何謂迴歸?
迴歸是簡單、常見且非常實用的資料分析技術,通常稱為「擬合線段」。在最簡單的形式中,迴歸擬合一條介於單一變數 (功能) 和另一變數 (標籤) 之間的直線。 在更複雜的表單中,迴歸可以尋找單一標籤和多個功能之間的非線性關聯性。
簡單線性迴歸
簡單線性迴歸模型:單一功能與通常連續標籤之間的線性關聯性,可讓此功能預測標籤。 視覺上來看會像這樣:
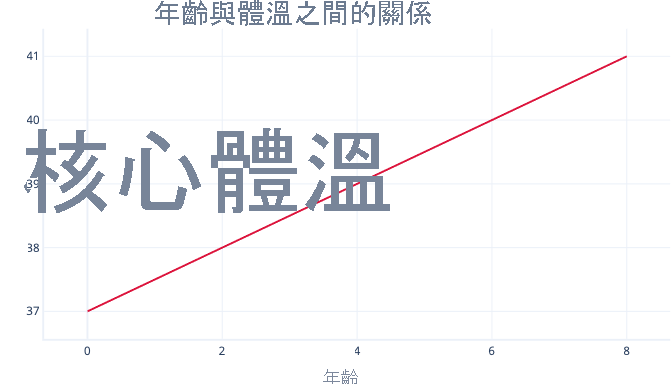
簡單的線性迴歸有兩個參數:攔截 (c) 指出當此功能設定為零時,標籤的值,以及斜率 (m),表示此功能中每 1 點增加的標籤會增加多少。
如果您想要以數學方式思考,這單純就是:
y=mx+c
其中 y 是您的標籤,而 x 是您的功能。
例如,在我們的案例中,如果我們要嘗試預測哪些患者會因發燒而體溫升高 (以其年齡為依據),則會有模型:
溫度=m*年齡+c
而且需要在調整程式期間尋找 m 和 c 的值。 如果找到 m = 0.5 和 c = 37,則可以將其視覺化如下:

這表示每年的年齡都會與體溫增加 0.5 ° C 相關聯,並以 37° C 為起點。
調整線性迴歸
我們通常會使用現有的程式庫,以符合我們的迴歸模型。 迴歸通常是用來找出產生最少錯誤數量的那一行,此處的錯誤表示實際資料點值與預測值之間的差異。 例如,在下圖中,黑色線條表示在預測、紅線和一個實際值:點之間的錯誤。
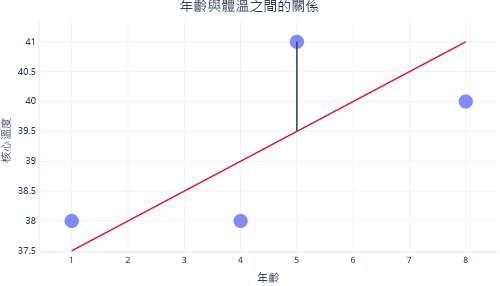
藉由查看 Y 軸上的這兩個點,我們可以看到預測是 39.5,但實際的值是 41。
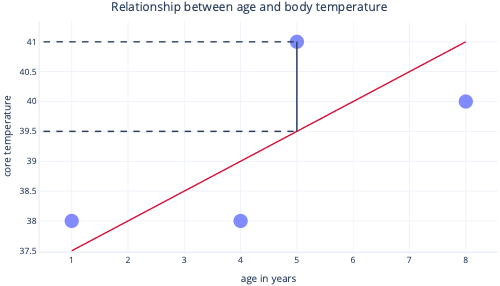
因此,此資料點的模型為 1.5 是錯誤的。
最常見的情況是,我們會將剩餘的平方總和降至最低,以符合模型。 這表示成本函式的計算方式如下:
- 針對每個資料點計算實際值與預測值之間的差異 (如上)。
- 將這些值平方。
- 加總 (或平均) 這些平方值。
這項誤差步驟表示並非所有的點都會平均地參與線條:極端值 (不在預期模式中的點) 有較大比例的錯誤,可能會影響該行的位置。
迴歸的強度
迴歸技術有許多較複雜模型所沒有的優勢。
可預測且容易解讀
迴歸很容易解讀,因為其會描述簡單的數學方程式,讓我們通常可以繪成圖形。 更複雜的模型通常稱為「黑箱」解決方案,因為很難了解其如何進行預測,或其在特定輸入中的行為。
容易推斷
迴歸可讓您輕鬆地推斷;為資料集範圍以外的值進行預測。 例如,在我們先前的範例中,很容易推估一隻九歲狗的體溫為 40.5°C。 對於外推應更加謹慎:此模型會預測一個 90 歲老人的體溫幾乎熱到足以燒開水。
通常可保證最佳的調整
大部分的機器學習模型會使用漸層下降來符合模型,其中牽涉到調整梯度下降演算法,並不保證會找到最佳的解決方案。 相反地,使用平方總和做為成本函式的線性迴歸,其實不需要反覆的梯度下降程序。 相反地,聰明的數學可以用來計算要放置線條的最佳位置。 數學運算不在此課程模組的討論範圍內,但很有用的一點是,只要範例大小不要太大,線性迴歸不需要特別注意調整程序,並保證最佳解決方案。