分割數據檔
分區是一種優化技術,使 Spark 能在工作節點間最大化性能。 藉由排除不必要的磁碟 IO,即可在查詢中篩選資料時提升更多效能。
分割輸出檔案
若要將資料框架儲存為分割的檔案集,請在寫入資料時使用 partitionBy 方法。
下列範例會建立衍生 Year 字段。 然後使用它來分割數據。
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
分割數據框架時所產生的資料夾名稱包含資料分割數據行名稱和值,格式為 column=value 格式,如下所示:
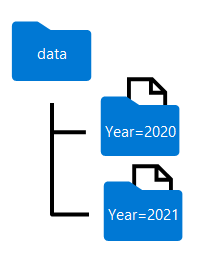
備註
您可以根據多個欄位分割資料,這樣會為每個分割鍵創建一個資料夾階層。 例如,您可以依年份和月份分割範例中的順序,讓資料夾階層包含每年值的資料夾,而資料夾階層會接著包含每個月值的子資料夾。
篩選查詢中的 parquet 檔案
將資料從 parquet 檔案讀取到資料框架時,您能夠從階層式資料夾內的任何資料夾提取資料。 此篩選程式是透過針對分割字段使用明確值和通配符來完成。
在下列範例中,下列程式碼將提取 2020 年下的銷售訂單。
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
備註
在結果資料框中,將省略於檔案路徑中指定的分割欄。 範例查詢所產生的結果不會包含 Year 數據行 ,所有數據列都是從 2020 年開始。