了解文字分析
在探索 Azure AI 語言服務的文字分析功能之前,讓我們先檢查一些用來執行文字分析和其他自然語言處理 (NLP) 工作的一般原則和常見技術。
一些最早使用電腦來分析文字的技術涉及對文字文本 (主體) 的統計分析,以推斷某種語意意義。 簡單來說,如果您可以判斷指定文件中最常用的單字,您通常可以良好地瞭解該文件的內容。
語彙基元化
分析主體的第一個步驟是將之細分成 語彙基元。 簡單起見,您可以將訓練文字中的每個不同字視為一個語彙基元,但實際上,語彙基元可以針對部分單字產生,或單字和標點符號的組合。
例如,考量這句出自知名美國總統演講的語句:「we choose to go to the moon (我們選擇登月)」。 該語句可以細分成下列語彙基元,並具有數值識別碼:
- we
- 選擇
- 打給
- GO
- the
- moon (月)
請注意,「to」(語彙基元編號 3) 在主體中使用了兩次。 語句「we choose to go to the moon (我們選擇登月)」可以由語彙基元 [1,2,3,4,3,3,5,6] 表示。
注意
我們已使用簡單的範例,其中識別了文字中每個不同單字的語彙基元。 不過,請考慮下列可能適用於語彙基元化的概念,視您嘗試解決的特定 NLP 問題類型而定:
- 文字正規化:在產生語彙基元之前,您可以選擇移除標點符號,並將所有單字變更為小寫,以 正規化 文字。 針對完全依賴文字頻率的分析,此方法可改善整體效能。 然而,某些語意意義可能會遺失,例如,請考量句子「Mr Banks has worked in many banks. (班克斯先生曾就職於許多銀行。)」。 您可能希望您的分析能區分 [Mr Banks (班克斯先生)] 和他就職過的 [banks (銀行)]。 您可能也會考慮將「banks. (銀行。)」 視為與「banks (銀行)」不同的語彙基元,因為包含句號提供了該單字出現在句子結尾的資訊
- 停止字組移除。 Stop words 是應從分析中排除的單字。 例如,「the (定冠詞)」、「a (不定冠詞)」 或 「it (虛主詞/虛受詞)」等單字可讓文字更易於人們閱讀,但幾乎沒有增加語意含義。 藉由排除這些單字,文字分析解決方案可能更能識別重要的單字。
- n-gram 是多詞彙的片語,例如 "I have" 或 "he walked"。 一個單字的片語是 unigram (單詞項)、兩個單字的片語是 bi-gram (雙詞項)、三個單字的片語是 tri-gram (三詞項),以此類推。 藉由將單字視為群組,機器學習模型可以更瞭解文字。透過將單字視為群組,機器學習模型可以更完善地理解文字。
- 字幹分析 (Stemming) 是一種技術,在計算單字之前,會應用演算法對單字進行合併,以便將根詞相同的單字,如「power」、「powered」和「powerful」解譯為同一個語彙基元。
頻率分析
將單字語彙基元化之後,您可以執行一些分析,來計算每個語彙基元的出現次數。 最常用的單字 (除了 停用詞,如「a (不定冠詞)」、「the (定冠詞)」等) 通常可以提供文字主體主要主題的線索。 例如,我們先前所考量的「go to the moon (登月)」演講全文中最常見的單字包括 「new (新)」、「go (去)」、「space (太空)」和 「moon (月)」。 如果我們要將文字語彙基元化為二元語法 (字組),該演講中最常見的二元語法是「moon (月)」。 從這些資訊中,我們可以輕鬆地推測該文字主要涉及太空旅行和登月。
提示
