混淆矩陣
您可以將資料用連續、分類或序數 (分類但有順序) 的角度來看待。 混淆矩陣可用來評估分類模型的表現好壞。 關於這些矩陣的表現,讓我們先回想一下有關連續資料的知識。 回想之後我們就會發現,混淆矩陣為何就只是我們已知的長條圖的延伸。
連續資料分佈
如果我們想要了解連續資料,第一步往往是看其分佈方式。 請考慮下列長條圖:
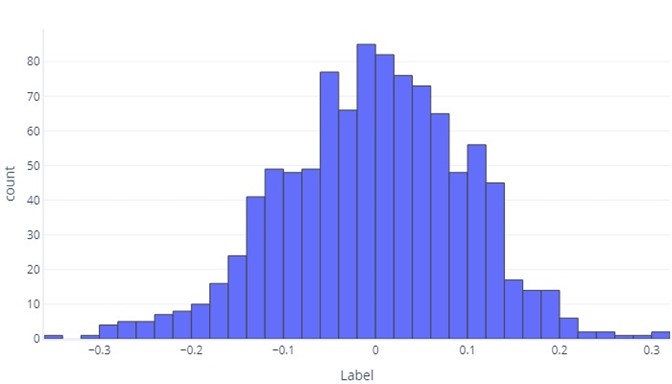
我們可以看到,標籤平均在 0 值上下,而且大部分的資料點落在 -1 到 1 之間。 其分佈頗為對稱,平均值以下和以上的數量大約相等。 如有需要,我們也可以使用資料表而不是長條圖,但資料表不好處理。
分類資料分佈
分類資料在某些方面與連續資料大為不同。 我們還是可以產生長條圖來評估每個標籤的值有多常出現。 例如,二元標籤 (true/false) 可能會有如下所示頻率的出現情形:
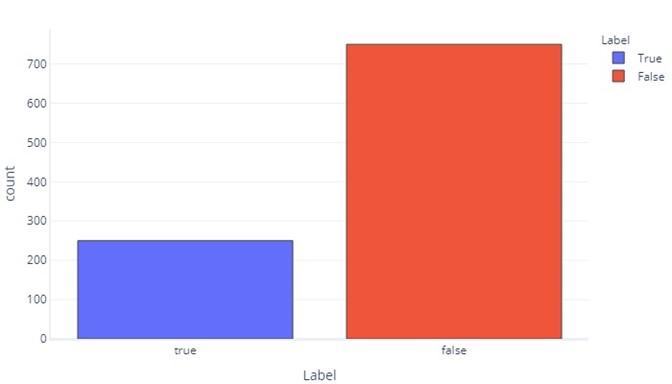
這個圖告訴我們,有 750 個樣本以「false」作為標籤,有 250 個範例以「true」作為標籤。
三個分類的標籤情況類似:
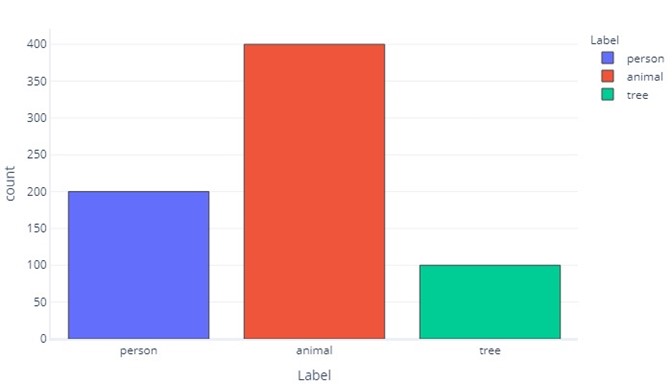
這告訴我們,有 200 個樣本是「人類」、400 個是「動物」,100 個是「樹木」。
