機器學習模型
備註
有關更多詳細信息,請參閱 文本和圖像 選項卡!
因為機器學習是以數學和統計數據為基礎,所以以數學術語思考機器學習模型很常見。 基本上,機器學習模型是一種軟體應用程式,可 封裝函式 ,以根據一或多個輸入值計算輸出值。 定義該功能的過程稱為 訓練。 定義函式之後,您可以使用函式來預測稱為 推斷的程式中的新值。
讓我們探索訓練和推斷所涉及的步驟。
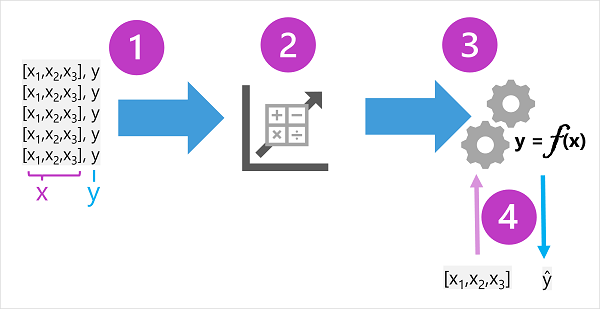
訓練數據由過去的觀察結果所組成。 在大部分情況下,觀察包括觀察到之事物的觀察屬性或 特徵 ,以及您想要定型模型來預測之事物的已知值(稱為 標籤)。
在數學方面,您通常會看到使用速記變數名稱 x 來表示的特徵,以及稱作 y 的標籤。 通常,觀察是由多個特徵值所組成,因此 x 實際上是向量(具有多個值的陣列),如下所示:[x1,x2,x3,...]。
為了更清楚說明,讓我們來考慮先前所述的範例:
- 在霜淇淋銷售案例中,我們的目標是訓練模型,以根據天氣預測霜淇淋銷售的數量。 當天的天氣測量(溫度、降雨、風力等)是 特徵 (x),每天銷售的霜淇淋數量將是 標籤 (y)。
- 在醫療案例中,目標是根據患者的臨床測量來預測患者是否面臨糖尿病風險。 病人的測量(體重、血糖水準等)是 特徵 (x),糖尿病的可能性(例如 ,1 為有風險, 0 為不危險)是 標籤 (y)。
- 在南極研究案例中,我們想要根據企鵝的實體屬性來預測企鵝的物種。 企鵝的主要測量值(其翼肢長度、喙的寬度等等)是 特徵 (x),而物種(例如, 0 代表阿黛莉, 1 代表根托,或 2 代表帽帶企鵝)是 標籤 (y)。
演算法會套用至數據,以嘗試判斷特徵與標籤之間的關聯性,並將該關聯性一般化為可在 x 上執行的計算,以計算 y。 使用的特定演算法取決於您嘗試解決的預測性問題種類(稍後會更進一步),但基本原則是嘗試將數據 放入 函式,其中特徵的值可用來計算標籤。
演算法的結果是 一種模型 ,可將演算法衍生的計算封裝 為函式 - 讓我們將其稱為 f。 在數學表示法中:
y = f(x)
現在 訓練階段已完成,已訓練的模型可用於 推理。 模型基本上是一種軟體程式,封裝了訓練過程所產生的功能。 您可以輸入一組特徵值,並接收對應標籤預測的結果。 由於模型的輸出是由函式計算的預測,而不是觀察到的值,因此您經常會看到函式的輸出顯示為 ŷ(這在口語中有趣地描述為「y-hat」)。