語意語言模型
備註
有關更多詳細信息,請參閱 文本和圖像 選項卡!
隨著 NLP 技術的進步,能夠訓練出表達詞彙之間語義關係的模型,導致強大的深度學習語言模型的出現。 這些模型的核心是將語言標記編碼為向量(數位的多值陣列)稱為 內嵌。
這種以向量為基礎的文本建模方法,隨著 Word2Vec 和 GloVe 等技術而變得普遍,其中文字標記被表示為具有多維度的密集向量。 在模型訓練過程中,根據每個符號在訓練文本中的使用,賦予維度值以反映其語意特性。 向量之間的數學關係可被利用,比起舊有純統計技術更有效率地執行常見的文本分析任務。 這種方法的一個較新進展是使用稱為注意力的技術,在上下文中考量每個詞元,並計算周圍詞元對它的影響。 這些情境化嵌入,例如在GPT模型系列中出現的嵌入,構成了現代生成式AI的基礎。
將文字表示為向量
向量代表多維空間中的點,這些點由沿多個軸的座標定義。 每個向量描述從原點的方向和距離。 語意相似的標記應該會產生具有相似方向的向量——換句話說,它們指向相似的方向。
例如,考慮以下三維嵌入對一些常用詞彙:
| Word | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
我們可以在三維空間中視覺化這些向量,如圖所示:

"dog" 和 "cat" 的向量相似 (皆為家養動物),"puppy" 和 "kitten" 亦然 (皆為幼年動物)。 詞 "tree"彙 、 "young"、 ball" 具有明顯不同的向量方向,反映出它們不同的語意意義。
向量中編碼的語意特徵使得使用基於向量的運算能夠比較詞彙並進行分析比較。
尋找相關術語
由於向量的方向由其維度值決定,具有相似語意意義的詞彙往往具有相似的方向。 這表示你可以利用像是向量間 餘弦相似度 這類計算來進行有意義的比較。
例如,要確定 "dog"、"cat" 和 "tree" 之間的「異類」,您可以計算向量對之間的餘弦相似度。 餘弦相似度的計算方式為:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
其中 A · B 是點積,是 ||A|| 向量A的大小。
計算三個詞之間的相似性:
dog[0.8, 0.6, 0.1] 和cat[0.7, 0.5, 0.2]:- 點積:(0.8 × 0.7) + (0.6 × 0.5) + (0.1 × 0.2) = 0.56 + 0.30 + 0.02 = 0.88
-
dog的模長:√(0.8² + 0.6² + 0.1²) = √(0.64 + 0.36 + 0.01) = √1.01 ≈ 1.005 -
cat的模長:√(0.7² + 0.5² + 0.2²) = √(0.49 + 0.25 + 0.04) = √0.78 ≈ 0.883 - 餘弦相似度:0.88 / (1.005 × 0.883) ≈ 0.992 (高度相似度)
dog[0.8, 0.6, 0.1] 和tree[0.2, 0.1, 0.9]:- 點積:(0.8 × 0.2) + (0.6 × 0.1) + (0.1 × 0.9) = 0.16 + 0.06 + 0.09 = 0.31
-
