決策樹和模型架構
說到架構時,我們想到的往往是大樓。 架構負責大樓的建築方式,也就是其高度、其深度、樓層數,以及內部各個組成的連接方式。 實際上,此架構也會規定我們使用大樓的方式:像是我們從哪裡進大樓,以及「從哪裡出去」。
在機器學習中,架構所指的概念也差不多。 它有多少參數,這些參數如何連結起來以便能進行計算? 是否會以平行方式大量計算 (寬度),或是否有依賴先前計算的序列作業 (深度)? 如何對此模型提供輸入,以及如何接收輸出? 這類架構決策一般只適用於更複雜的模型,而且架構式決策的範圍從簡單到複雜都有。 這些決策通常會在訓練模型之前就進行,但在某些情況下,仍可在訓練後再來變更。
讓我們以決策樹為例來對此進行更具體的探討。
什麼是決策樹?
基本上,決策樹就是一個流程圖。 決策樹是將決策細分為多個步驟的分類模型。
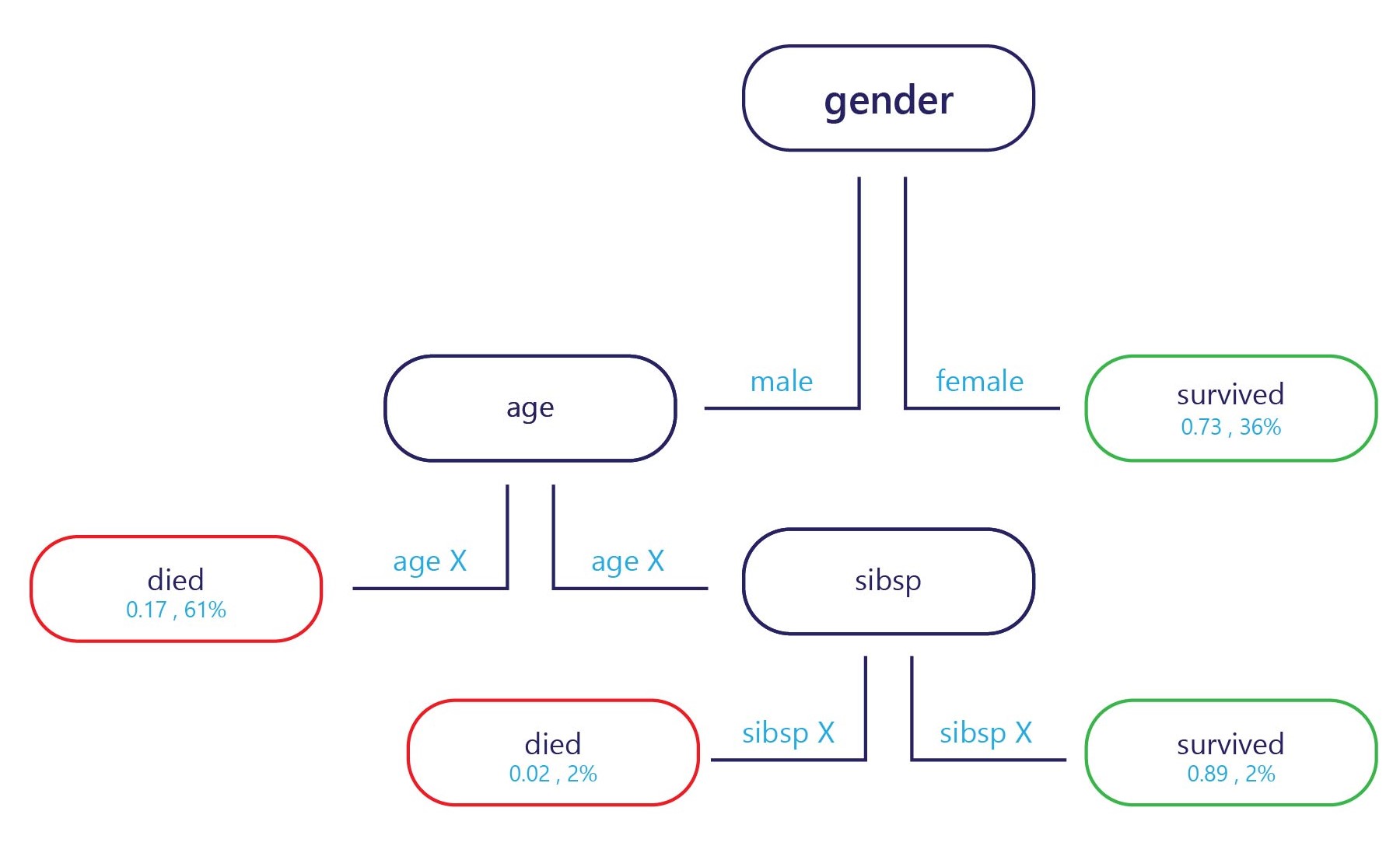
我們會在進入點 (圖中頂端) 提供樣本,而且每個結束點會有標籤 (圖中底部)。 在每個節點上,簡單的 "if" 陳述式會決定樣本要將哪個分支傳遞給下一個。 一旦分支到達決策樹尾端 (分葉),它就會指派給標籤。
如何訓練決策樹?
