資料擷取和整合
資料擷取和整合形成基礎層,以便在 Azure Databricks 內的 Lakeflow 宣告式管線中有效處理資料。 這可確保來自各種來源的資料可正確且有效地載入系統中,以便進一步分析和處理。
Lakeflow 宣告式管線可透過以下方式促進資料擷取和整合:
- 多重來源擷取:可讓您從各種來源收集資料。
- 資料流和批次資料處理:可讓您以連續方式或依照分組間隔處理資料。
- 結構描述管理:確保資料結構良好且易於管理。
- 資料品質和治理:協助您維護資料的完整性和合規性
- 管線自動化和協調流程:簡化及控制資料處理工作的順序
- 與 Azure 生態系統整合:可讓您與各種 Azure 工具和服務順暢互動
- 效能最佳化:提升您快速且有效處理資料的能力
- 監視和譜系追蹤:協助您追蹤資料的旅程,並監視其在系統內的移動。
建立管線
首先,請在 Lakeflow 宣告式管線中建立 ETL 管線。 Lakeflow 宣告式管線會使用 Lakeflow 宣告式管線語法解析筆記本或檔案 (名為原始程式碼) 中定義的相依性,藉此建立管線。 每個原始程式碼檔案只能包含一種語言,但您可以在管線中新增多個語言特定筆記本或檔案。
在您的工作區中,您可以從側邊欄中的 [作業和管線] 區段建立新的 ETL 管線。 您應將名稱指派給管線、設定包含原始程式碼的筆記本或檔案,以及設定目的地儲存位置和結構描述。
從現有的數據表載入
在您的筆記本中,您可以從 Databricks 中任何現有的資料表載入資料。 您可以使用查詢來轉換資料,或載入資料表以在管線中進一步處理。
CREATE OR REFRESH MATERIALIZED VIEW top_baby_names_2021
COMMENT "A table summarizing counts of the top baby names for New York for 2021."
AS SELECT
First_Name,
SUM(Count) AS Total_Count
FROM baby_names_prepared
WHERE Year_Of_Birth = 2021
GROUP BY First_Name
ORDER BY Total_Count DESC
從雲端物件儲存載入檔案
Databricks 建議將 自動載入器 與 Lakeflow 宣告式管線結合使用,以更好地完成來自雲端物件儲存體或 Unity Catalog 磁碟區中文件的多數資料擷取任務。 Auto Loader 和 Lakeflow 宣告式管線的預定作用是在資料抵達雲端儲存空間時,以累加和等冪的方式載入持續增長的資料。
自動載入器可以擷取 JSON、 CSV、 XMLPARQUETAVROORCTEXT和BINARYFILE檔案格式。
下列 SQL 範例會使用自動載入器從雲端儲存體讀取資料:
CREATE OR REFRESH STREAMING TABLE sales
AS SELECT *
FROM STREAM read_files(
'abfss://myContainer@myStorageAccount.dfs.core.windows.net/analysis/*/*/*.json',
format => "json"
);
下列 SQL 範例會使用自動載入器,從 Unity 目錄磁碟區中的 CSV 檔案建立資料集:
CREATE OR REFRESH STREAMING TABLE customers
AS SELECT * FROM STREAM read_files(
"/Volumes/my_catalog/retail_org/customers/",
format => "csv"
)
剖析JSON
在 Lakeflow 宣告式管線中,當您使用函數 from_json剖析 JSON 資料時,您可以讓系統自動找出 JSON 結構描述 (推論) 並隨著時間進行調整 (演進),而不是預先對結構描述進行硬式編碼。 當結構描述無法提前知道或經常變更時,這很有用。
每個from_json運算式在設定為推理和演化時,都需要一個名為schemaLocationKey的唯一識別碼。 它可讓系統追蹤哪個 JSON 結構描述屬於哪個剖析運算式。 如果您的管線中有多個 JSON 剖析運算式,則每個運算式必須使用不同的 schemaLocationKey。 此外,關鍵值在指定管線的情境中必須是唯一的。
以下是使用 SQL 語法的範例,示範將結構描述引數設定為 NULL,表示應該推斷結構描述,而不是固定:
SELECT
value,
from_json(value, NULL, map('schemaLocationKey', 'keyX')) parsedX,
from_json(value, NULL, map('schemaLocationKey', 'keyY')) parsedY,
FROM STREAM READ_FILES('/databricks-datasets/nyctaxi/sample/json/', format => 'text')
或者,您可以選擇使用from_json(jsonStr, schema, ...)的固定結構。 如果您選擇固定結構描述,則不會使用推論和演進。 此外,當您想要固定結構描述,但也想要預測或處理結構描述漂移時,結構描述提示很有用。
以下是 SQL 中的一個範例,其中查詢採用包含兩個欄位 a 和 b 的 JSON 字串,並使用第二個引數中指定的結構描述將其剖析為結構化物件。 在這裡,模式將a宣告為整數,b宣告為double,因此結果是 STRUCT<a: INT, b: DOUBLE>
SELECT from_json('{"a":1, "b":0.8}', 'a INT, b DOUBLE');
使用管線預期管理資料品質
或者,您可以使用預期來套用品質條件約束,以在資料流經 ETL 管線時加以驗證。 預期可讓您深入了解資料品質計量,並且讓您在偵測到無效記錄時取消更新或捨棄記錄。

以下範例顯示定義條件約束子句的具體化檢視。 在此案例中,條件約束包含待驗證內容的實際邏輯:Country_Region 不應空白。 記錄未通過此條件時,就會觸發預期。
CREATE OR REFRESH MATERIALIZED VIEW processed_covid_data (
CONSTRAINT valid_country_region EXPECT (Country_Region IS NOT NULL) ON VIOLATION FAIL UPDATE
)
COMMENT "Formatted and filtered data for analysis."
