獨熱向量
到目前為止,我們已討論過連續資料編碼 (浮點數)、次序資料編碼 (通常是整數),以及二進位分類資料編碼 (存活/死亡、男性/女性等)。
現在,我們要了解如何將資料編碼,並探索具有兩個以上類別的分類資料資源。 我們也將探索模型改善決策對模型效能的潛在有害影響。
分類資料不是數值
分類資料使用數字的方式與其他資料類型使用數字的方式不同。 使用次序或連續 (數值) 資料時,較高的值表示數量增加。 例如,在鐵達尼號上,£30 的票價比 £12 票價需要的金錢更多。
相反地,分類資料沒有邏輯順序。 如果我們嘗試將具有兩個以上類別的分類特徵編碼為數字,就會發生問題。
例如,乘船港有三個值:C (瑟堡)、Q (皇后鎮) 和 S (南安普敦)。 我們無法將這些符號取代為數字。 如果我們這麼做,就表示這其中一個港口「小於」其他港口,而另一個港口則「大於」其他港口。 這種取代並無任何意義。
作為此問題的範例,讓我們拋開警告,建立乘船港和票價類別之間的關聯性,並將乘船港視為數字。 首先,我們將港口的順位排名如下 C < S < Q:
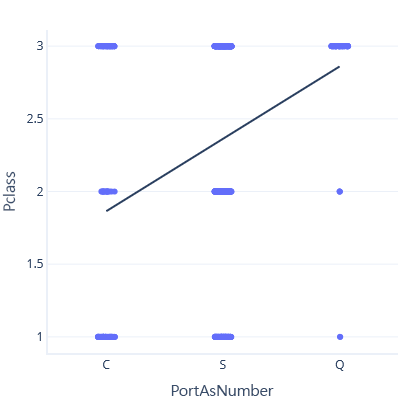
在此圖中,這條線會預測 Q 港的 Class 為 ~3。
現在,如果我們設定 S < C < Q,則會得到不同的趨勢線和預測:
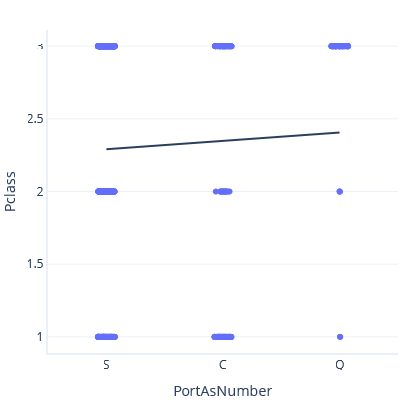
這兩條趨勢線都不正確。 將分類視為連續特徵並無任何意義。 那麼,要如何處理分類呢?
One-Hot 編碼
獨熱編碼可以透過避免此問題的方式來將分類資料編碼。 每個可用的分類都會取得自己的單一資料行,而指定的資料列只會包含其所屬分類中單一的 1 值。
例如,我們可以在三個資料行中將港口值編碼,一個用於瑟堡,一個用於皇后鎮,另一個則用於南安普敦 (此處的確切順序並無任何相關性)。 在瑟堡上船的人會在 Port_Cherbourg 資料行中有一個 1,如下所示:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 1 | 0 | 0 |
在皇后鎮上船的人會在第二個資料行中有一個 1:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 1 | 0 |
在南安普敦上船的人會在第三個資料行中有一個 1
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 0 | 1 |
獨熱編碼、資料清除和統計檢定力
使用獨熱編碼之前,請務必了解其使用方式對模型的實際效能是否有正面或負面的影響。
什麼是統計檢定力?
統計檢定力指的是模型能夠可靠地識別特徵和標籤之間實際關聯性的能力。 例如,功能強大的模型可能會報告票價和存活率之間的關聯性,而且具有高度確定性。 相較之下,統計檢定力較低的模型可能會報告確定性較低的關聯性,甚至可能完全找不到此關聯性。
我們將避免在這裡使用數學,但請記住,我們所做的選擇可能會影響模型的檢定力。
移除資料會降低統計檢定力
我們已多次提及資料清除 (在某種程度上) 需要移除不完整的資料樣本。 不幸的是,資料清除會降低統計檢定力。 例如,假設我們想要根據下列資料來預測鐵達尼號航行的存活率:
| 票價 | 存活 |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £10 | 1 |
| £25 | 1 |
我們可以猜到其票價為 15 英鎊的人會倖存,因為其票價至少 10 英鎊的人都活了下來。 但是,如果我們的資料較少,此猜測就會變得更加困難:
| 票價 | 存活 |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £25 | 1 |
毫無價值的資料行會降低統計檢定力
不具價值的特徵也會損害統計檢定力,特別是當特徵 (或資料行) 的數目開始接近樣本 (或資料列) 的數目時。
例如,假設我們想要能夠根據下列資料來預測存活率:
| 票價 | 存活 |
|---|---|
| £4 | 0 |
| £4 | 0 |
| £25 | 1 |
| £25 | 1 |
我們可以有自信地預測持有船艙 A 船票的人都會存活,因為所有持有 £25 船票的人都會存活。
但是,我們現在有另一個特徵 (船艙):
| 票價 | 船艙 | 存活 |
|---|---|---|
| £4 | A | 0 |
| £4 | A | 0 |
| £25 | B | 1 |
| £25 | B | 1 |
船艙不會提供有用的資訊,因為其只是與票證的對應。 目前還不清楚持有 25 英鎊 A 艙票的人是否能活下來。 他們會像 A 艙的其他人一樣死了, 還是會像其票價為 25 英鎊的人一樣存活?
獨熱編碼可能會降低統計檢定力
比起連續或次序資料,獨熱編碼的統計檢定力降低更多,因為其需要多個資料行,每個可能的分類值都要一個資料行。 例如,如果我們對登船港口進行單一熱編碼,我們會新增三個模型輸入 (C、S 和 Q)。
如果分類數目遠小於樣本 (資料集資料列) 的數目,分類變數就會變得很有用。 如果其提供尚未透過其他輸入提供給模型的資訊,則分類變數也會變得很有用。
例如,我們發現在不同港口上船的人,存活的可能性各有不同。 這種變化可能反映了大多數在皇后鎮港的人都持有第三類船票。 因此,在未於模型中新增相關資訊的情況下,乘船可能會稍微降低統計檢定力。
相比之下,艙等對存活率的影響可能很大。 因為比起較靠近船舶上層甲板的船艙,船舶的下層船艙會更早被水淹沒。 也就是說,鐵達尼號的資料集包含了 147 個不同的船艙。 如果我們包含它們,這會降低模型的統計檢定力。 我們可能需要試驗在模型中包含或排除船艙資料,以查看船艙資料是否可協助我們。
在下一個練習中,我們最終建置了模型來預測鐵達尼號航行的存活率,並在執行此操作時練習獨熱編碼。