HDInsight 的運作方式
HDInsight 是一個雲端分散式資料處理系統,預設提供高可用性和安全性。 此系統的核心是 Apache Hadoop。 Apache Hadoop 包含兩個核心元件:用來作為儲存體的 Apache Hadoop 分散式檔案系統 (HDFS),以及提供處理功能的 Apache Hadoop Yet Another Resource Negotiator (YARN)。 另外還有一個簡單的 MapReduce 程式設計模型,可讓您處理及分析資料。 使用 MapReduce 的優點是它很容易安裝,而且可讓您透過自動調整規模的功能控制成本。
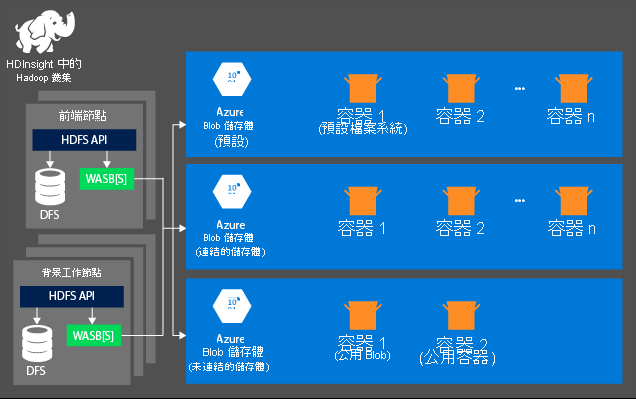
儲存體
當您佈建 HDInsight 叢集時,並不會自動建立儲存體。 而是改由 HDFS 合規系統 (例如 Azure 儲存體或 Azure Data Lake) 提供。 將儲存體與處理層分離可讓您安全地刪除用於計算的 HDInsight 叢集,而不會遺失使用者資料。 當您新增 HDInsight 叢集時,必須定義預設的檔案系統。 您可以視需要連結及取消連結檔案系統以增加儲存體大小。
以下是 HDInsight 3.6 和更新版本適用的特定資訊。 進行 HDInsight 叢集建立程序期間,您可以選取 Azure 儲存體或 Azure Data Lake Storage Gen2 作為預設檔案系統,但有幾個例外狀況。 提供預設的檔案系統可確保能夠在搜尋檔案時解析相關檔案參考。 針對 Azure 儲存體,您應該指定一個 Blob 容器作為預設檔案系統。

大部分設定都會使用 Azure Data Lake Storage Gen2。 這些設定類型會使用與 Hadoop、Microsoft Entra 整合,以及 POSIX 型存取控制清單 (ACL) 相容的檔案系統。 您可以使用 Azure Blob 儲存體提供回溯相容性,但強烈建議盡可能使用 Azure Data Lake Storage Gen2。
加工業
處理資料時,HDInsight 上 Hadoop 叢集的計算層面會分為兩個邏輯區域。 前端 (主要) 節點為背景工作節點。 前端 (主要) 節點負責接受及管理用戶端要求,然後將要求向下傳遞至背景工作節點以處理資料。 通常會有兩個主要節點。 將管理用戶端連線的使用中主要節點。 在發生應造成主要節點離線的事件時提供恢復能力的次要被動式主要節點。
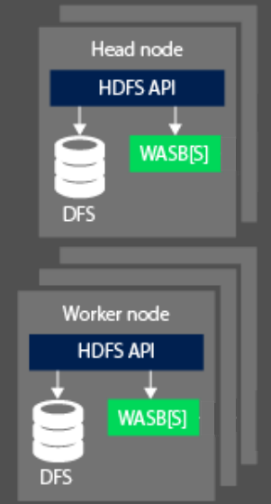
背景工作節點負責處理主要節點已經指派給它的資料。 所管理的資料取決於 MapReduce 程式設計模型如何定義資料使用方式,以及主要節點如何分配工作。 前端和背景工作節點可以直接連線至附加在本機的分散式檔案系統 (DFS),或是存取儲存在 Azure Blob 或 Azure Data Lake 中的資料。
從 OSS 角度來看,HDInsight 叢集的資源管理功能會由 YARN 執行。 此服務可管理資源和您處理資料時所進行的工作排程。 它位於 HDFS 和 HDInsight 叢集的計算系統之間。 服務會與其他 OSS 技術搭配運作,以確保有資源能夠處理 HDInsight 工作。 YARN 會與前端節點搭配運作以將工作散發到所有背景工作節點,藉此確保能夠並行執行資料處理工作。
HDFS、YARN 和 MapReduce 是 HDInsight 上的 Hadoop 所需的三個核心服務。 它通常會使用額外的 OSS 技術來簡化解決方案的建立作業。 例如,您可以使用 Hive 作為抽象層。 一個位於 MapReduce 上方,因此您可以寫入 SQL 類型語言建構,以執行隨選資料處理和分析。 或者您可以使用 Apache Ambari 在 HDInsight 叢集上執行監視作業。