從傳統 MLOps 轉換至 LLMOps
MLOps (機器學習作業) 和 LLMOps (大型語言模型作業) 代表機器學習模型運作中的兩個不同的範例,每個範例都有自己的一組挑戰、工具和工作流程。
雖然傳統的 MLOps 著重於部署和管理各種不同的機器學習模型,但 LLMOps 是專為 大型語言模型 (LLM)量身打造的,其規模、數據管理和模型調整方面具有獨特的需求。
Azure Databricks 同時支援 MLOps 和 LLMOps,但實作詳細資料明顯不同。 讓我們藉由比較 MLops 與 LLMOps 來探索差異。
比較 MLOps 與 LLMOps
傳統機器學習通常涉及模型定型,像是迴歸模型或更複雜的神經網路。
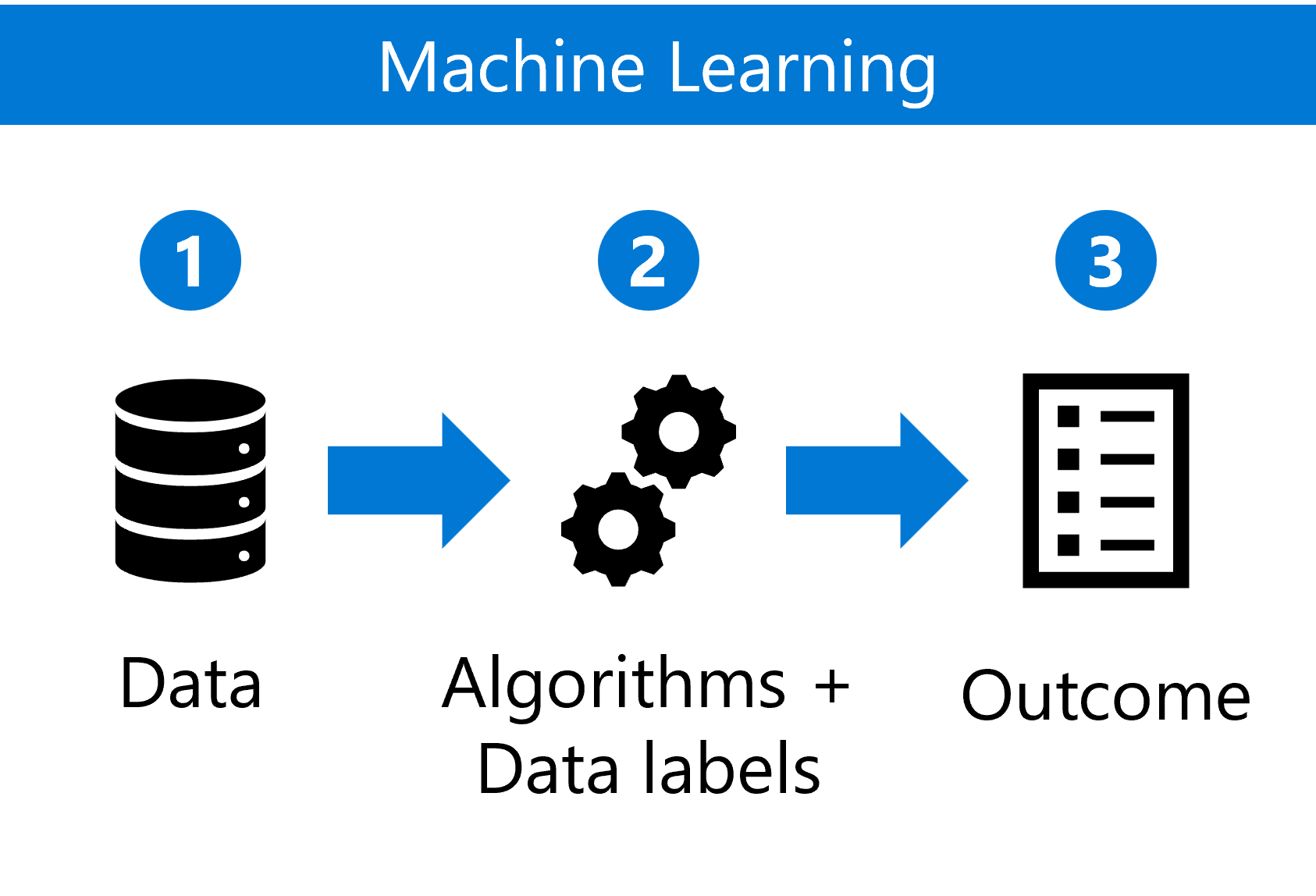
機器學習流程包括:
- 收集、探索和準備適當的 數據集。
- 選擇 演算法 並定義 數據標籤。
- 使用定型的模型來產生新數據的 預測 。
操作重點在於確保這些模型可在各種環境和資料磁碟區之間有效率地調整。
Azure Databricks 可藉由提供可調整的計算資源、與 Azure Machine Learning 整合,以及 MLflow 等工具來協助 MLOps 進行模型追蹤和部署。
另一方面,LLMOps 會處理預先定型的語言模型,這些模型可搭配文字型輸入 (也稱為提示) 等建構運作。
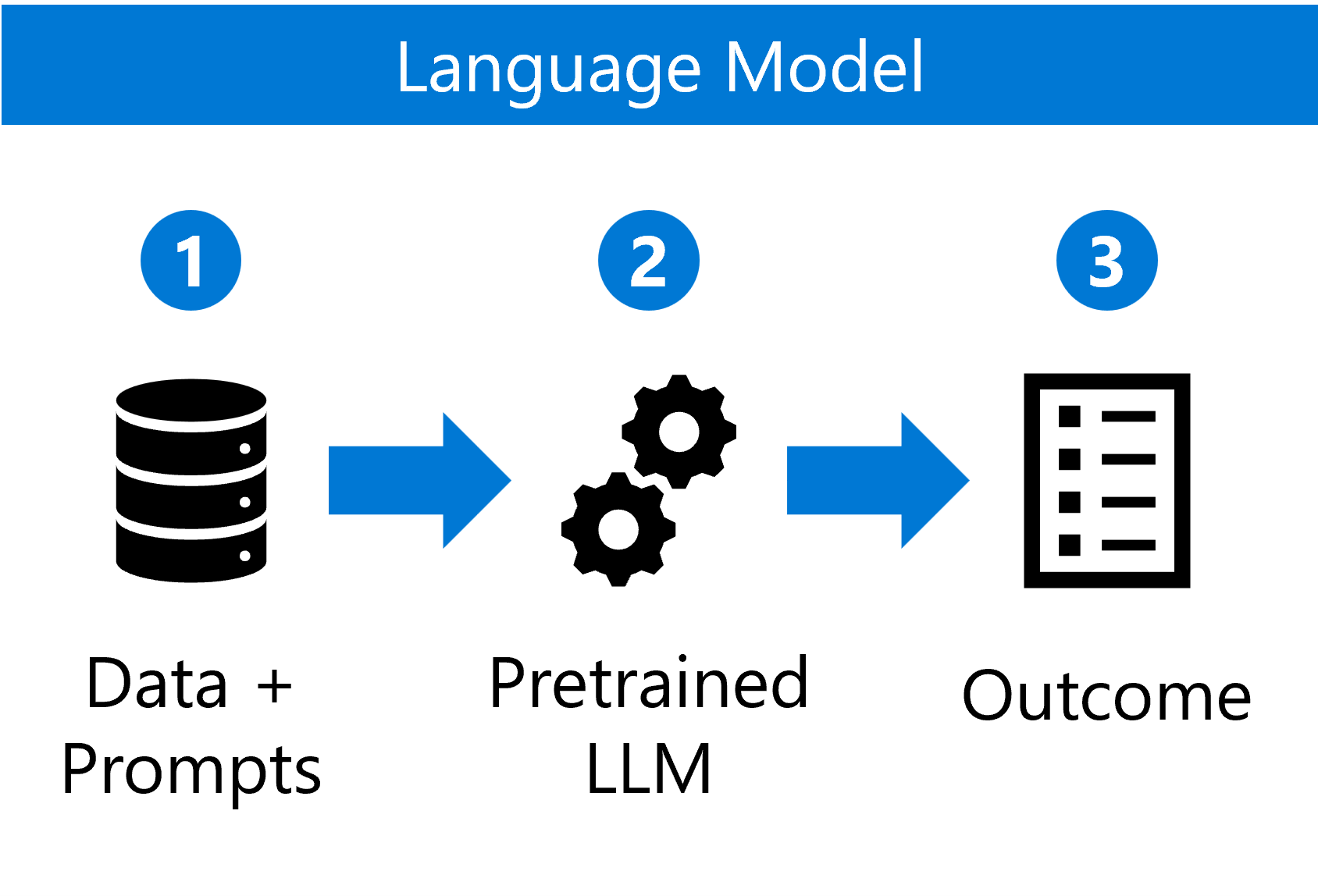
