資料失衡
當我們的資料標籤有一個以上的類別時,便可說我們有資料不平衡。例如,請回想一下,在我們的案例中,正在嘗試識別無人機感應器找到的物件。 我們的資料不平衡,因為在我們的訓練資料中,登山客、動物、樹木和岩石的數量大不相同。 我們可以藉由將資料製表來看出這一點:
| 標籤 | 登山客 | 動物 | 樹狀結構 | 石頭 |
|---|---|---|---|---|
| 計數 | 400 | 200 | 800 | 800 |
也可以將資料製圖:
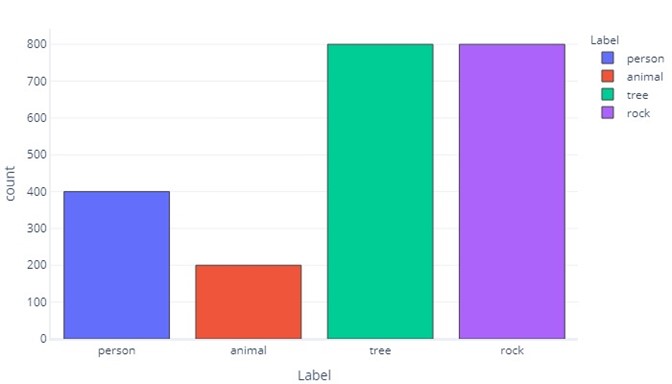
請注意大部分的資料是樹木或岩石。 平衡的資料集不會有這個問題。
例如,如果我們想要預測某個物體是登山客、動物、樹木還是岩石,最好讓所有類別的數量相同,如下所示:
| 標籤 | 登山客 | 動物 | 樹狀結構 | 石頭 |
|---|---|---|---|---|
| 計數 | 550 | 550 | 550 | 550 |
如果我們只想要預測物體是否為登山客,則最好要有同等數量的登山客和非登山客物體:
| 標籤 | 登山客 | 非登山客 |
|---|---|---|
| 計數 | 1100 | 1100 |
為什麼資料失衡很重要?
資料失衡之所以重要,是因為模型可能會明明不想要,卻學著模擬這些失衡的資料。 例如,假裝我們已經訓練了一個羅吉斯迴歸模型,以便將物體識別為登山客或非登山客。 如果訓練資料主要是由「登山客」標籤所組成,則進行訓練時,模型會產生偏差,而幾乎一律傳回「登山客」標籤。 但在真實世界中,我們可能會發現無人機所碰到的大部分物體都是樹木。 有偏差的模型可能會將許多樹木標示為登山客。