由於分類標籤比較簡單,我們往往可以將其顯示為簡單的表格。 前兩個圖表會顯示如:
| 標籤 | False | True |
|---|---|---|
| 計數 | 750 | 250 |
以及:
| 標籤 | 個人 | 動物 | 樹狀結構 |
|---|---|---|---|
| 計數 | 200 | 400 | 100 |
查看預測
和查看資料中的基準真相標籤一樣,我們也可以查看模型所做的預測。 例如,我們可能會在測試集內看到,我們的模型預測「false」700 次和「true」300 次。
| 模型預測 | 計數 |
|---|---|
| False | 700 |
| True | 300 |
這提供直接的資訊,關於我們的模型所做的預測,但無法告訴我們何者正確。 雖然我們可以使用成本函式來了解提供正確回應的頻率,但成本函式不會告訴我們正在發生哪些錯誤。 例如,模型可能會正確地猜測到所有「true」值,但也會在應該猜測「false」時卻猜測「true」。
混淆矩陣
想要了解模型的表現,關鍵在於結合用於模型預測的資料表,以及用於基準真相資料標籤的資料表:
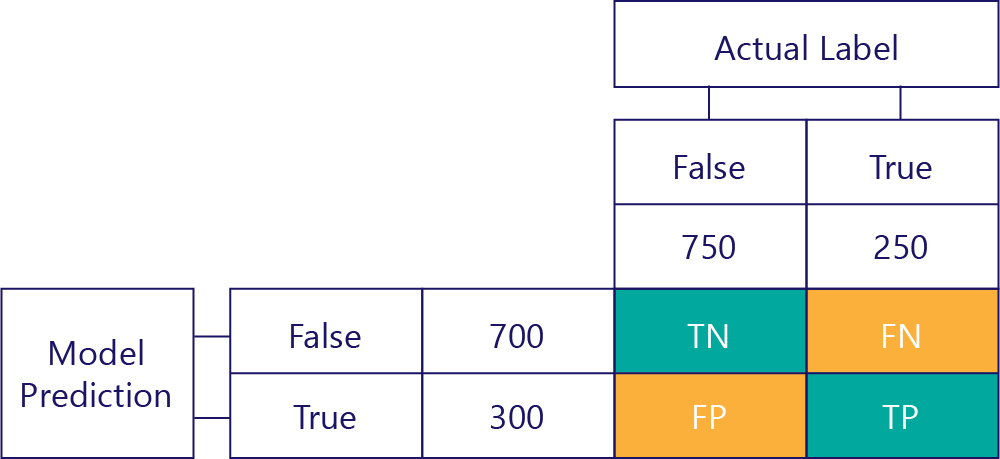
我們尚未填寫的方塊稱為混淆矩陣。