tree的模長:√(0.2² + 0.1² + 0.9²) = √(0.04 + 0.01 + 0.81) = √0.86 ≈ 0.927 - 餘弦相似度:0.31 / (1.005 × 0.927) ≈ 0.333 (相似度低)
cat[0.7, 0.5, 0.2] 和tree[0.2, 0.1, 0.9]:- 點積:(0.7 × 0.2) + (0.5 × 0.1) + (0.2 × 0.9) = 0.14 + 0.05 + 0.18 = 0.37
- 餘弦相似度:0.37 / (0.883 × 0.927)≈ 0.452 (相似度低)
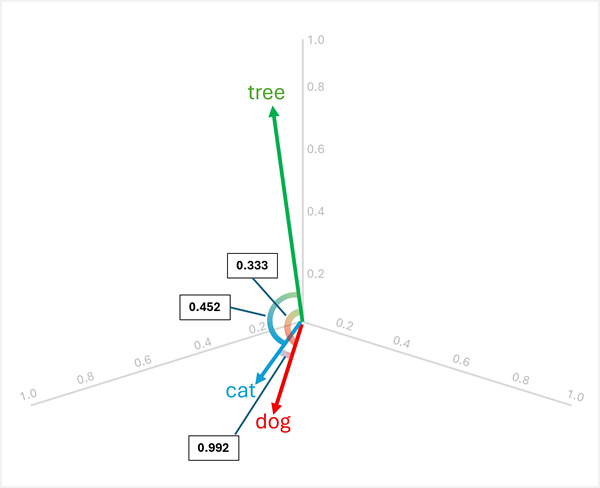
結果顯示 "dog" 與 "cat" 高度相似(0.992),而 "tree" 與兩者 "dog" (0.333)和 "cat" (0.452)的相似度較低。 因此, tree 顯然是異類。
透過加減法進行的向量轉譯
你可以增加或減去向量來產生新的向量導向結果;接著可以用來尋找具有匹配向量的標記。 此技術使直覺的算術邏輯能根據語言關係決定適當的術語。
例如,使用前面提到的向量:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
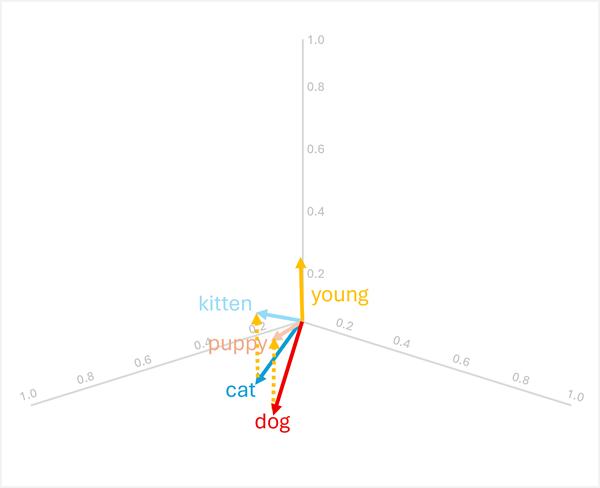
這些操作之所以有效,是因為 的 "young" 向量編碼了從成年動物到幼年動物的語意轉換。
備註
實務上,向量算術很少能產生精確匹配;相反地,你會搜尋向量 最接近 (最相似)結果的單字。
算術也可以反向計算:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
類比推理
向量算術也能回答類比問題,例如「
為了解決這個問題,請計算: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
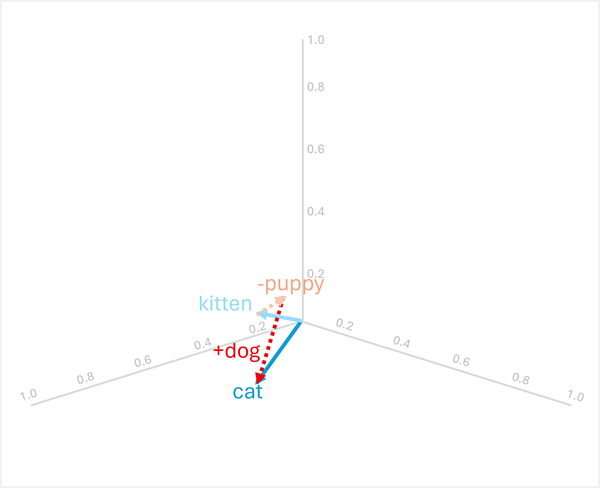
這些範例展示了向量操作如何捕捉語言關係,並促進對語意模式的推理。
使用語意模型進行文本分析
基於向量的語意模型為許多常見的文本分析任務提供了強大的功能。
文字摘要
語意嵌入透過識別向量來實現抽取式摘要,這些向量代表著最能代表整體文件的句子。 透過將每句子編碼為向量(通常透過平均或匯集其組成詞的嵌入),你可以計算出哪些句子對文件意義最為核心。 這些核心句子可以被提取成總結,捕捉關鍵主題。
關鍵字擷取
向量相似度可以透過比較每個詞的嵌入與文件整體語意表示來識別文件中最重要的詞彙。 那些向量與文件向量最相似,或在考慮文件中所有向量時最為核心的詞彙,通常是代表主要主題的關鍵詞彙。
具名實體辨識
語意模型可以透過學習向量表示,將相似的實體類型聚集成一組,來微調以識別命名實體(人、組織、地點等)。 在推論過程中,模型會檢視每個符號的嵌入及其上下文,以判斷是否代表命名實體,若代表,則為何類型。
文字分類
對於情感分析或主題分類等任務,文件可用彙總向量表示(例如文件中所有詞嵌入的平均值)。 這些文件向量可作為機器學習分類器的特徵,或直接與類別原型向量比較以分配類別。 由於語意相似的文件具有相似的向量方向,此方法有效將相關內容分組並區分不同類別。