AS
SELECT
TO_DATE(Last_Update, 'MM/dd/yyyy') as Report_Date,
Country_Region,
Confirmed,
Deaths,
Recovered
FROM live.raw_covid_data;
條件約束的範例:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0) ON VIOLATION DROP ROW
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020) ON VIOLATION FAIL UPDATE
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
保留無效記錄是預期的預設行為。 違反預期的記錄會與有效記錄一起新增至目標資料集。 如果您指定 ON VIOLATION DROP ROW,則會從目標資料集中捨棄違反預期的記錄。 最後,如果您指定 ON VIOLATION FAIL UPDATE,則系統會以不可部分完成的方式復原交易。
套用轉換
您可以使用查詢來轉換資料,就像使用標準 SQL 命令一樣。 在下列範例中,我們定義了另一個彙總資料的具體化檢視。
CREATE OR REFRESH MATERIALIZED VIEW aggregated_covid_data
COMMENT "Aggregated daily data for the US with total counts."
AS
SELECT
Report_Date,
sum(Confirmed) as Total_Confirmed,
sum(Deaths) as Total_Deaths,
sum(Recovered) as Total_Recovered
FROM live.processed_covid_data
GROUP BY Report_Date;
執行和監視 ETL 管線
在筆記本或原始程式碼檔案中定義程式碼之後,即可啟動 ETL 管線。 您可以使用視覺化介面來監視執行:
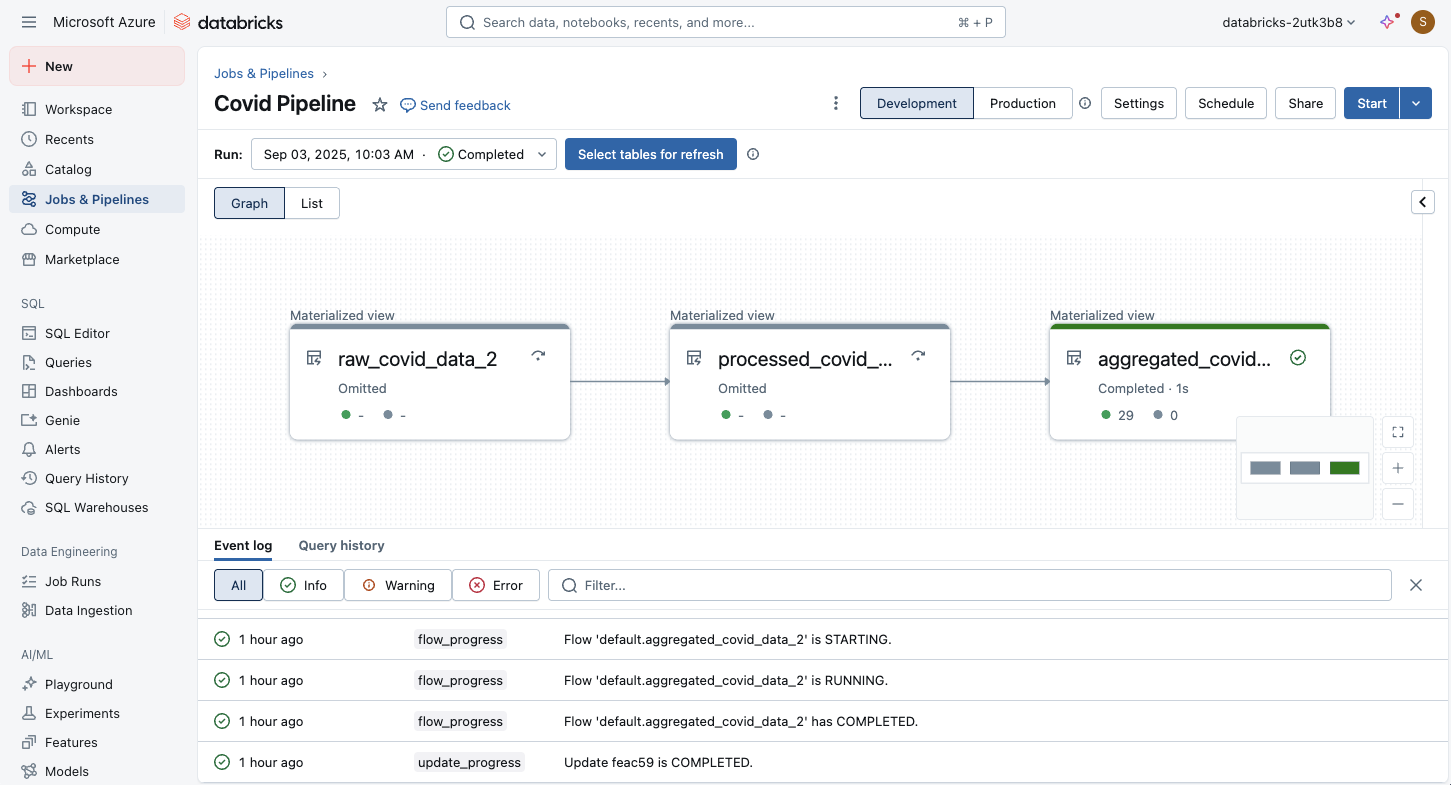
管線圖形會在管線更新成功后立即出現。 箭頭代表管線中數據集之間的相依性。 根據預設,管線詳細數據頁面會顯示數據表的最新更新,但您可以從下拉功能表中選取較舊的更新。
Lakeflow 宣告式管線支援如下的工作:
- 觀察管線更新的進度和狀態。
- 針對管線事件發出警示,例如管線更新成功或失敗。
- 檢視串流來源 (例如 Apache Kafka 和 Auto Loader) 的計量。
- 在管線更新失敗或順利完成時接收電子郵件通知。