發生此現象的原因是,成本函式預設會判斷所提供的回應是否正確。 對於有偏差的資料集來說,這代表想要要讓模型達到最佳表現,最簡單的方法幾乎就是忽略所提供的特徵,並一律或幾乎一律傳回相同的答案。 這可能會造成嚴重的後果。 例如,想像一下我們的登山客/非登山客模型在每 1000 個樣本只有一個包含登山客的資料上進行訓練。 學到每一次都傳回「非登山客」的模型會有 99.9% 的正確性! 此統計資料看似優異,但模型卻毫無用處,因為其永遠不會告訴我們,某人是否在山上,且如果發生雪崩,我們並不知道要進行搜救。
混淆矩陣中的偏差
混淆矩陣是識別資料失衡或模型偏差的關鍵。 在理想的情況下,測試資料的標籤數量會大致相等,模型所做的預測也會平均分散在各個標籤。 有 1000 個樣本時,如果模型沒有偏差,卻往往得到錯誤的答案,其組成可能會如下所示:
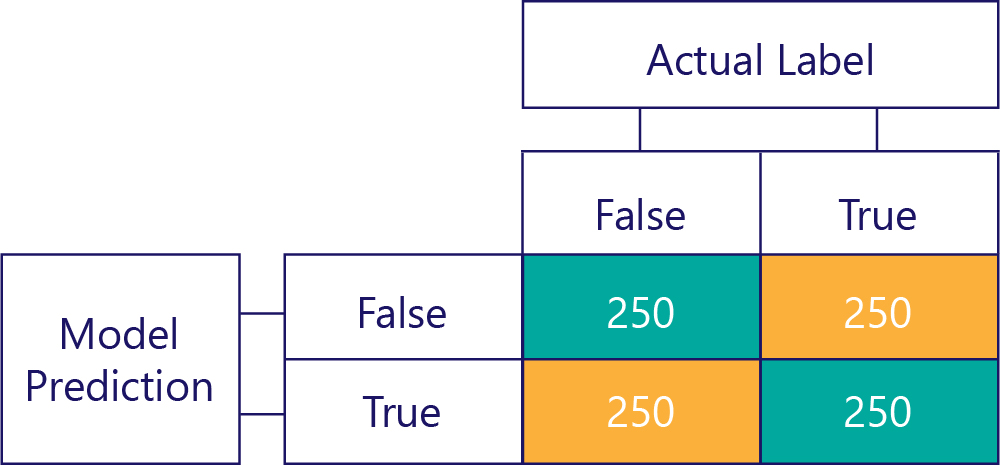
我們可以看得出來輸入資料沒有偏差,因為每一列的總和相同 (均為 500),這表示有一半的標籤是「true」,一半是「false」。 同樣地,我們可以看到模型給的回應也沒有偏差,因為它一半時間傳回 true,另一半時間傳回 false。
相反地,有偏差的資料主要會包含某一種標籤,如下所示:
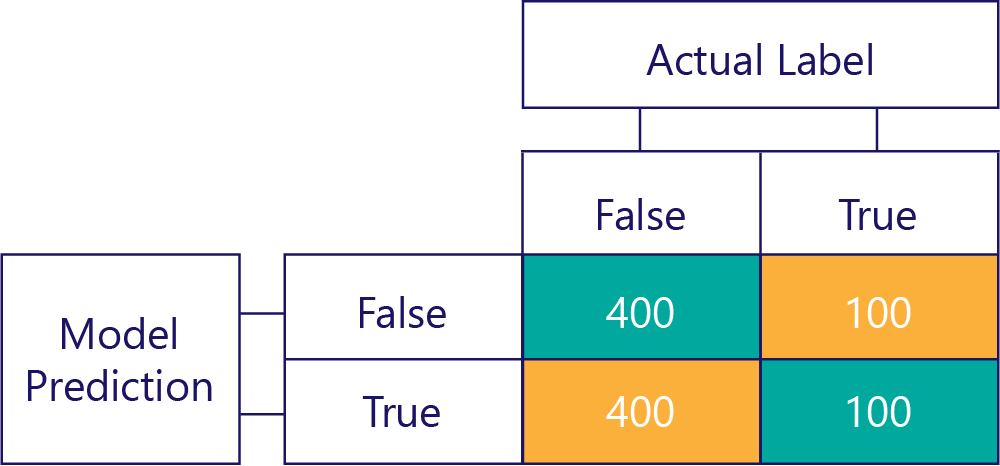
同樣地,有偏差的模型主要會產生某一種標籤,如下所示:
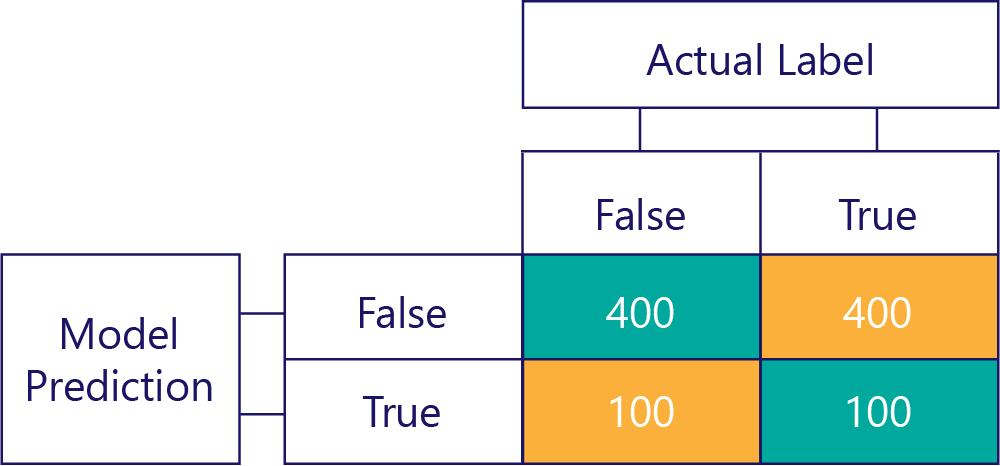
模型偏差與正確性不能劃上等號
請記住,偏差與正確性不能劃上等號。 例如,上述有些範例有偏差,有些則沒有,但都顯示模型僅在 50% 的時間內正確回答。 下面的矩陣是更極端的範例,其顯示的模型雖沒有偏差卻不正確:
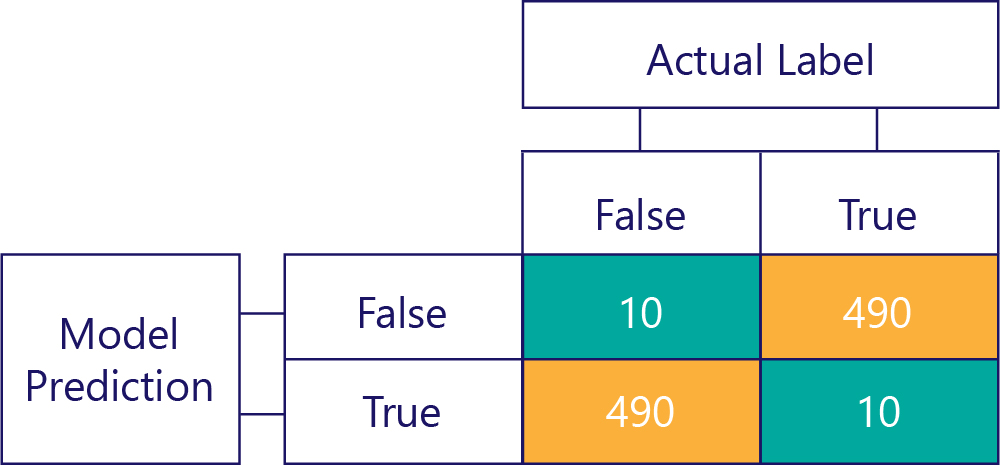
請注意,資料列和資料行的加總數量全都是 500,表示兩個資料都已達到平衡,而且模型沒有偏差。 儘管如此,這個模型的回應卻都幾乎不正確!
