二元分類
備註
有關更多詳細信息,請參閱 文本和圖像 選項卡!
分類,例如回歸,是 受監督的 機器學習技術;因此,遵循訓練、驗證和評估模型的相同反覆程式。 演算法不會計算像回歸模型這樣的數值,而是用來定型分類模型計算類別指派 的機率 值,以及用來評估模型效能的評估計量,比較預測類別與實際類別。
二元分類 演算法可用來定型模型,以預測單一類別的兩個可能標籤之一。 基本上,預測 true 或 false。 在大部分的實際案例中,用來定型和驗證模型的數據觀察包含多個特徵 (x) 值,以及 1 或 0 的 y 值。
範例 - 二元分類
若要瞭解二元分類的運作方式,讓我們看看使用單一特徵 (x) 來預測標籤 y 為 1 或 0 的簡化範例。 在此範例中,我們將使用患者的血糖水平來預測患者是否患有糖尿病。 以下是我們將用來定型模型的數據:

|

|
|---|---|
| 血糖 (x) | 糖尿病患者? (y) |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
定型二元分類模型
為了定型模型,我們將使用演算法來將定型數據放入函數,以計算類別標籤為 true 的機率(換句話說,患者患有糖尿病)。 Probability 會測量為介於 0.0 和 1.0 之間的值,因此所有可能類別的總機率都是 1.0。 因此,例如,如果患糖尿病的患者機率是 0.7,則患者沒有 糖尿病的對應機率為 0.3。
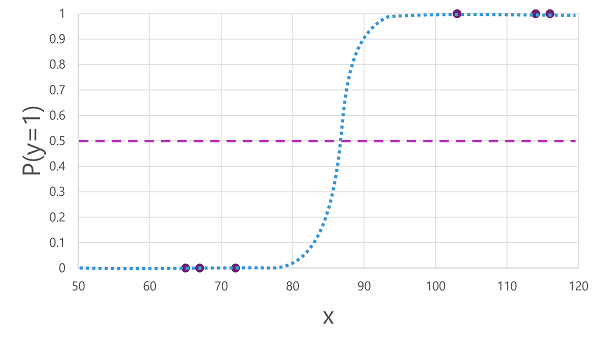
有許多演算法可用於二元分類,例如 羅吉斯回歸,其衍生了具有介於 0.0 和 1.0 之間值的 sigmoid (S 型)函式,如下所示:
備註
儘管其名稱,但在機器學習 羅吉斯回歸 中會用於分類,而不是回歸。 重點在於它所產生的函式 羅吉斯 本質,其描述下限值和上限值之間的 S 形曲線 (用於二元分類時為 0.0 和 1.0)。
演算法所產生的函式描述指定 x 值的 y 為 true (y=1) 的機率。 在數學上,您可以像這樣表示函式:
f(x) = P(y=1 | x)
對於定型數據中六個觀察中的三個,我們知道 y 絕對 正確,因此 y= 1 為 1.0 的觀察機率,而對於其他三個,我們知道 y 絕對 是 false,所以 y=1 的機率是 0.0。 S 形曲線描述機率分佈,以便繪製線條上的 x 值,以識別 y 為 1 的對應機率。
此圖表也包含一條水平線,指出模型根據此函式預測 true (1) 或 false (0) 的臨界值。 臨界值位於 y (P(y) = 0.5 的中間點。 對於在這個點或以上的任何值,模型會預測 true (1),而對於低於這個點的任何值,模型會預測 false (0)。 例如,對於血糖水準為90的患者,此函式會產生0.9的機率值。 由於 0.9 高於 0.5 的閾值,因此模型會預測 true (1) - 換句話說,預測患者患有糖尿病。
評估二元分類模型
如同回歸,在定型二元分類模型時,您會保留用來驗證定型模型之隨機數據子集。 假設我們保留下列數據來驗證糖尿病分類器:
| 血糖 (x) | 糖尿病患者? (y) |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
將我們先前衍生的羅吉斯函式套用至 x 值,會產生下列繪圖。
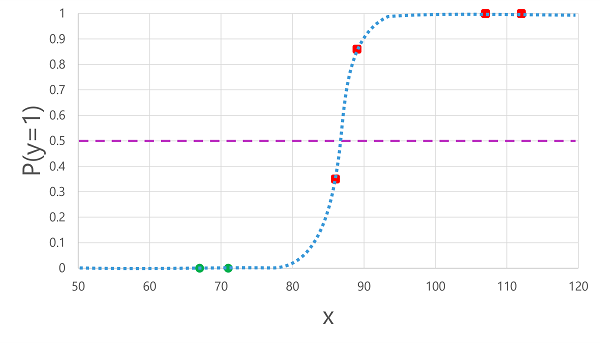
根據函式計算的機率高於或低於臨界值,模型會為每個觀察產生1或0的預測標籤。 然後,我們可以比較 預測 類別標籤 (ŷ) 與 實際的 類別標籤 (y),如下所示:
| 血糖 (x) | 實際的糖尿病診斷 (y) | 預測的糖尿病診斷 (ŷ) |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
二元分類評估指標
計算二元分類模型的評估計量的第一個步驟通常是為每個可能的類別標籤建立正確和不正確預測數目的矩陣:
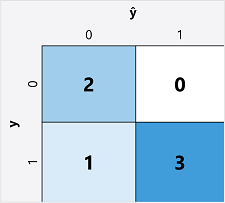
此視覺效果稱為 混淆矩陣,並顯示預測總計,其中:
- ŷ=0 和 y=0: 確判為假 (TN)
- ŷ=1 和 y=0: 偽陽性 (FP)
- ŷ=0 和 y=1: 偽陰性 (FN)
- ŷ=1 和 y=1: 確判為真 (TP)
混淆矩陣的排列方式是,正確(true)的預測會顯示在從左上到右下的對角線上。 通常,色彩強度是用來指出每個資料格中的預測數目,因此快速查看預測良好的模型應該會顯示深色對角線趨勢。
準確性
您可以從混淆矩陣計算的最簡單計量是 精確度 - 模型正確預測的比例。 精確度的計算方式如下:
(TN+TP) ÷ (TN+FN+FP+TP)
在我們的糖尿病範例中,計算為:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
因此,針對我們的驗證資料,糖尿病分類模型會產生正確的預測 83%。
精確度一開始可能看起來像評估模型的好計量,但請考慮這一點。 假設11% 的人口患有糖尿病。 您可以建立一個一律預測 0 的模型,而且其精確度為 89%,即使它並沒有實際嘗試藉由評估其特徵來區分患者。 我們真正需要的是更深入地瞭解模型如何針對正數案例預測 1 ,以及針對負數案例預測 0 。
召回率
回想 是衡量模型正確識別之正面案例比例的計量。 換句話說,與 患有 糖尿病的患者數目相比,模型 預測 有糖尿病的人數有多少?
召回的公式為:
TP ÷ (TP+FN)
針對我們的糖尿病範例:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
因此,我們的模型已正確識別出 75% 的糖尿病患者患有糖尿病。
精確度
精確度 與召回率類似,但會測量實際為真標籤之預測正面案例的比例。 換句話說,模型 預測 患有糖尿病的患者實際上 有 糖尿病的比例為何?
精度的公式為:
TP ÷ (TP+FP)
針對我們的糖尿病範例:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
因此,我們模型預測的 100% 患者實際上都患有糖尿病。
F1 分數
F1 分數 是結合召回率和精確度的整體計量。 F1 分數的公式為:
(2 x 精確度 x 召回) ÷ (精確度 + 召回)
針對我們的糖尿病範例:
(2 x 1.0 x 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
= 0.86
曲線下的區域 (AUC)
另一個召回名稱是真陽性率(TPR),而且有一個稱為誤判率(FPR)的同等計量,其計算方式為 FP÷(FP+TN)。 我們已經知道,使用閾值 0.5 為 0.75 時,模型的 TPR 為 0.75,而且可以使用 FPR 的公式來計算 0÷2 = 0 的值。
當然,如果我們要變更模型預測 true (1) 的臨界值,就會影響正面和負面預測的數目:因此,變更 TPR 和 FPR 計量。 這些計量通常用來藉由繪製 接收的運算符特性 (ROC) 曲線來評估模型,該曲線會比較 TPR 和 FPR,每個可能的臨界值介於 0.0 和 1.0 之間:
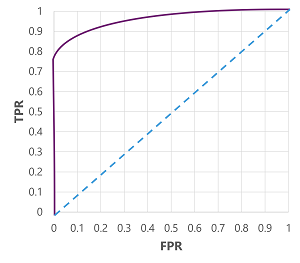
完美模型的 ROC 曲線會直升左邊的 TPR 軸,然後穿過頂端的 FPR 軸。 由於曲線的繪圖區會測量 1x1,所以這個完美曲線下的區域會是 1.0 (表示模型 100% 的時間內都正確)。 相較之下,從左下到右上的對角線代表隨機猜測二元標籤所達成的結果,所得曲線下的面積為0.5。 換句話說,給定兩個可能的類別標籤,您可以合理地預期在 50% 的時間內猜對。
在我們的糖尿病模型案例中,會產生上述曲線,而 曲線下的區域 為0.875。 由於 AUC 高於 0.5,因此我們可以得出結論,模型在預測患者的糖尿病是否比隨機猜測時表現更好。