本文可協助您診斷可用性群組複本之間報告的間歇性連線逾時。
間歇性可用性群組復本連線逾時的徵兆和影響
查詢主要和次要複本會傳回不同的結果
查詢次要複本的唯讀工作負載可能會查詢過時的數據。 如果發生間歇性復本連接逾時,當您查詢相同的數據時,主要復本資料庫上的數據變更尚未反映在輔助資料庫中。 如需詳細資訊,請參閱 次要複 本上的數據延遲一節。
診斷報告可用性群組未同步
SQL Server Management Studio 中的 AlwaysOn 儀錶板可能會報告具有複本處於 「未同步處理 」狀態的狀況不良可用性群組。 您也可以觀察 AlwaysOn 儀錶板報表複本處於 「未同步處理 」狀態。

當您檢閱這些複本的 SQL Server 錯誤記錄時,您可能會觀察到下列訊息,指出可用性群組中的複本之間有連線逾時:
主要復本的錯誤記錄檔
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
次要復本的錯誤記錄檔
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
間歇性連線問題可能會影響次要復本的故障轉移整備程度
如果您設定可用性群組進行自動故障轉移,且同步認可故障轉移夥伴間歇性中斷與主要復本的連線,則自動故障轉移可能會失敗。
您可以查詢 sys.dm_hadr_database_replia_cluster_states 以判斷可用性群組資料庫目前是否已準備好故障轉移。 以下是次要複本上已停止鏡像端點的結果範例:
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

如果故障轉移與複本連線逾時重合,自動故障轉移可能不會讓可用性群組在故障轉移夥伴計算機上的主要角色上線。
線上逾時錯誤指出什麼?
可用性群組複本設定 SESSION_TIMEOUT的預設值為10秒。 此設定會針對每個複本進行設定。 它會決定複本在報告連線逾時之前,等候其夥伴復本收到回應的時間長度。如果複本沒有從夥伴複本取得任何回應,它會報告Microsoft SQL Server 錯誤記錄檔和 Windows 應用程式記錄檔中的連線逾時。 報告逾時的複本會立即嘗試重新連線,並且會每隔五秒繼續嘗試一次。
一般而言,只會偵測到連線逾時,並只由一個複本報告。 不過,這兩個複本可能會同時報告連線逾時。 根據使用先前建立的連線或新的連線是否發生連線逾時,此訊息有不同版本:
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
夥伴復本可能不會偵測到逾時。如果這樣做,它可能會回報訊息 35201 或 35206。 如果沒有,它會向每個可用性群組資料庫報告連線遺失:
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
以下是 SQL Server 回報錯誤記錄檔的範例:如果您停止主要複本上的鏡像端點,次要複本會偵測連線逾時,而次要複本錯誤記錄檔中會報告訊息 35206 和 35267:
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
在此範例中,主要復本未偵測到任何連線逾時,因為它仍可與輔助資料庫通訊,而且會報告每個可用性群組資料庫的訊息 35267(在此範例中,只有一個資料庫 'agdb'):
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
復本聯機逾時的原因
應用程式問題
SQL Server 可能因為數個原因而忙碌,而且不會在可用性群組 SESSION_TIMEOUT 期間內服務鏡像端點連線。 這會導致連線逾時。其中一些原因包括:
SQL Server 體驗 100% 的 CPU 使用率。 這表示 SQL Server 或其他應用程式一次會驅動 CPU 數秒。
SQL Server 體驗非產生排程器事件。 如果線程未及時產生,SQL Server 線程會負責將排程器 (CPU) 傳給其他線程,以完成其工作。
SQL Server 遇到背景工作線程耗盡、記憶體不足問題,或影響其服務鏡像端點連線能力的應用程式問題。
網路問題
這需要您在觸發錯誤時,在主要和次要復本上收集網路追蹤記錄。 若要這樣做,您可以檢查網路等待時間和捨棄的封包。
如何診斷複本聯機逾時
針對導致 SQL Server 無法與夥伴復本連線的應用程式問題,本節說明如何分析 SQL Server 記錄。 這些秘訣可協助您識別複本連線逾時的根本原因。 本節的結尾是關於如何在連線逾時發生時收集網路追蹤的更進階指引,讓您能夠檢查網路狀態。
評估複本聯機逾時的時間和位置
檢閱連線逾時的歷史、頻率和趨勢。 使用您在 SQL Server 錯誤記錄檔中找到的訊息是執行這項操作的絕佳方式。 報告連線逾時的位置? 它們是否一致地報告在主要或次要複本上? 錯誤發生的時間為何? 它們是否發生在當月某一周、一周或一天的時間? 其他排程的維護或批處理是否對應到觀察到連線逾時的時間? 此評量可協助您界定連線逾時的範圍並相互關聯,以找出根本原因。
檢閱AlwaysOn_health擴充事件會話
擴充 AlwaysOn_health 事件會話已增強,以包含 ucs_connection_setup 事件,當復本與其夥伴復本建立連線時,就會觸發此事件。 針對連線逾時問題進行疑難解答時,這很有説明。
注意
擴充 ucs_connection_setup 事件已新增至最新的 SQL Server 累積更新。 您必須執行最新的累積更新,才能觀察此擴充事件。
查詢 AlwaysOn 分散式管理檢視 (DMV)
您可以查詢 Always On DMV 以取得複本連線狀態的詳細資訊。 此查詢只會報告連線狀態,以及發生問題時與連線逾時相關聯的任何錯誤。 如果連線問題間歇性,查詢可能無法輕易擷取中斷連線的狀態。
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
下列範例顯示持續中斷連線的狀態,因為主要複本上的鏡像端點已停止。 藉由查詢主要複本,Always On DMV 可以報告主要複本和所有次要複本(主要複本上的端點已停用)。