使用語言模型的程序包括:
- 結合 數據 與預期的 提示。
- 選擇及設定 預先定型的語言模型。
- 使用已設定的模型,在新的提示上產生 回應 。
LLMOps 會處理大幾個量級的模型,例如 GPT-3 或 GPT-4。 LLM 不僅需要更多的計算能力,還需要特殊化基礎結構來處理其規模。
Azure Databricks 提供 優化的叢集、 分散式運算,以及 與 Azure OpenAI 的整合,以大規模部署 LLM。
當我們比較 MLOps 與 LLMOps 時,我們需要瞭解一些主要差異。
管理非結構化文字資料
在傳統 MLOps 中,資料管理是以結構化和半結構化資料為主。 在資料管理中,焦點在於資料前處理、特徵工程和管線自動化。
不過,LLMOps 需要處理 大量的非結構化文字數據,需要更複雜的數據擷取和前置處理管線。
Azure Databricks 與 Microsoft Foundry 結合,可讓您擷取和處理大型文字語料庫,進而有效訓練和微調 LLM。
微調而不是從頭開始定型
傳統 MLOps 通常涉及反覆的模型定型和超參數微調,並著重於將特定工作的模型效能最佳化。 Azure Databricks 中 Hyperopt 和 AutoML (自動化機器學習) 之類的工具有助於將這些程序自動化。
不過,LLMOps 更強調針對特定工作或領域微調預先定型的模型 。
