成本函式與評估計量
在過去幾個單元中,我們看到成本函式 (可教導模型) 和評估計量 (用來自行評估模型的方式) 已開始產生分歧。
所有成本函式都可以是評估計量
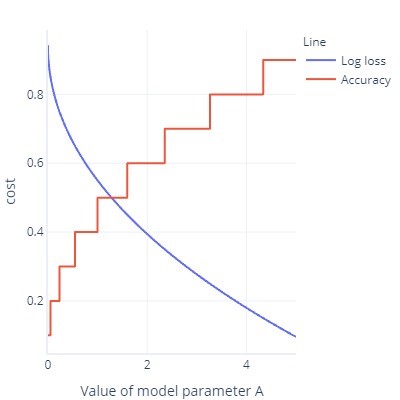
所有成本函式都可以是評估計量,但不一定是直覺想到的那些。 記錄遺失,例如:值不直觀。
某些評估計量不能是成本函式
- 某些評估計量很難成為成本函式
- 這是現實和數學上的條件約束所導致的
- 某些東西有時候不好計算數量 (例如「某個東西有多時髦」)
- 在理想情況下,成本函式很平滑。 例如,正確性很有用,但如果我們稍微變更模型,模型就不會注意到正確性。 由於調整程序會進行許多微小的變更,所以會讓人以為改變不會促成改進。
- 有許多固定位元的成本函式圖形
- 從更早的時候重新整理 ROC 曲線。 這需要將閾值變更為各式各樣的值,但在忙了一整天之後,我們的模型只會有一個 (0.5)
並非都是壞事!
發現我們無法將最愛的計量作為成本函式可能很令人失望。 但也有好的一面,那就是所有計量都是我們所要達成目標的簡化形式;沒有一個是完美的。 這段話的意思是,複雜的模型往往會「作弊」:它們會找出可取得低成本的方法,但又不會真的找出可解決問題的普遍性規則。 擁有不會作為成本函式的計量,等於幫我們做了「健全性檢查」,代表模型沒有找到作弊方法。 如果我們知道模型取巧,就能重新思考訓練策略了。
到現在我們已經看過這種「作弊」情況幾次了。 例如,當模型強烈過度學習訓練資料時,它們基本上是在「記住」正確答案,而非尋找可以成功套用到其他資料的普遍性規則。 我們使用測試資料集作為要評估的「健全性檢查」,以檢查模型是否還沒這麼做。 我們也發現,模型在使用失衡的資料時,有時會只學到一律提供相同的回應 (例如「false」),而不去查看特徵,因為這通常是正確的,偶而才會發生點錯誤。
複雜的模型也會尋找其他取巧方式。 複雜的模型有時會過度學習成本函式本身。 例如,想像一下我們想要建置可繪製犬隻的模型。 我們有一個成本函式,它會檢查影像是否為棕色、顯示毛茸茸的質地,以及包含適當大小的物體。 使用這個成本函式時,複雜的模型可能會學習建立棕色毛球,原因不是它看起來像狗,而是因為它的成本低且容易產生。 如果我們用外部計量來計算腿部和頭部的數目 (因為這些項目不是平滑的計量,因此無法輕易作為成本函式),我們會在模型作弊時很快就注意到,並重新思考我們要如何進行訓練。 相反地,如果我們的替代計量表現不錯,就能比較放心地認為模型已經知道狗是什麼樣子,而不只是引導成本函式來取得較低的值。