混淆矩陣中的每個資料格都會告訴我們一件有關模型表現的事。 這些資料格是「確判為否 (TN)」、「誤判為否 (FN)」、「誤判為真 (FP)」和「確判為真 (TP)」。
讓我們逐一解說這幾個項目,並用實際值取代這些縮寫。 藍綠色方塊表示模型做了正確的預測,橘色方塊表示模型做了不正確的預測。
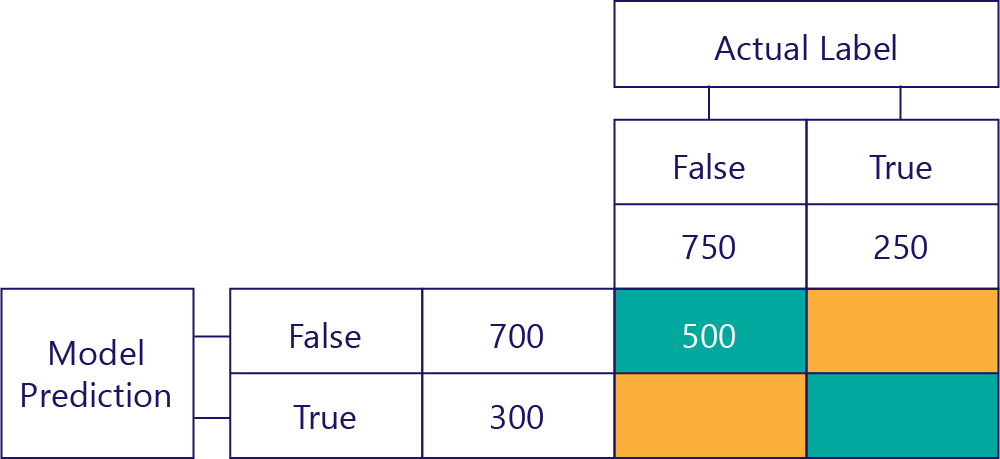
確判為否 (TN)
左上角的值會列出模型的預測是 false,而實際的標籤也是 false 的次數。 換句話說,此方塊會列出模型正確預測 false 的次數。 假設在我們的範例中,這種情況發生了 500 次:
誤判為否 (FN)
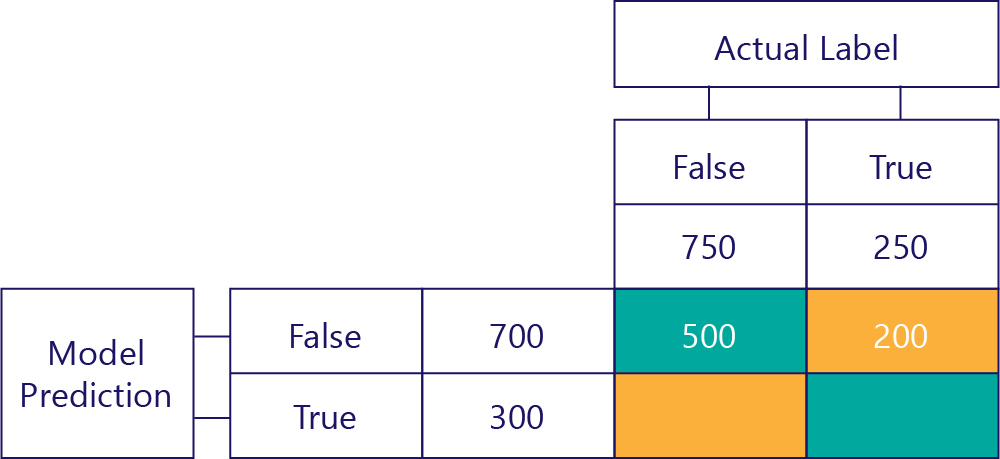
右上角的值會告訴我們模型預測 false,但實際的標籤是 true 的次數。 現在我們知道這種情形有 200 次。 怎麼做? 因為模型總共預測了 false 700 次,而這 700 次中有 500 次預測正確。 因此,一定有 200 次在不應該預測 false 時卻如此預測。
誤判為真 (FP)
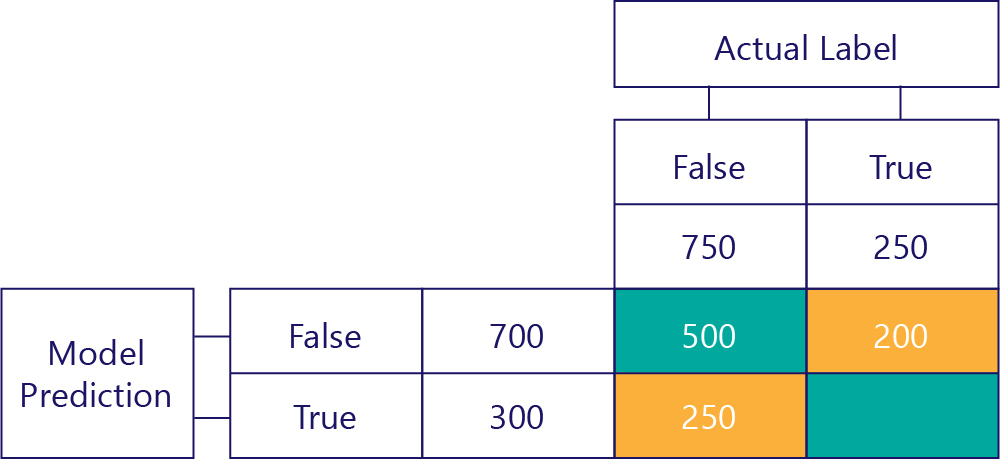