我們一次會對決策樹訓練一個節點 (或稱決策點)。 在第一個節點上,我們會評估整個訓練集。 我們會從該節點選取能夠將整個訓練集完美分成兩個子集且具有更多同質標籤的特徵。 例如,假設我們的訓練集如下所示:
| 體重 (特徵) | 年齡 (特徵) | 贏得獎牌 (標籤) |
|---|---|---|
| 90 | 18 | No |
| 80 | 20 | No |
| 70 | 19 | No |
| 70 | 25 | No |
| 60 | 18 | Yes |
| 80 | 28 | Yes |
| 85 | 26 | Yes |
| 90 | 25 | Yes |
如果我們想要盡力找出一個可以分割此資料的規則,我們可能會用約 24 歲的年齡來分割,因為大部分贏得獎牌的選手都超過 24 歲。 此分割會讓我們獲得兩個資料子集。
子集 1
| 體重 (特徵) | 年齡 (特徵) | 贏得獎牌 (標籤) |
|---|---|---|
| 90 | 18 | No |
| 80 | 20 | No |
| 70 | 19 | No |
| 60 | 18 | Yes |
子集 2
| 體重 (特徵) | 年齡 (特徵) | 贏得獎牌 (標籤) |
|---|---|---|
| 70 | 25 | No |
| 80 | 28 | Yes |
| 85 | 26 | Yes |
| 90 | 25 | Yes |
如果我們就此停下,則會獲得一個簡單的模型,內含一個節點和兩個分葉。 分葉 1 包含未贏得獎牌的選手,在訓練集上有 75% 的正確性。 分葉 2 包含贏得獎牌的選手,在訓練集上同樣有 75% 的正確性。
不過,我們不必就此停下。 我們可以進一步分割這兩個分葉來繼續此程序。
在子集 1 中,第一個新節點可以用體重來分割,因為唯一贏得獎牌的選手體重小於未贏得獎牌的選手。 規則可以設為「體重 < 65」。 體重 < 65 的人預測會獲得獎牌,而體重 ≥65 的任何人則不符合此準則,而且可能會預測為不贏得獎牌。
在子集 2 中,第二個新節點也可以用體重來分割,但這次會預測體重超過 70 的選手會贏得獎牌,而低於此體重的選手則不會贏得獎牌。
這會讓我們獲得會在訓練集上達到 100% 正確性的決策樹。
決策樹的優點和缺點
一般認為,決策樹的偏差不高。 這表示決策樹通常很適合用來識別重要的特徵,以便正確地標示某個東西。
決策樹的一大缺點是過度學習。 請想一下前面提供的範例:模型會正確地計算誰可能贏得獎牌,而這會正確地預測 100% 的訓練資料集。 對於機器學習模型來說,這種程度的正確性極不尋常,一般都會對訓練資料集造成諸多錯誤。 訓練表現很好這件事,本身並不是壞事,但決策樹由於變得太過專精於處理訓練集,因為不太可能會在測試集上有優異的表現。 這是因為決策樹的目的是要了解訓練集中可能不符合現實的關聯性 (例如,如果您不到 25 歲,則體重 60 公斤保證能贏得獎牌)。
模型架構會影響過度學習
我們為決策樹打造的結構是其能否迴避缺點的關鍵。 決策樹的深度愈深,就越可能會過度學習訓練集。 例如,在上述的簡單決策樹中,如果我們將決策樹限制為只有第一個節點,則決策樹會在訓練集上犯錯,但可能會在測試集上表現得更好。 這是因為決策樹會有關於誰能贏得獎牌的普遍性規則 (例如「超過 24 歲的運動員」),而不是極為特定而可能只適用於訓練集的規則。
雖然我們在這邊只專注說明決策樹,但其他複雜模型往往也有類似的缺點,我們可以透過決定如何構建它們或如何允許它們被訓練所操控來減輕這些缺點。