將小型查閱實體進行模型化
我們的資料模型包含兩個小型參考資料實體:ProductCategory 和 ProductTag。 這些實體用於參考值,並透過 1:Many relationship 與其他實體建立關聯。
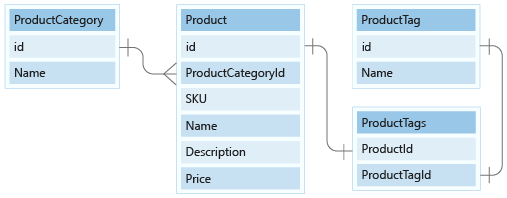
在本單元中,我們會在文件模型中將 ProductCategory 和 ProductTag 實體模型化。
將產品類別模型化
首先,針對類別,我們以 id 和 name 資料行當作唯一屬性將資料模型化,再將資料放入名為 ProductCategory 的新容器中。
接下來,我們需要選擇分區鍵。 讓我們來探討需要對此資料進行的操作。
我們會建立新的產品類別、編輯產品類別,然後列出所有產品類別。 建立和編輯產品類別的操作並不常進行。 客戶造訪網站時,我們的電子商務應用程式通常會列出所有產品類別。 因此,最後一個作業是我們最常執行的作業。
這最後一個作業的查詢如下所示:SELECT * FROM c。
由於 id 被選為分割區索引鍵,此查詢將會進行跨分割區查詢,儘管如此,我們仍希望能夠將這些以讀取為主的作業最佳化為使用單一分割區的執行方式(如有可能)。 我們也知道產品類別資料成長幅度永遠不會接近 20 GB,因此,藉助此資訊將資料模型化時,我們應設法只運用單一分割區查詢來列出所有產品類別。
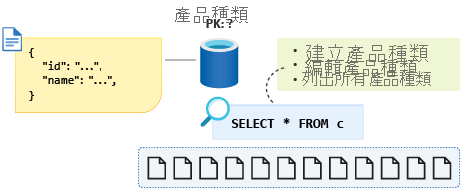
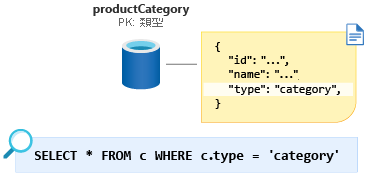
為了將此少量資料強制回到單一分割區,我們可以將實體鑑別子屬性新增至結構描述,並將此屬性用作此容器的分割區鍵。 針對容器中所有此類型的文件,我們將這個屬性設置為常數值,以確保現在是單一分割區查詢。 在此案例中,我們將屬性命名為 type,並給予常數值 category。 查詢現如下所示:SELECT * FROM c WHERE c.type = ”category”。
將產品標籤模型化
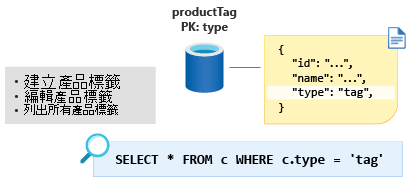
接下來是 ProductTag 對象。 此實體的功能與我們在上一節討論的 ProductCategory 實體幾乎完全相同。 在此讓我們運用相同方法,將文件模型化以納入 id 和 name 屬性,並建立名為 type 的實體鑑別子屬性,在此案例中,使用常數值 tag。 讓我們建立名為 ProductTag 的新容器,並使 type 成為新的分割區索引鍵。
有些人認為這項將小型查閱資料表模型化的技術很奇怪。 不過,以此方式將資料模型化,讓我們有機會在下一個課程模組中進一步最佳化。