藉由查詢次要複本,Always On DMV 只會報告次要複本。

檢閱 AlwaysOn 擴充事件會話
使用 SQL Server Management Studio (SSMS) 物件總管 連線到每個復本,然後開啟
AlwaysOn_health擴充事件檔案。在 SSMS 中,移至 [>檔案開啟],然後選取 [合併擴充事件檔案]。
選取新增按鈕。
在 [開啟檔案] 對話框中,流覽至 SQL Server \LOG 目錄中的檔案。
按 [控件],然後選取名稱開頭為 'AlwaysOn_healthxxx.xel' 的檔案。
選取 [ 開啟],然後選取 [ 確定]。
您應該會在 SSMS 中看到新的索引標籤視窗,以顯示 AlwaysOn 事件。
下列螢幕快照顯示
AlwaysOn_health次要複本的數據。 第一個外框方塊會顯示在主要複本上的端點停止之後的聯機遺失。 第二個大綱方塊會顯示下次次要複本嘗試連線到主要複本時發生的連線失敗。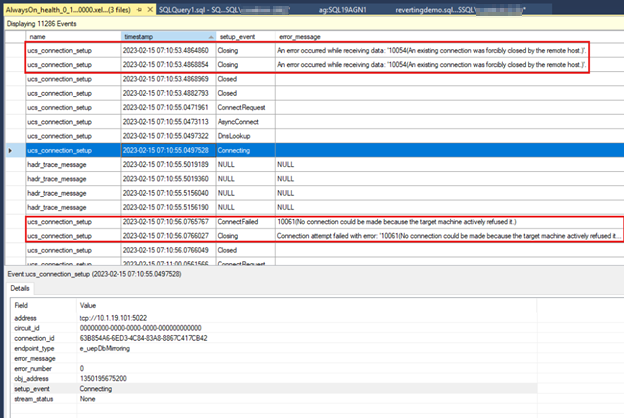

