測試和訓練資料集
我們用來訓練模型的資料通常會稱為訓練資料集。 我們已看過其運作方式。 無奈的是,當我們在真實世界中使用模型時,並不確定我們的模型是否能完美地運作。 之所以會不確定,是因為我們的訓練資料集可能與真實世界中的資料不同。
什麼是過度學習?
如果模型在訓練資料上的運作效果好過其他資料,則表示模型過度學習。 這個詞是指,事實上模型已調整到非常完美而記下了訓練資料集的所有細節,而非指其會尋找廣泛的規則來套用至其他資料。 過度學習很常見,但並不可取。 在忙了一整天之後,我們只在乎模型是否能完美地在真實世界資料上運作。
如何避免過度學習?
我們可以數種方式來避免過度學習。 最簡單的方式是使用較簡單的模型,或使用更能表示真實世界所見情況的資料集。 若要了解這些方法,請思考真實世界資料如下所示的案例:
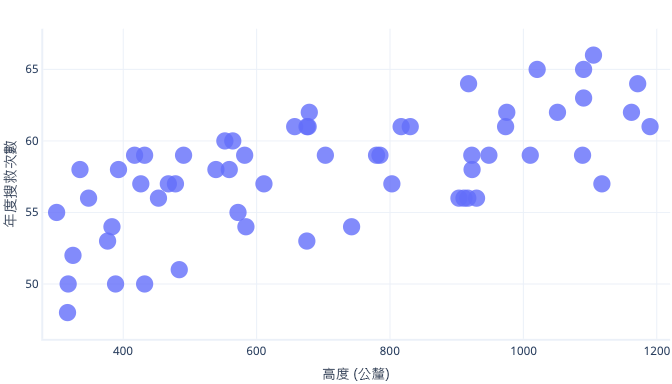
假設我們只收集了五隻狗的相關資訊,並將其做為訓練資料集來調整複雜的趨勢線。 如果做得到,就能完美地調整模型:
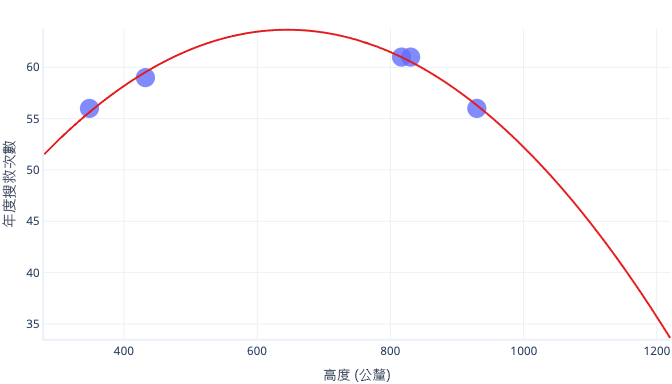
不過,在真實世界中使用此模型時,我們會發現其預測會出錯:
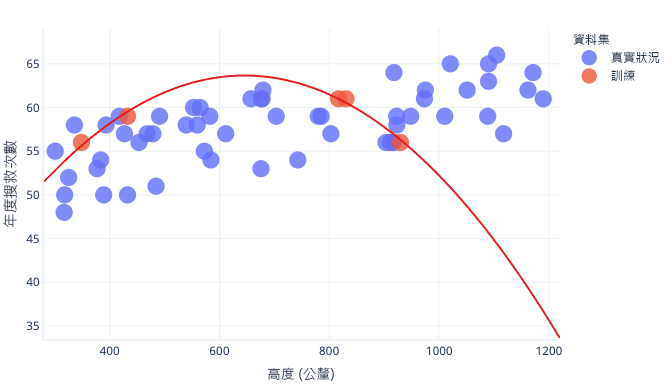
如果我們有更具代表性的資料集和更簡單的模型,則我們調整的趨勢線會變得比較好 (雖然仍非完美) 的預測:
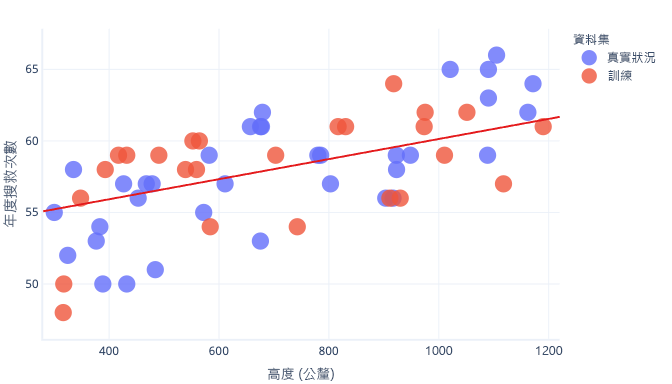
有個不錯的辦法可讓我們避免過度學習,那就是在模型學習到一般規則之後,但在模型過度學習之前停止訓練。 但我們必須在模型快要過度學習時,就偵測到此情況才行。 我們可以使用測試資料集來做到這一點。
什麼是測試資料集?
測試資料集 (也稱為驗證資料集) 是一組類似於訓練資料集的資料。 事實上,我們通常會藉由獲取大型資料集再加以分割,來建立測試資料集。 其中一個部分稱為訓練資料集,另一個部分則稱為測試資料集。
訓練資料集的工作是訓練模型,我們已看過訓練這個部分。 測試資料集的工作則是檢查模型的運作成效;其不會直接參與訓練。
那麼,這有什麼意義?
測試資料集的意義分成兩個部分。
首先,如果測試效果在訓練期間不再提升,就可以停止訓練;繼續訓練並沒有任何意義。 如果繼續訓練,最終只會鼓勵模型去學習不在測試資料集內的訓練資料集細節,這就是過度學習。
其次,我們可以在訓練之後使用測試資料集。 這可讓我們知道,最終模型在看到其以前未曾見過的「真實世界」資料時,會有多好的表現。
這對成本函式有何意義?
當我們同時使用訓練和測試資料集時,最後就會計算兩個成本函式。
第一個成本函式會使用訓練資料集,我們之前已經看過這個部分。 此成本函式會送至最佳化工具,並可用來訓練模型。
第二個成本函式會使用測試資料集來進行計算。 我們會用這個來檢查模型在真實世界中會運作的多好。 成本函式的結果不會用來訓練模型。 為了計算這個部分,我們會暫停訓練、查看模型在測試資料集上的運作情況,然後繼續訓練。