開始使用 Azure AI 視覺
電腦系統處理手寫和印刷文字的能力,屬於「電腦視覺」與「自然語言處理」交集的 AI 領域。 首先需要以視覺功能「讀取」文字,再來則需要自然語言處理功能以解讀文字的意義。
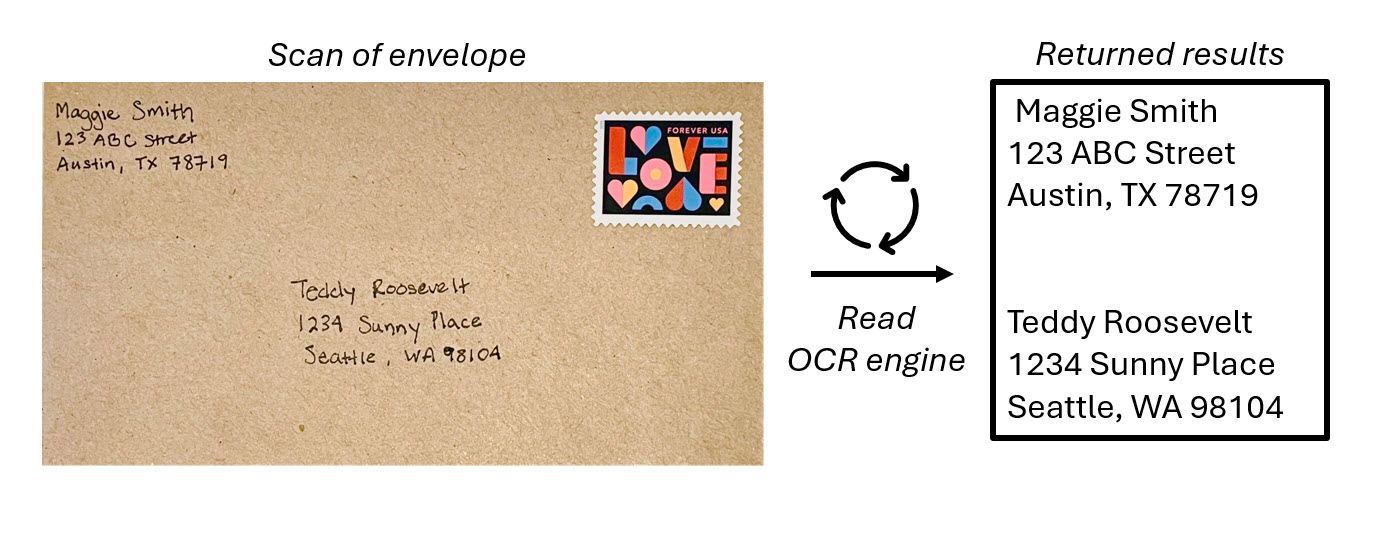
OCR 是處理影像中文字的基礎,並使用定型的機器學習模型,將個別圖形辨識為字母、數字、標點符號或其他文字元素。 執行這類功能的工作早期多見於郵政服務,以支援根據郵遞區號自動分類郵件。 此後,讀取文字的最新技術不斷進步,其現在可建置模型,偵測影像中的文字是印刷或手寫,並逐行或逐字讀取。
Azure AI 視覺的 OCR 引擎
Azure AI 視覺服務能夠從影像中擷取機器可讀取的文字。 Azure AI 視覺的讀取 API 是 OCR 引擎,其可支援從影像、PDF 和 TIFF 檔案擷取文字。 適用於影像的 OCR 已針對一般非檔影像進行最佳化,可讓您更輕鬆地在使用者體驗案例中內嵌 OCR。
