先權提升 設定選項,可以將 SQL Server 執行個體中執行緒的優先權增加至 13。 這稱為高優先權。 這個設定讓 SQL Server 執行緒擁有比大部份其他應用程式更高的優先權。 因此,每當 SQL Server 執行緒準備好執行時,一般會進行分派,且不會被其他應用程式的執行緒搶先中斷。 當伺服器僅執行 SQL Server 的執行個體,而沒有執行其他應用程式時,可以改善系統的效能。 不過,如果 SQL Server 中發生需要大量記憶體的作業,則其他應用程式可能無法擁有夠高的優先權以預先清空 SQL Server 執行緒。
如果您在電腦上執行多個 SQL Server 執行個體,並且僅提高部份執行個體的優先權,則以一般優先權執行的所有執行個體之效能都將受到影響。 另外,如果有開啟優先權提升,就可能會降低伺服器上其他應用程式與元件的效能。 因此,它應該在嚴格控制的情況下使用。
熱插拔 CPU
重要
自 SQL Server 2025(17.x)起,熱加 CPU 功能被棄用,並計劃在未來版本的 SQL Server 中移除。 由於已知的穩定性問題,Microsoft建議您避免在任何版本的 SQL Server 管理中使用此功能。
熱插入 CPU 是指將 CPU 動態添加到運行中系統的功能。 新增 CPU 可發生於實體上新增硬體、邏輯上進行線上硬體分割或是虛擬上透過虛擬化層時。
熱新增 CPU 的需求:
- 需要支援熱插拔CPU的硬體。
- 需要支援的 Windows Server Datacenter 或 Enterprise 版本。 從 Windows Server 2012 開始,Standard 版本支援熱新增。
- 需要 SQL Server Enterprise 版本。
- SQL Server 無法設定為使用軟體 NUMA。 如需有關軟體 NUMA 的詳細資訊,請參閱 軟體 NUMA (SQL Server)。
SQL Server 不會在新增 CPU 之後自動使用這些 CPU。 這樣可避免 SQL Server 使用可能要供其他用途使用而新增的 CPU。 新增 CPU 之後,請執行 RECONFIGURE 語句,讓 SQL Server 將新的 CPU 辨識為可用的資源。
如果設定了 affinity64 mask ,則必須修改 affinity64 mask 才能使用新的 CPU。
在具備超過 64 顆 CPU 之電腦上執行 SQL Server 的最佳做法
將硬體執行緒指派給 CPU
請勿使用 affinity mask 和 affinity64 mask 伺服器組態選項,將處理器繫結至特定執行緒。 這些選項僅限於 64 個 CPU。 改為使用 SET PROCESS AFFINITY 的 選項。
交易記錄檔大小管理
請勿仰賴自動成長來增加交易記錄檔的大小。 增加交易日志必須是按序列進行的處理。 擴充記錄可避免在記錄擴充完成之前繼續進行交易寫入作業。 不過,您可以將檔案大小設定為夠大的值來支援環境中的典型工作負載,藉此為所有記錄檔預先配置空間。
設定索引操作的最大平行處理度
在具有許多 CPU 的電腦上,您可以暫時將資料庫的復原模式設定為大量記錄或簡單復原模式,藉此改善建立或重建索引等索引作業的效能。 這些索引作業可能會產生重要的記錄活動,而且記錄競爭可能會影響 SQL Server 所選擇之平行處理原則的最佳程度 (DOP)。
此外,若要調整平行處理原則的最大程度 (MAXDOP) 伺服器組態選項,請考慮使用 MAXDOP 選項 調整索引作業的平行處理原則。 如需詳細資訊,請參閱 設定平行索引作業。 如需有關調整平行處理原則的最大程度伺服器組態選項的詳細資訊,請參閱設定平行處理原則的最大程度伺服器組態選項。
工作執行緒數目最大值選項
SQL Server 將會在啟動時動態設定背景工作執行緒上限伺服器組態選項。 SQL Server 在啟動時使用可用 CPU 數目與系統架構 (使用記載的公式) 來判斷此伺服器組態。
此選項是進階選項,只能由經驗豐富的資料庫專業人員變更。
如果您懷疑出現效能問題,那很可能不是因為工作執行緒的可用性。 問題較可能是 I/O 等操作使工作執行緒進入等待狀態。 建議您在變更背景工作執行緒設定的上限前,先找出效能問題的根本原因。 不過,如果您需要手動設定背景工作執行緒數目上限,則此設定值必須一律至少設定為系統上出現的 CPU 數目的七倍。 如需詳細資訊,請參閱 設定最大工作者執行緒。
請避免使用 SQL 追蹤和 SQL Server Profiler
建議您不要在生產環境中使用 SQL 追蹤和 SQL Profiler。 執行這些工具的負擔也會隨著 CPU 數目增加而提高。 如果您必須在實際執行環境中使用 SQL 追蹤,請將追蹤事件的數目限制為最小值。 請仔細地在負載下分析和測試每個追蹤事件,並且避免使用會顯著影響效能的事件組合。
重要
SQL 追蹤和 SQL Server Profiler 已被廢止。 包含 SQL Server 追蹤和重新執行物件的 Microsoft.SqlServer.Management.Trace 命名空間也會被淘汰。
SQL Server 的未來版本將移除此功能。 請避免在新的開發工作中使用這項功能,並規劃修改目前使用這項功能的應用程式。
改用Extended Events。 如需延伸事件的詳細資訊,請參閱快速入門:SQL Server 中的延伸事件和 SSMS XEvent 分析工具。
注意
適用於 Analysis Services 工作負載的 SQL Server Profiler「未」遭淘汰,而且將會繼續受支援。
設定 tempdb 資料檔案數量
檔案數目取決於電腦上 (邏輯) 處理器的數目。 一般而言,如果邏輯處理器的數目小於或等於 8,請使用與邏輯處理器數目相同的資料檔案數目。 如果邏輯處理器的數目大於 8,請使用 8 個資料檔案,要是競爭的情況仍持續發生,請以 4 的倍數增加資料檔案數目,直到競爭縮減到可接受的程度;或是對工作負載/程式碼進行變更。 也請記住有關 tempdb 的其他建議,您可於將 SQL Server 中的 tempdb 效能最佳化中找到。
不過,只要仔細地考量 tempdb 的並行需求,您就可以減少資料庫管理作業額外負荷。 例如,如果系統具有 64 個 CPU 而且通常只有 32 個查詢使用 tempdb,那麼將 tempdb 檔案的數目增加至 64 並不會改善效能。
可以使用超過 64 個 CPU 的 SQL Server 元件
下表將列出 SQL Server 元件並指出它們是否能使用超過 64 個 CPU。
| 程序名稱 | 可執行的程式 | 使用超過 64 個 CPU |
|---|---|---|
| SQL Server 資料庫引擎 | Sqlserver.exe | 是 |
| 報告服務 | Rs.exe | 否 |
| Analysis Services | As.exe | 否 |
| 整合服務 | Is.exe | 否 |
| 服務代理 | Sb.exe | 否 |
| 全文檢索 | Fts.exe | 否 |
| SQL Server Agent(SQL伺服器代理) | Sqlagent.exe | 否 |
| SQL Server 管理工作室 | Ssms.exe | 否 |
| SQL Server 設定安裝 | Setup.exe | 否 |