從文件中擷取資訊
備註
有關更多詳細信息,請參閱 文本和圖像 選項卡!
現今的商業流程高度依賴表格、收據和發票等文件中的資料。 手動處理可能帶來延遲與錯誤,使得資料擷取自動化比以往更為重要。
Azure 內容理解的運作方式
Azure Content Understanding 採用模型驅動擷取工作流程,將非結構化內容匯入、分析並以結構化資料形式回傳。
匯入內容:您將內容提交至 Azure Content Understanding。
AI 驅動分析:該服務結合光學字元辨識(OCR)、語音辨識、自然語言理解及多模態 AI 模型來分析內容。
結構化輸出:服務回傳結構化結果(例如 JSON),與你的模型相符——使資料易於儲存、搜尋或整合到下游系統。
備註
JSON(JavaScript 物件符號)是一種基於文字的資料格式,用於在系統間儲存和交換結構化資料。 人類閱讀和書寫很容易,機器也很容易解析和生成。
理解結構
OCR(光學字元辨識)允許電腦從掃描文件、收據照片或印刷頁面影像中「讀取」文字,並將這些文字轉換為可編輯和搜尋的數位文字。 基本的OCR幫助辨識印刷文字,著重於文字擷取,且 不 懂字詞的意義、語境或關係。
Azure Content Understanding 的文件分析功能超越了簡單的 OCR 文字擷取,還包含 基於結構 的欄位及其值擷取。 以結構為驅動的方法正是 Azure Content Understanding 與基本 OCR 或文字轉錄服務的區別所在。
結構描述 你想提取哪些資訊 ,以及 這些資訊應該如何被結構化。 當你定義一個結構時,你指定要擷取的欄位。 結構會列出你關心的特定欄位或實體。
例如,假設您定義架構,其中包含通常位於發票中的通用欄位,例如:
- 廠商名稱
- 發票號碼
- 發票日期
- 客戶名稱
- 自訂位址
- 專案 - 已排序的專案,每個專案都包含:
- 項目描述
- 單價
- 訂購數量
- 明細項目總計
- 發票小計
- 稅額
- 運送費用
- 發票總計
現在假設您需要從下列發票中擷取此資訊:
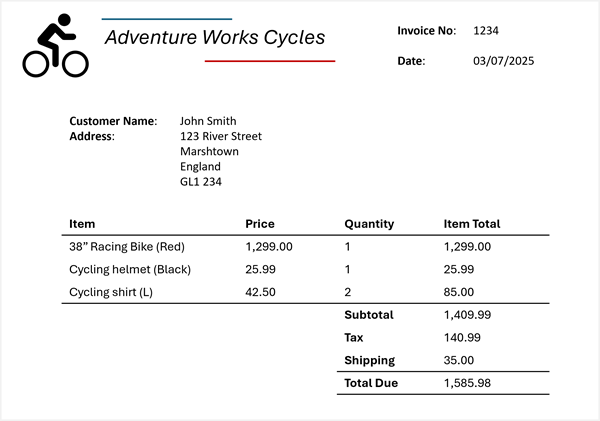
Azure Content Understanding 可以將發票架構套用到你的發票上,並識別對應欄位,即使它們標示名稱不同(或根本沒有標示)。 產生的分析會產生如下的結果:

該模式同時定義了場結構。 模式支援結構化和巢狀欄位,而不僅僅是平面文本。 例如:
-
Items是一個集合 - 每個項目有
description、unit price、quantity、line total
辨識結構化欄位讓 Azure 內容理解能理解值與值之間的關係,這是單靠 OCR 無法做到的。
在發票範例中,對於每個偵測到 的欄位,你可以提取巢狀值:
- 廠商名稱:Adventure Works Cycles
- 發票號碼:1234
- 發票日期:2025/03/07
- 客戶名稱:John Smith
- 自定義位址:123河街,馬什敦,英格蘭馬什敦,GL1 234
-
項目:
- 專案 1:
- 專案描述:38 吋賽車自行車 (紅色)
- 單價:1299.00
- 已排序的數量:1
- 明細項目總計:1299.00
- 專案 2:
- 專案描述:自行車頭盔(黑色)
- 單價:25.99
- 已排序的數量:1
- 明細項目總計:25.99
- 專案 3:
- 專案描述:自行車襯衫(L)
- 單價:42.50
- 已排序的數量:2
- 明細項目總計:85.00
- 專案 1:
- 發票小計:1409.99
- 稅:140.99
- 運送費用:35.00
- 發票總計:1585.98
Azure 內容理解擷取的是預期的意義,而不僅僅是標籤。 綱要是語意上應用的,意思是:
- 即使標籤不同,欄位仍可被擷取
- 即使缺少標籤,欄位也能被擷取
例如,若分析器判定它們代表相同的概念,則發票編號、發票#或無標注的編號皆可映射為InvoiceNumber。
了解分析工具
分析器是 Azure 內容理解中的一個單元,負責接收輸入、應用 AI 分析並產生結構化的結果。 分析器會一致對所有進來內容套用相同的擷取邏輯。 一旦設定好,分析器會確保每個分析請求都能一致重複使用該結構。 分析器也能產生可預測的 JSON 結果。 結構化的結果讓下游處理(儲存、搜尋、自動化)變得更容易。
Azure Content Understanding 提供針對常見情境的預設分析器,並支援根據您的需求量身打造的客製化分析器。 概括而言:
- 你可以選擇或建立分析器。
- 分析器包含定義欄位和結構的架構。
- 你提交內容進行分析
- 服務套用該結構
- 你會收到與結構相符的結構化 JSON 結果
在 Foundry 入口網站使用 Azure Content Understanding
備註
Foundry 入口網站擁有 經典 的使用者介面(UI)及 新的 使用者介面。
建立 Microsoft Foundry 資源後,你可以使用 經典 的 Foundry 入口介面 來測試 Azure Content Understanding。 Foundry 入口網站提供內容範例,並允許你上傳自己的資料進行分析。
你可以使用視覺介面選擇原始文件並擷取預設欄位的資訊。 例如,當你在文件圖片上試用 Azure Content Understanding,服務會回傳文件文字及文字版面資訊。

Azure Content Understanding 的分析器會辨識文件中的文字值,並將其映射到特定欄位。 例如,給定發票時,服務會回傳欄位(如供應商地址)及欄位內的資料(如 123 456th Street)。

在 Foundry 入口網站中,你也可以查看處理的 JSON 結果。

使用 Azure Content Understanding 建置客戶端應用程式
你可以使用 Content Understanding API 來建立一個輕量級的客戶端應用程式,透過程式化擷取資料。
備註
用戶端應用程式是一種軟體程式,運行於使用者的裝置上,並透過網路向其他系統(通常是伺服器)請求服務或資料。 客戶端是應用程式中使用者互動的部分,而伺服器則在幕後承擔繁重工作。 應用程式可以向服務請求資料或動作,並透過 API 接收結構化回應。
使用內容理解 API 時,你可以選擇預設的分析器或自訂分析器。 預建分析儀包括: prebuilt-invoice、 prebuilt-imageSearch、 prebuilt-audioSearch、 prebuilt-videoSearch和 。 當你將內容提交分析器分析時,分析是 非同步的,也就是說等結果準備好後才會拿到。 由於分析是非同步的,你需要持續輪詢 Operation-Location URL(或 analyzerResults),直到工作成功為止。
使用 Azure Content Understanding Python SDK
讓我們來看看使用 Python SDK 從 URL 分析發票的流程。
- 安裝 Azure Content Understanding Python SDK。
python -m pip install azure-ai-contentunderstanding
請識別您的 Foundry 資源端點與 API 金鑰,或 Microsoft Entra ID。 你的終端點通常如下:
https://<your-resource-name>.services.ai.azure.com/建立並執行客戶端應用程式碼。 這是
analzyer_id預建分析儀的識別碼。 你可以在這裡找到預先建構的分析儀 ID 值清單。
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
最終輸出為 JSON,顯示提取後的markdown、欄位、欄位內的資料及信心分數。 例如:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
接著,學習如何使用 Azure 內容理解分析器從音訊和影片中擷取結構化資料。