當然,我們的目標是讓模型既正確而且沒有偏差,例如:
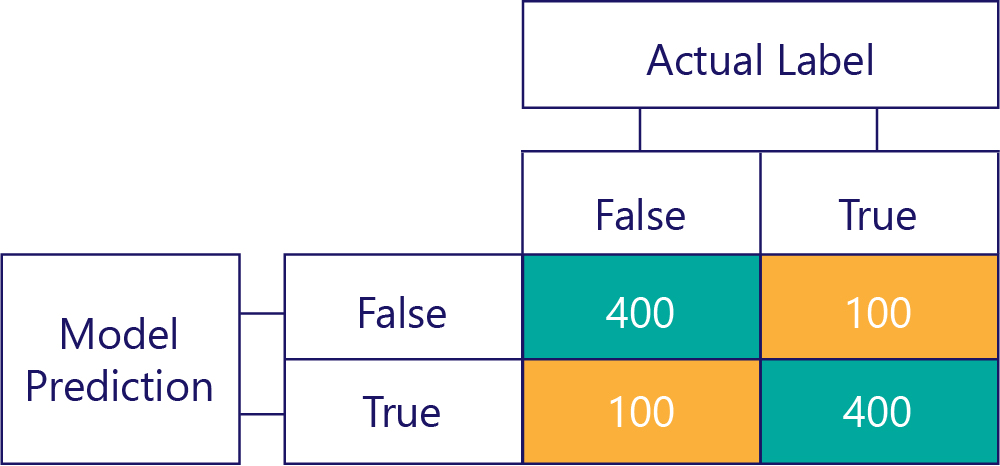
...但我們必須確定我們的正確模型沒有偏差,原因就是資料組成如下:
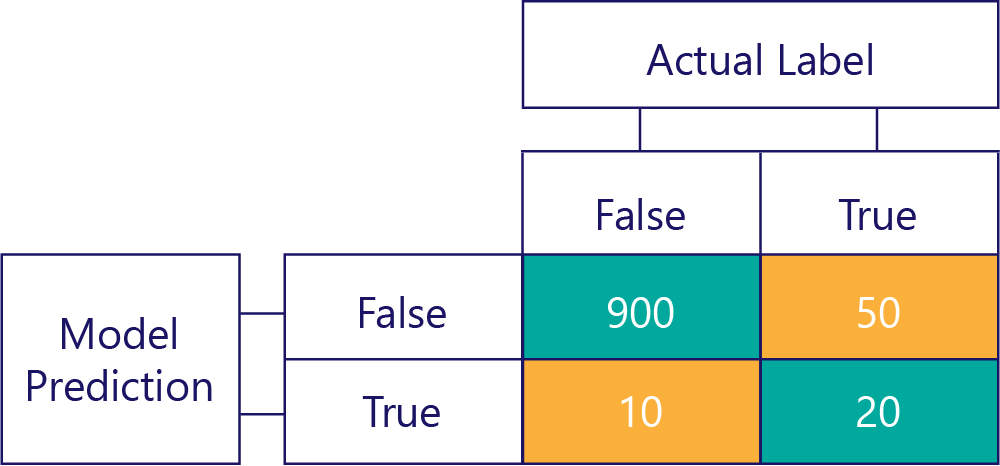
在此範例中,請注意實際標籤大多是 false (左側資料行,顯示資料失衡),而且模型也頻繁傳回 false (頂端資料列,顯示模型偏差)。 此模型本就不善於正確提供「True」回應。
避免資料失衡的後果
想要避免資料失衡的後果,最簡單的一些方式如下:
- 提升資料選取能力來加以避免。
- 「重新取樣」資料,使其包含少數標籤類別的重複項目。
- 變更成本函式,使其優先順序高於較不常見的標籤。 例如,如果針對樹木的回應錯誤,成本函式可能會傳回 1;而如果針對登山客的回應錯誤,則可能會傳回 10。
我們會在下列練習中探索這些方法。