GitHub Copilot 大型語言模型 (LLM)
GitHub Copilot 是由大型語言模型 (LLM) 提供,可協助您順暢地撰寫程式碼。 在此單元中,我們著重於了解 GitHub Copilot 中 LLM 的整合和影響。 讓我們複習下列主題:
- 什麼是 LLM?
- 在 GitHub Copilot 和提示中 LLM 的角色
- 微調 LLM
- LoRA 微調
什麼是 LLM?
大型語言模型 (LLM) 是為理解、生成和操縱人類語言而設計和定型的人工智慧模型。 由於接受了大量文字資料的訓練,這些模型具有處理涉及文字的廣泛任務的能力。 以下是了解 LLM 的一些核心層面:
定型資料量
LLM 會接觸到來自各種來源的大量文字。 這種接觸讓他們對各種形式的交流中涉及的語言、背景和複雜性有了廣泛的理解。
內容理解
他們擅長產生與內容相關且連貫的文字。 他們理解內容的能力讓它能夠提供有意義的貢獻,無論是完成句子、段落,還是產生適合內容的整個文件。
機器學習和 AI 整合
LLM 以機器學習和人工智慧原則為基礎。 它們是具有數百萬甚至數十億參數的神經網路,這些參數在定型過程中進行微調,以有效地理解和預測文字。
多功能性
這些模型不限於特定類型的文字或語言。 它們可以量身打造並微調以執行特別工作,讓其在各種領域和語言中具有高度多功能性以及適用性。
在 GitHub Copilot 和提示中 LLM 的角色
GitHub Copilot 利用 LLM 提供內容感知程式碼建議。 LLM 不僅會考慮目前的檔案,也會考慮 IDE 中其他開啟的檔案和索引標籤,以產生精確且相關的程式碼完成。 此動態方法可確保提供量身打造的建議,以提升您的生產力。
微調 LLM
微調是一個重要程序,可讓我們針對特定工作或領域量身打造預先定型的大型語言模型 (LLM)。 它涉及在較小的、特定工作的資料集 (稱為目標資料集) 上定型模型,同時使用從大型預定型資料集 (稱為來源模型)中獲得的知識和參數。
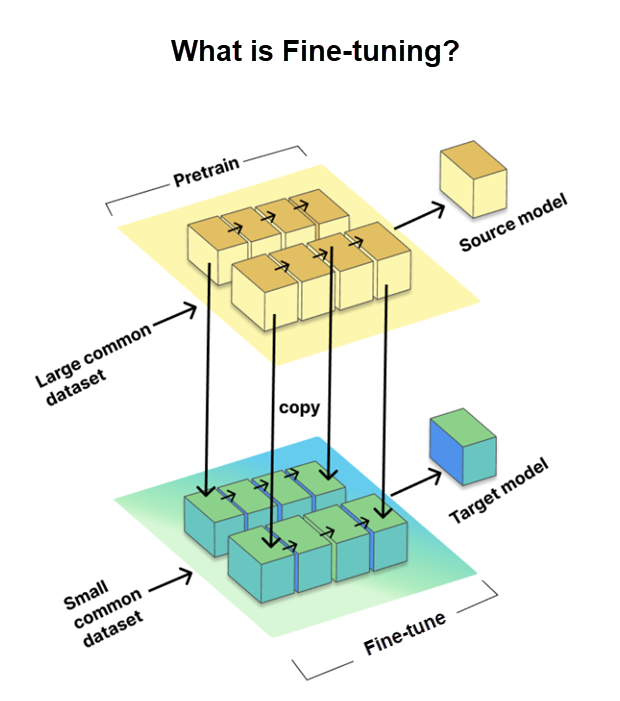
微調對於讓 LLM 適應特定工作、提高其效能來說至關重要。 然而,GitHub 更進一步,使用了 LoRA 微調方法,我們會在接下來討論。
LoRA 微調
傳統的完整微調表示定型類神經網路的所有部分,速度可能很慢且嚴重依賴資源。 但 LoRA (低等級適應) 微調是一個聰明的替代方案。 它用來讓大型預先定型語言模型 (LLM) 更適合用於特定工作,而不需要重做所有定型。
以下是 LoRA 的運作方式:
- LoRA 會將較小的可定型部分新增至預先定型模型的每一層,而不需要進行所有變更。
- 原始模型維持不變,可節省時間和資源。
LoRA 有什麼好處:
- 它會勝過其他適應方法,例如適應工具和前置詞微調。
- 就像用更少的移動部分獲得更好的結果一樣。
簡單來說,LoRA 微調是為了更聰明地工作,而不是更努力地工作,讓 LLM 更可以滿足您在使用 Copilot 時的特定編碼要求。