Azure Databricks 支援透過其與 Azure OpenAI 服務的整合進行微調,讓使用者能在最少的程式碼變更下微調 GPT-4 之類的 LLM,並使用分散式運算的強大功能來縮短訓練時間。
取用已部署的模型
在傳統 MLOps 中,部署涉及使用 REST API、批次處理或即時推斷端點將模型整合到生產系統中。
不過,在 LLMOps 中, 部署會在生命週期稍早發生 ,因為您正使用預先定型的模型,並著重於設定如何呼叫這些已部署的模型。 在 LLMOps 中,您的部署策略與傳統 MLOps 做法不同。
Azure Databricks 提供用於部署 LLM 的受控端點,以內建的監視和記錄功能來確保生產環境中的模型效能和可靠性。 或者,你也可以使用 Azure OpenAI 和 Microsoft Foundry 來部署大型語言模型,然後在 Azure Databricks 上運行並配置這些模型。
保護您的系統並實作負責任的 AI
治理、合規性和負責任的 AI 使用在傳統 MLOps 中非常重要。 特別是在金融和醫療保健等產業中,模型需要遵守嚴格的法規要求。
LLMOps 在此領域引進其他挑戰:
- 內容安全和仲裁是防止有害信息傳播的必要條件。
- 越獄 和安全措施可防範對抗性攻擊。
- 藉由制定可理解的模型決策,確保 透明度 和可解釋性可建置信任。
- 持續監視 和意見反應迴圈會隨著時間維護模型精確度、公平性和安全性。
當您解決這些挑戰時,請確定 LLM 的開發和部署是負責任的,並遵循最高標準的治理、合規性和負責任 AI 做法。