卷積神經網路
雖然您可以針對任何類型的機器學習使用深度學習模型,但它們特別適用於處理包含大量數值數位資料,例如影像。 使用影像的機器學習模型是稱為 計算機視覺的區域人工智慧的基礎,深度學習技術近年來一直負責推動這一領域的驚人進展。
深度學習在這個領域的成功的核心是一種稱為 卷積神經網路或 CNN的模型。 CNN 通常會藉由從影像擷取特徵,然後將這些功能饋送至完全連線的神經網路,以產生預測來運作。 網路中特徵擷取層的效果是將可能龐大的個別圖元值陣列特徵數目減少到支援標籤預測的較小特徵集。
CNN 中的圖層
CNN 由多層組成,每個層都會在擷取特徵或預測標籤時執行特定工作。
捲積層
其中一個主要層類型是一個 捲積 層,可擷取影像中的重要特徵。 捲積層的運作方式是將篩選套用至影像。 篩選是由由加權值矩陣組成的 核心 所定義。
例如,3x3 篩選條件的定義可能如下所示:
1 -1 1
-1 0 -1
1 -1 1
影像也只是圖元值的矩陣。 若要套用篩選,您會在影像上「重疊」它,並計算篩選核心下對應影像圖元值的 加權總和 。 然後,會將結果指派給對等 3x3 填補的中央資料格,此填補位於與影像大小相同的新值矩陣中。 例如,假設 6 x 6 影像具有下列圖元值:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
將濾鏡套用到圖片左上角的 3x3 區塊會像這樣進行:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
結果會被指派給新矩陣中對應的像素值,方式如下:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
現在,篩選條件會向前移動 (「捲繞」),通常會使用「步距」大小 1 (因此向右移動一個像素),然後計算下一個像素的值
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
因此,現在我們可以填入新矩陣的下一個值。
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
過程重複進行,直到我們將濾波器套用至影像的所有 3x3 區塊,以產生如以下值的新矩陣:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
由於篩選核心的大小,我們無法計算邊緣圖元的值;因此,我們通常只會套用 填補 值(通常為 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
卷積的輸出通常會傳遞至啟用函式,這通常是 Rectified Linear Unit (ReLU) 函式,可確保負值設定為 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
產生的矩陣是特徵值的 特徵對應 ,可用來定型機器學習模型。
注意:特徵圖中的值可以大於圖元的最大值(255),因此如果您想要將特徵圖可視化為影像,則必須將特徵值 標準化 為0到255。
卷積程式會顯示在下列動畫中。

- 影像會傳遞至捲積層。 在此情況下,影像是簡單的幾何圖形。
- 影像是由像素陣列所組成,其值介於0到255之間(針對彩色影像,這通常是具有紅色、綠色和藍色色板值的3維數位列)。
- 篩選核心通常會以隨機權數初始化(在此範例中,我們已選擇值來醒目提示篩選條件可能對圖元值產生的效果;但在實際的 CNN 中,初始權數通常是從隨機高斯分佈產生)。 此濾鏡將用來從影像資料擷取特徵圖。
- 濾波器在整個影像上進行卷積運算,通過將權重與每個位置的對應像素值相乘後求和來計算特徵值。 套用修正線性單元 (ReLU) 啟用函式,以確保負值設定為 0。
- 卷積之後,特徵圖會包含擷取的特徵值,而這些值通常強調圖像的主要視覺屬性。 在此情況下,特徵圖會突顯影像中三角形的邊緣和頂點。
一般而言,捲積層會套用多個篩選核心。 每個篩選都會產生不同的特徵地圖,而且所有特徵對應都會傳遞至網路的下一層。
集區層
從影像擷取特徵值之後,會使用 共用 (或 向下取樣)圖層來減少特徵值的數目,同時保留已擷取的主要特徵區分功能。
最常見的池化類型之一是最大 池化,其中濾波器應用於影像,並且只保留濾波器區域內的最大圖元值。 因此,例如,將 2x2 池化核應用於圖像的下列區塊會產生結果 155。
0 0
0 155
請注意,2x2 共享篩選的效果是將值數目從 4 減少為 1。
如同卷積層,池化層的運作方式是將濾器套用於整個特徵圖。 下列動畫顯示影像圖的最大集區範例。

- 卷積層中濾波器所擷取的特徵地圖包含一個特徵值的陣列。
- 共用核心可用來減少特徵值的數目。 在此情況下,核心大小為 2x2,因此會產生特徵值數量減少為四分之一的陣列。
- 集區核心是在整個特徵圖中捲繞,每個位置只保留最高的像素值。
卸除圖層
CNN 中最困難的挑戰之一,就是避免「過度學習」,其中產生的模型可搭配定型資料妥善執行,但不會妥善地一般化為未將其定型的新資料。 您可用來緩解過度學習的技巧之一,就是包含定型程序在其中隨機消除 (或「卸除」) 特徵圖的圖層。 這似乎是反直覺的,但它是確保模型不會學習過度依賴定型影像的有效方法。
您可以用來緩解過度學習的其他技巧包括隨機翻轉、鏡像或扭曲定型影像,以產生在定型 Epoch 之間不同的資料。
壓平合併層
使用卷積和集區圖層來擷取影像中的突出特徵之後,產生的特徵對應會是圖元值的多維度陣列。 壓平合併層用來將特徵圖壓平合併為值的向量,可用來做為完全連線層的輸入。
完全連線層
CNN 通常會以完全連線的網路結尾,其中特徵值會透過一或多個隱藏層傳遞至輸入層,並在輸出層中產生預測值。
基本 CNN 架構看起來可能如下所示:
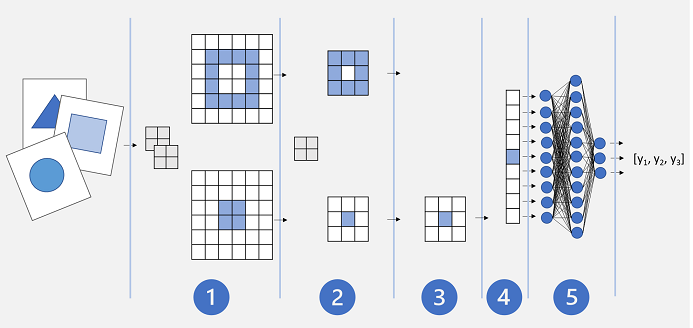
- 影像會饋送至捲積層。 在此情況下,有兩個濾波器,因此每個圖像會產生兩個特徵圖。
- 特徵圖會傳遞至池化層,其中 2x2 池化核心會減少特徵圖的大小。
- 卸除層會隨機卸除部分特徵圖,以協助防止過度學習。
- 扁平化層會處理其餘的特徵圖陣列,並將其扁平化為向量。
- 向量元素會饋送至完全連線的網路,以產生預測。 在此情況下,網路是一種分類模型,可預測三個可能影像類別的機率(三角形、方形和圓形)。
定型 CNN 模型
如同任何深度神經網路,CNN 的定型方式是透過多個 Epoch 傳遞定型資料的批次,並根據針對每個 Epoch 計算的損耗來調整權數和偏差值。 若為 CNN,反向傳播調整的權數包括用於卷積層的篩選核心權數,以及用於完全連線層的權數。