機器學習模型的類型
備註
有關更多詳細信息,請參閱 文本和圖像 選項卡!
機器學習有多種類型,您必須根據您嘗試預測的內容來套用適當的類型。 下圖顯示常見機器學習類型的細目。
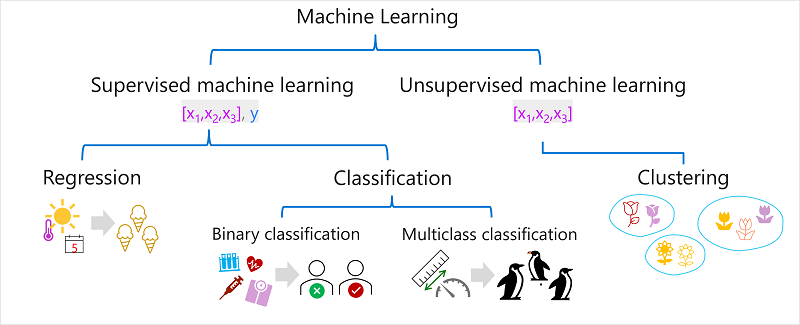
監督式機器學習
受監督 機器學習是機器學習演算法的一般詞彙,其中定型數據包括 特徵 值和已知的 標籤 。 監督式機器學習是用來透過判斷過去觀察中特徵與標籤之間的關聯性來定型模型,以便未來案例中特徵可以預測未知的標籤。
迴歸
回歸 是受監督機器學習的形式,模型所預測的標籤是數值。 例如:
- 根據溫度、降雨和風速,在指定一天銷售的霜淇淋數量。
- 以平方英呎大小、其包含的臥室數量以及其位置的社會經濟計量為基礎,出售房產的價格。
- 以汽車發動機大小、重量、寬度、高度和長度為基礎的汽車燃油效率(每加侖英里)。
分類
分類 是監督式機器學習的形式,標籤代表分類或 類別。 有兩個常見的分類案例。
二元分類
在 二元分類中,標籤會判斷觀察到的專案是否 為 特定類別的實例(或 不是)。 或者換句話說,二元分類模型會預測兩個互斥結果的其中一個。 例如:
- 根據體重、年齡、血糖水平等臨床計量,患者是否面臨糖尿病風險。
- 銀行客戶是否會根據收入、信用記錄、年齡等因素來違約貸款。
- 郵件清單客戶是否會根據人口統計屬性和過去的購買,正面回應行銷優惠。
在所有這些範例中,模型都會預測單一可能類別的二進位 true/false 或 正/負 預測。
多類別分類
多類別分類 會擴充二元分類,以預測代表多個可能類別之一的標籤。 例如,
- 根據其身體尺寸判斷企鵝的品種(阿黛莉、根托或欽斯特拉普)。
- 電影(喜劇、 恐怖、 浪漫、 冒險或 科幻小說)的流派,其演員、導演和預算。
在涉及一組已知多個類別的案例中,會使用多類別分類來預測互斥標籤。 例如,企鵝不能同時是 Gentoo 和 Adelie。 不過,也有一些演算法可用來定型 多標籤 分類模型,其中單一觀察可能有一個以上的有效標籤。 例如,電影可能會分類為 科幻小說 和 喜劇。
非監督式機器學習
非監督式 機器學習牽涉到使用只包含 特徵 值且不含任何已知標籤的數據來定型模型。 非監督式機器學習演算法會決定定型數據中觀察特徵之間的關聯性。
叢集
最常見的非監督式機器學習形式是 叢集。 群集演算法會根據其特徵識別觀察之間的相似性,並將其分組為離散叢集。 例如:
- 根據它們的大小、葉子數目和花瓣數目來分組類似的花卉。
- 根據人口統計屬性和購買行為來識別類似客戶的群組。
在某些方面,叢集類似於多元分類;在此中,它會將觀察分類為離散群組。 差別在於,使用分類時,您已經知道定型數據中觀察所屬的類別:因此,演算法的運作方式是判斷特徵與已知分類標籤之間的關聯性。 在群集中,沒有先前已知的叢集卷標,且演算法會根據特徵的相似度,將數據觀察分組。
在某些情況下,叢集可用來判斷在定型分類模型之前存在的類別集。 例如,您可以使用叢集將客戶分割成群組,然後分析這些群組來識別和分類不同的客戶類別(高價值 - 低數量、 經常小型購買者等等)。 然後,您可以使用分類來標記叢集結果中的觀察,並使用加上標籤標的資料來定型分類模型,以預測新客戶可能所屬的客戶類別。