讀取 API 也稱為讀取 OCR 引擎,其使用最新的辨識模型,並針對具有大量文字或具有大量視覺雜訊的影像最佳化。 會考量文字行數、包含文字的影像以及手寫內容,自動判斷要使用的適當辨識模型。
OCR 引擎會接受圖像檔,並識別周框方塊或座標,其中項目位於影像中。 在 OCR 中,模型會識別影像中任何看似文字的周框方塊。
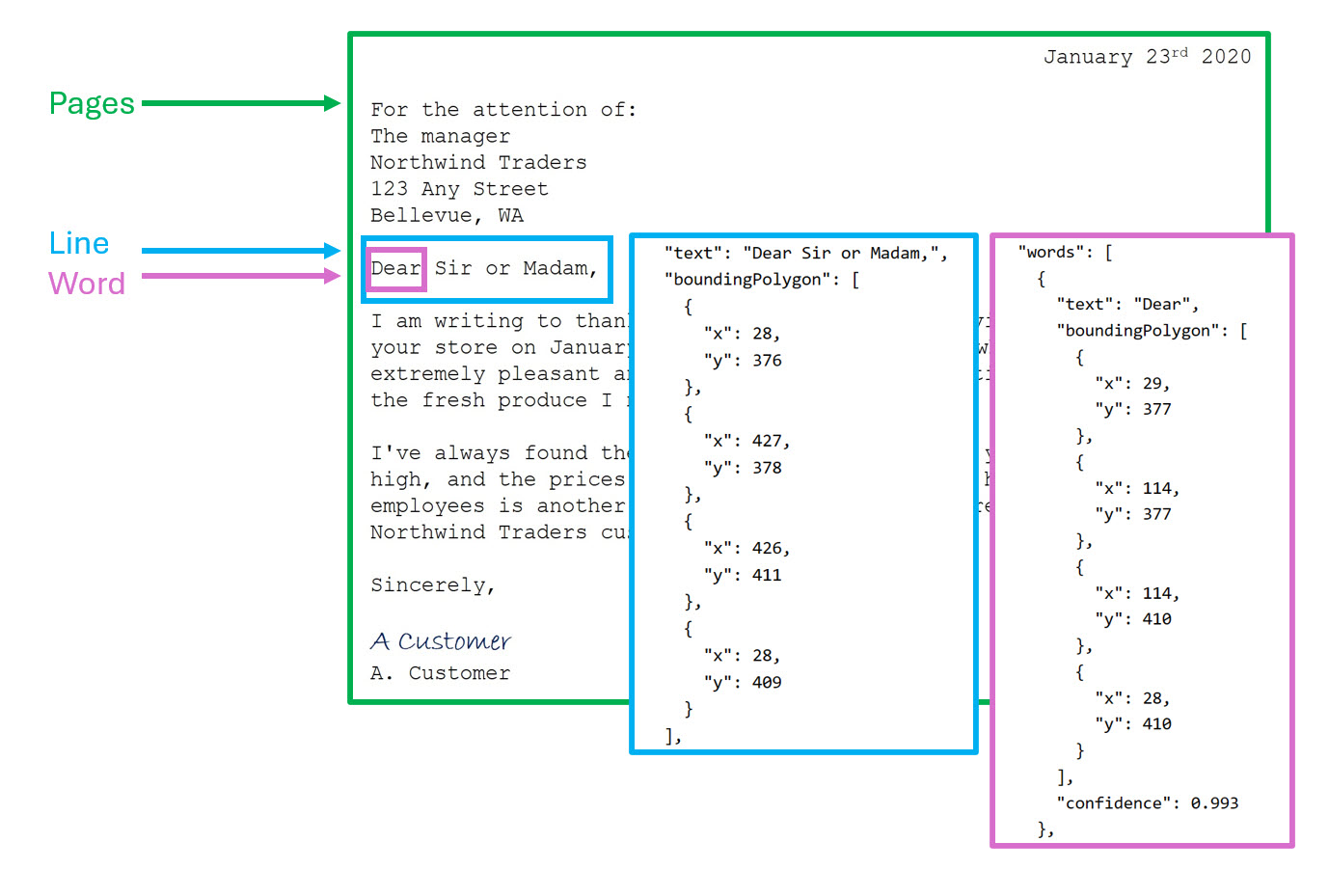
呼叫 Read API 會傳回排列為下列階層的結果:
- 頁面:每頁文字一頁,包括頁面大小和方向的相關資訊。
- 行:頁面上的文字行。
- 單字 - 文字行中的單字,包括週框方塊座標和文字本身。
每一行和每個字詞都包含周框方塊座標,以指出其在頁面中的位置。