練習 - 在 HDInsight Spark 叢集上執行查詢
在本練習中,您將了解如何從 csv 檔案建立資料框架,以及如何在 Azure HDInsight 中對 Apache Spark 叢集執行互動式 Spark SQL 查詢。 在 Spark 中,資料框架是組織成具名資料行的分散式資料集合。 資料框架在概念上等同於關聯式資料庫中的資料表或 R/Python 中的資料框架。
在本教學課程中,您會了解如何:
- 從 csv 檔案建立資料框架
- 在資料框架上執行查詢
從 csv 檔案建立資料框架
下列範例 csv 檔案包含某個建築物的溫度資訊,該資訊儲存在 Spark 叢集的檔案系統上。
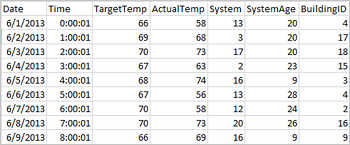
將以下程式碼貼入 Jupyter Notebook 的空白資料格,然後按 SHIFT + ENTER 以執行此程式碼。 此程式碼會匯入此案例所需的類型
from pyspark.sql import * from pyspark.sql. types import *在 Jupyter 中執行互動式查詢時,網頁瀏覽器視窗或索引標籤標題都會顯示 [(忙碌)] 狀態,以及筆記本的標題。 您也會在右上角的 PySpark 文字旁看到一個實心圓。 作業完成後,實心圓將變成空心圓。
執行下列程式碼以建立資料框架和暫存資料表 (hvac)。
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
在資料框架上執行查詢
建立資料表之後,您可以對資料執行互動式查詢。
在筆記本的空白資料格中執行下列程式碼:
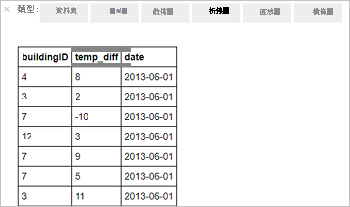
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"此時會顯示下列表格式輸出。
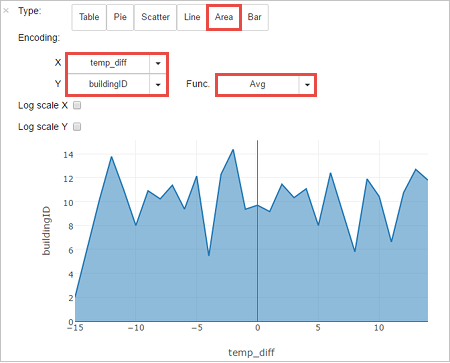
您也可以查看其他視覺效果中的結果。 若要查看相同輸出的區域圖表,請選取 [區域],然後設定其他值,如下所示。
從筆記本功能表列,瀏覽至 [檔案] > [儲存與檢查點]。
關閉筆記本以釋出叢集資源:從筆記本功能表列,瀏覽至 [檔案] > [關閉並終止]。