右下角的值包含誤判為真。 這個值會告訴我們模型預測 true,但實際標籤卻是 false 的次數。 現在我們知道這種情形有 250 次,因為有 750 次正確的答案是 false。 這 750 次有 500 次出現在左上角的資料格 (TN):
確判為真 (TP)
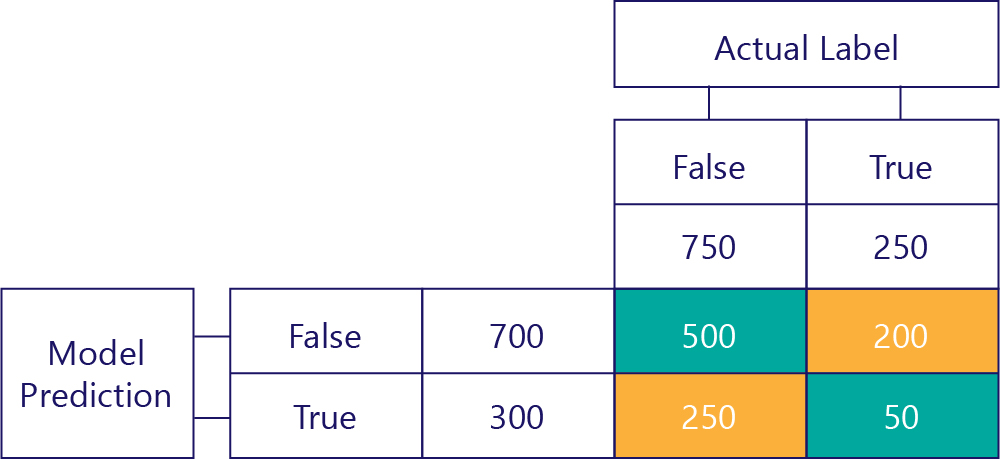
最後是確判為真。 這是模型正確預測 true 的次數。 我們知道次數是 50 次,原因有兩個。 首先,模型預測 true 300 次,但 250 次預測不正確 (左下角資料格)。 其次,有 250 次 true 是正確答案,但模型有 200 次預測為 false。
最終矩陣
我們一般會將混淆矩陣稍微簡化,如下所示:
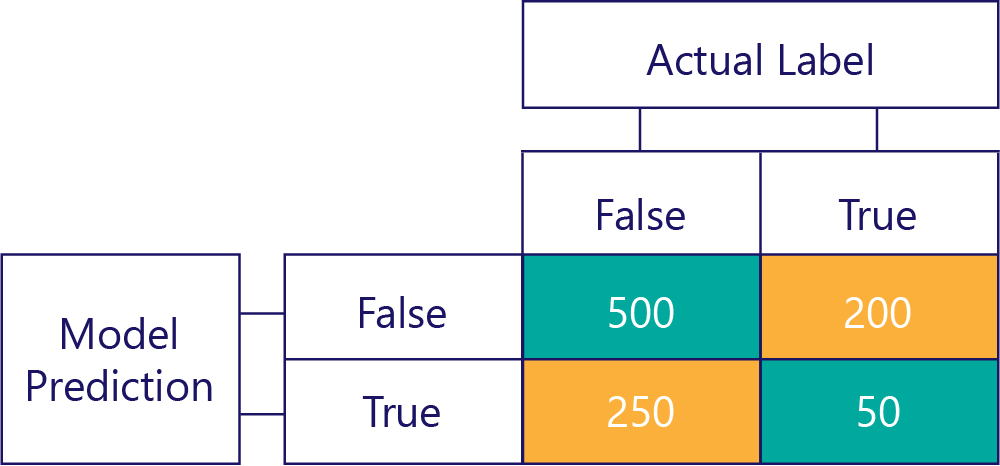
在這裡,我們已為資料格上色,以醒目提示模型有做出正確預測的部分。 從這裡我們不僅會知道模型做出特定類型預測的頻率,還會知道這些預測正確或不正確的頻率。
如果有更多標籤,我們也可以建構更多混淆矩陣。 例如,在我們的人類/動物/樹木範例中,我們可以獲得如下的矩陣:
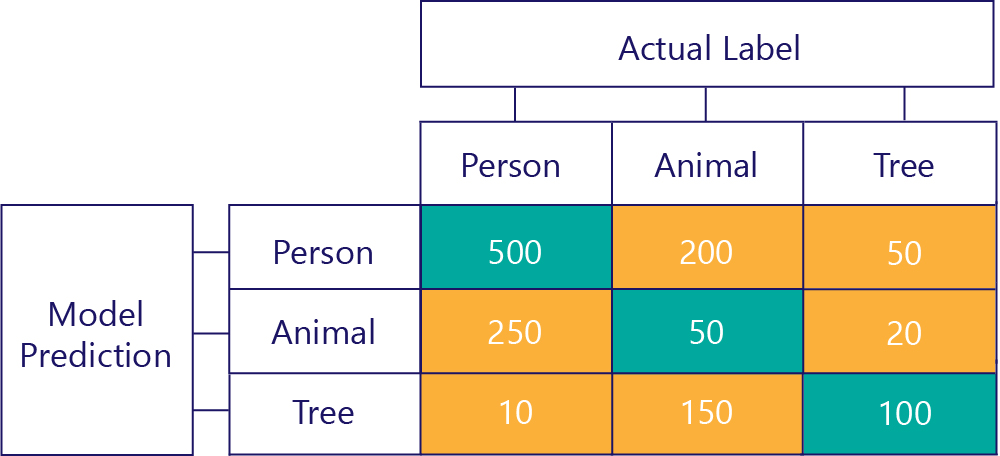
有三個類別時,確判為真之類的計量就不再適用,但我們仍然可以確切地看出模型發生特定種類錯誤的頻率。 例如,我們可以看到模型預測「人類」200 次,但實際的正確結果是「動物」。