簡單頻率分析,其中您只要計算每個語彙基元的出現次數,即可是分析單一文件的有效方法,但當您需要區分相同主體內的多個文件時,您則需要一種可以判斷每個文件中哪些語彙基元最為相關的方法。 詞彙頻率 - 反向文件頻率 (TF-IDF) 是一種常見技術,其根據單一文件中出現一個單字或字詞的頻率與在整個文件集合中出現的頻率進行比較,來計算分數。 使用這項技術時,會假設特定文件中經常出現的單字具有高度相關性,但在各種其他文件中則相對不常出現。
文字分類的機器學習
另一種實用的文字分析技術是使用分類演算法,例如 羅吉斯迴歸,來定型機器學習模型,其根據一組已知的分類來分類文字。 這項技術的常見應用是定型將文字分類為 正面 或 負面 的模型,以執行 情感分析 或 意見挖掘。
例如,請考量下列餐廳評論,這些評論已標示為 0 (負面) 或 1 (正面):
- 食物和服務都很棒:1
- 非常糟糕的體驗:0
- 嗯! 美味的食物和有趣的氛圍:1
- 服務緩慢和不合格的食物:0
有了足夠多的標籤評論,您就可以使用語彙基元化的文字作為 特徵 並使用情感 (0 或 1) 作為 標籤 來定型分類模型。 該模型會封裝語彙基元和情感之間的關聯性,例如,具有諸如 「好」、「美味」或「有趣」等單字的語彙基元之評論,更可能傳回 1 (正面) 的情感,而帶有「糟糕」、「緩慢」和「不合格」等單字的評論更有可能傳回 0 (負面) 的情感。
語意語言模型
隨著 NLP 先進技術的進步,定型封裝語彙基元之間語意關聯性的模型的能力,帶來了強大的語言模型的出現。 這些模型的核心是將語言語彙基元編碼為向量 (數字的多值陣列) 稱為 內嵌。
將語彙基元內嵌向量中的元素視為多維度空間中的 座標,讓每個語彙基元佔用特定的「位置」可能很有用。更接近特定維度和彼此的語彙基元,其語意更相關。 換句話說,相關字詞會更緊密地分組在一起。 例如,假設語彙基元的內嵌包含三個元素的向量,例如:
- 4 ([狗]): [10.3.2]
- 5 ([吠]): [10,2,2]
- 8 ([貓]): [10,3,1]
- 9 ([喵]): [10,2,1]
- 10 ([滑板]): [3,3,1]
我們可以根據三維空間中的這些向量繪製語彙基元的位置,如下所示:
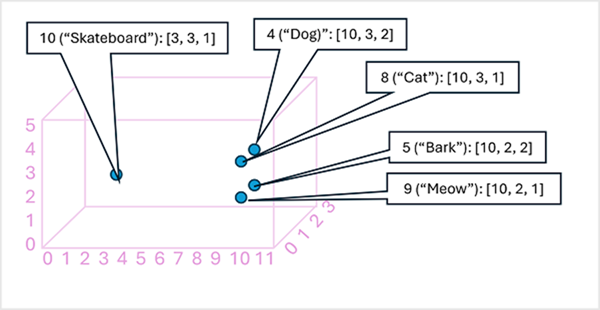
內嵌空間中語彙基元的位置包含一些有關語彙基元彼此關聯程度的資訊。 例如,「狗」的語彙基元接近「貓」,也接近「吠」。「貓」和「吠」的語彙基元接近「喵」。「滑板」的語彙基元與其他語彙基元較遠。
我們在產業中使用的語言模型是基於這些原則,但複雜性更高。 例如,所使用的向量一般具有許多更多的維度。 您也可以透過多種方法來計算指定標記集的適當內嵌。 不同的方法會產生與自然語言處理模型不同的預測。
下圖顯示大部分新式自然語言處理解決方案的一般化視圖。 原始文字的大型主體已語彙基元化,並用來定型語言模型,其可支援許多不同類型的自然語言處理工作。
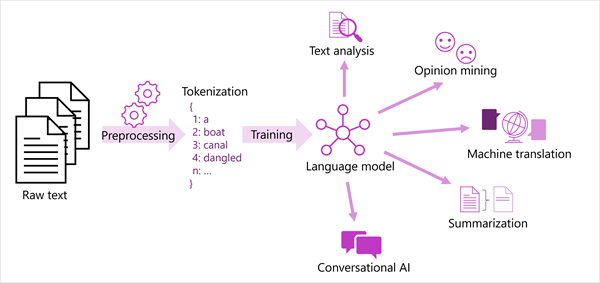
語言模型支援的一般 NLP 工作包括:
- 文字分析,例如擷取關鍵詞或識別文字中的具名實體。
- 情感分析和意見挖掘,將文字分類為 正面 或 負面。
- 機器翻譯,其中文字會自動從一種語言翻譯到另一種語言。
- 摘要,其中摘要說明大型文字主體的主要重點。
- 對話式 AI 解決方案,例如 聊天機器人 或 數位助理,其中語言模型可以解譯自然語言輸入,並傳回適當的回應。
Azure AI 語言服務中的模型支援這些功能和更多內容,接下來我們將加以探索。