GitHub Copilot 使用者提示處理流程
在此單元中,我們會細說 GitHub Copilot 如何將提示轉換成可用的智慧程式碼。 通常,GitHub Copilot 會在其資料流程中接收提示並傳回程式碼建議或回應。 這個過程會顯示輸入與輸出的流程。
輸入流程:
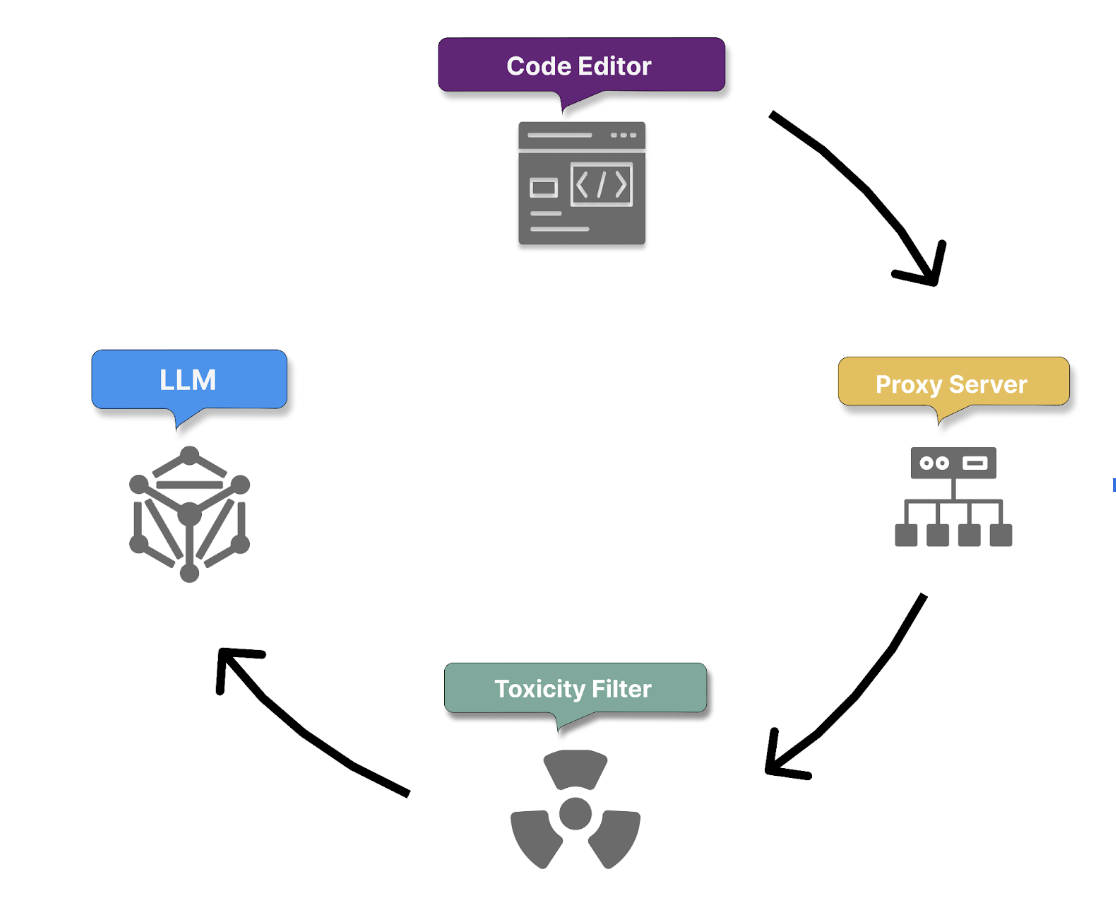
讓我們逐步解說 Copilot 為了將使用者的提示處理為程式碼建議所採取的所有步驟。
1.安全的提示傳輸和情境收集
此程序會從透過 HTTPS 安全地傳輸使用者提示來開始。 這可確保自然語言註解會安全且機密地傳送至 GitHub Copilot 的伺服器,以保護敏感性資訊。
GitHub Copilot 可安全地接收使用者提示,這個提示可能是 Copilot 聊天或您在程式碼中提供的自然語言註解。
同時,Copilot 還會收集情境詳細資料:
- 游標位置前後的程式碼,以協助其了解提示的前後情境。
- 正在編輯之檔案的檔案名稱和類型,這可讓其針對特定檔案類型量身打造程式碼建議。
- 相鄰的已開啟索引標籤的相關資訊,可確保所產生的程式碼會與相同專案中的其他程式碼區段達成一致。
- 專案結構和檔案路徑的相關資訊
- 程式設計語言和架構的相關資訊
- 使用中間填入 (Fill-in-the-Middle, FIM) 技術進行預先處理,以考慮前後的程式碼內容,有效地擴大模型的理解力,讓 Copilot 能夠利用更廣泛的內容來產生更準確且相關的程式碼建議。
這個步驟會將使用者的高階要求轉換成具體的編碼工作。
2.Proxy 篩選
一旦收集了內容並建置了提示,它就會安全地傳遞到裝載在 GitHub 擁有的 Microsoft Azure 租用戶中的 Proxy 伺服器。 該 Proxy 會篩選流量、阻止嘗試破解提示或操縱系統以揭露模型如何產生程式碼建議的相關詳細資料。
3.毒害篩選
Copilot 會先納入內容篩選機制,再繼續擷取意圖和產生程式碼,以確保所產生的程式碼和回應不會包含或推廣:
- 仇恨言論和不當內容:Copilot 會利用演算法來偵測和預防攝取仇恨言論、冒犯性語言或可能造成傷害或有所冒犯的不當內容。
- 個人資料:Copilot 會主動篩選掉任何個人資料 (例如姓名、地址或身分證字號),以保護使用者的隱私權和資料安全性。
4.使用 LLM 產生程式碼
最後,經過篩選和分析的提示會傳遞給 LLM 模型,以產生適當的程式碼建議。 這些建議會基於 Copilot 對提示和周圍內容的理解,以確保產生的程式碼相關、功能完善且符合專案特定的需求。
輸出流程:
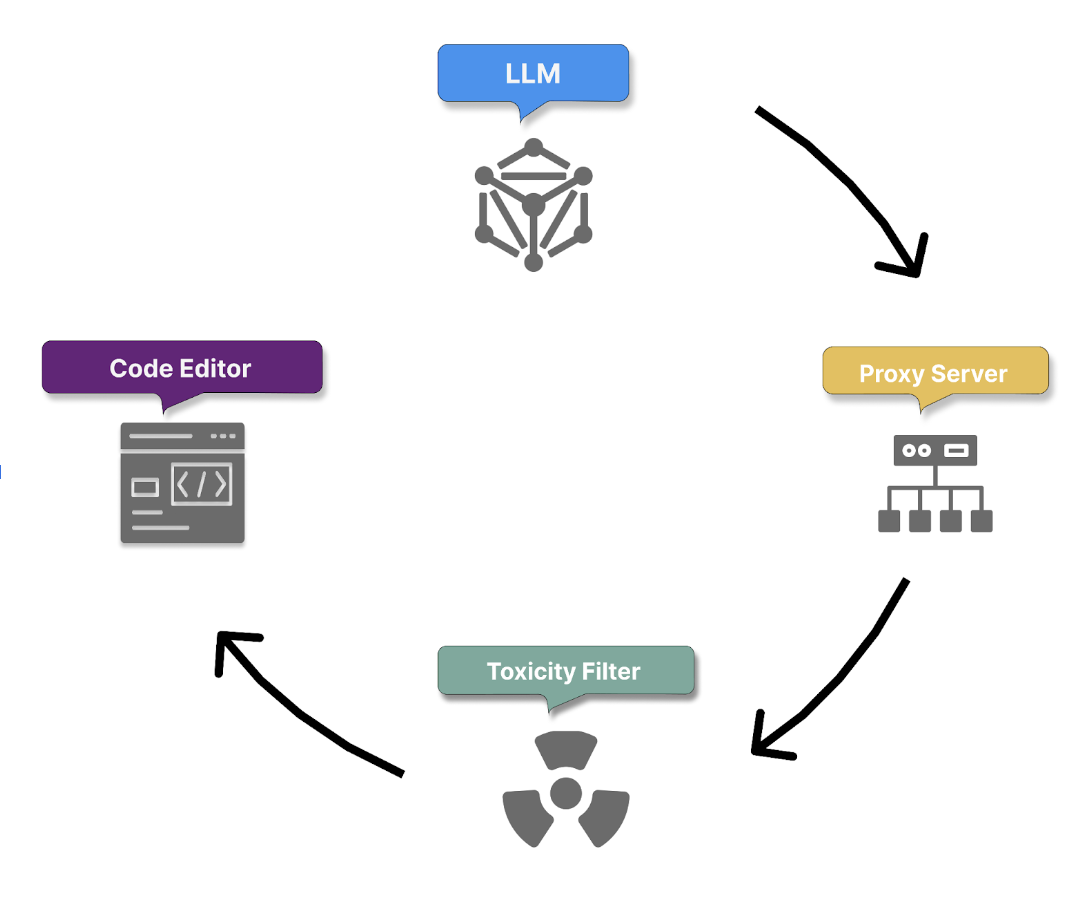
5.後處理和回應驗證
一旦模型產生其回應,毒害篩選器就會移除任何有害或冒犯性的產生內容。 然後,Proxy 伺服器會套用最後一層檢查,以確保程式碼的品質、安全性和道德標準。 這些檢查包括︰
- 程式碼品質:系統會檢查回應是否有常見的 Bug 或弱點,例如跨網站指令碼 (XSS) 或 SQL 插入,以確保產生的程式碼是健全且安全的。
- 比對公開程式碼 (選擇性):系統管理員可以選擇性地啟用一個篩選器,以防止 Copilot 傳回超過 150 個字元的建議 (如果這些建議與 GitHub 上的現有公開程式碼非常相似的話)。 這可防止巧合的相符內容被建議作為原始內容。 如果回應的任何部分未通過這些檢查,則它會被截斷或捨棄。
6.建議傳遞與意見反應迴圈起始
只有通過所有篩選器的回應才會傳遞給使用者。 然後,Copilot 會根據您的動作來起始意見反應迴圈,以達成以下目的:
- 從已接受的建議中增長知識。
- 透過建議的修改和拒絕來學習和改進。
7.重複後續提示
此程序會在您提供更多提示時重複進行,Copilot 會持續處理使用者要求、了解其意圖並產生程式碼以作為回應。 一段時間後,Copilot 會運用累積的意見反應和互動資料 (包括情境詳細資料) 以改善其對於使用者意圖的了解,並精進其程式碼產生功能。