檢查非產生事件是否造成連線逾時
可用性復本無法服務夥伴復本連線的其中一個最常見原因是非產生排程器。 如需非產生排程器的詳細資訊,請參閱 針對 SQL Server 排程和產生進行疑難解答。
SQL Server 會追蹤短到 5 到 10 秒的非產生排程器事件。 它會在元件輸出的數據點中TrackingNonYieldingSchedulersp_server_diagnostics query_processing報告這些事件。
若要檢查可能導致複本連線逾時的非產生事件,請遵循下列步驟:
建立每五秒記錄
sp_server_diagnostics一次的 SQL Agent 作業。在未報告連線逾時的伺服器上排程此作業。也就是說,如果伺服器 A 複本在其錯誤記錄檔中報告複本連接逾時,請在夥伴復本伺服器 B 上設定 SQL Agent 作業。或者,如果您在兩個複本上看到連線逾時,請在這兩個複本上建立作業。
執行下列批處理檔以建立每隔五秒執行
sp_server_diagnostics一次的作業、將輸出附加至文本檔,然後啟動作業。 下列範例sp_server_diagnostics 5中的 命令會每隔五秒執行一次。 因此,不需要排程此作業每隔五秒執行一次,只要啟動作業,就會執行到停止為止,每五秒執行一次:USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'注意
在這些命令中,變更
@output_file_name為有效的路徑並提供檔名。
分析結果
回報連線逾時時時,請注意 SQL Server 錯誤記錄檔中顯示的逾時事件時間戳。 針對下列範例中的複本, SQL19AGN1 報告複本連接逾時。 因此,已在夥伴復本上 SQL19AGN2建立 SQL Agent 作業。 然後,錯誤記錄檔中 SQL19AGN1 報告了 07:24:31 的連線逾時。

接下來,在報告時間檢查執行sp_server_diagnostics之 SQL Agent 作業的輸出,特別是檢 TrackingNonYieldingScheduler 閱元件輸出中的數據 query_processing 點。 輸出會報告在複本連接逾時報告SQL19AGN1 (07:24:33) 上的伺服器SQL19AGN2 (07:24:33) 上追蹤非產生排程器(以非零十六進位值表示)。
注意
sp_server_diagnostics下列輸出會串連以顯示 create_time (timestamp) 和query_processing TrackingNonYieldingScheduler結果。

調查非產生排程器事件
如果您從先前的診斷步驟確認非產生事件導致複本連線逾時:
識別在執行非產生事件時,在 SQL Server 中執行的工作負載。
與復本聯機逾時類似,請在發生的月份、日或周中尋找這些事件的趨勢。
收集偵測到非產生事件之系統上的效能監視器追蹤。
收集系統資源的主要性能計數器,包括 Processor::% Processor Time、Memory::Available MBytes、 Logical Disk::Avg Disk Queue Length 和 Logical Disk::Avg Disk sec/Transfer。
如有必要,請開啟 SQL Server 支援事件,以進一步協助找出這些非產生事件的根本原因。 共用您收集的記錄,以進行進一步分析。
進階數據收集:在連線逾時期間收集網路追蹤
如果先前的 SQL Server 應用程式診斷沒有產生根本原因,您應該檢查網路。 網路的成功分析需要您收集涵蓋連線逾時時間的網路追蹤。
下列程式會在 SQL Server 錯誤記錄檔中報告連線逾時之複本上啟動 Windows netsh 網路追蹤。 當應用程式記錄檔中記錄其中一個 SQL Server 連線錯誤時,就會觸發 Windows 排程事件工作。 排程的工作會執行命令來停止 netsh 網路追蹤,以便不會覆寫密鑰網路追蹤數據。 這些步驟也會假設批次和追蹤記錄的路徑為 *F:*。 將此路徑調整為您的環境。
在聯機逾時發生的兩個複本上,啟動網路追蹤,如下列代碼段所示:
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etl建立 Windows 排程工作,以停止
netsh事件 35206 或 35267 上的追蹤。 您可以在系統管理指令列建立這些工作:schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHEST事件發生且網路追蹤停止並擷取之後,您可以刪除工作
ONEVENT:PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
網路追蹤的分析超出此疑難解答員的範圍。 如果您無法解譯網路追蹤,請連絡 Microsoft SQL Server 支援小組,並提供追蹤以及其他要求的記錄檔,以進行根本原因分析。
我還能做些什麼來減輕連線逾時?
預設可用性群組 SESSION_TIMEOUT會設定為10秒。 您可以藉由調整可用性群組複本 SESSION_TIMEOUT 屬性來減輕連線逾時。 此設定是每個複本。 針對主要復本和每個受影響的次要複本調整它。 以下是語法的範例。 預設值 SESSION_TIMEOUT 為 10。 因此,您可以使用 15 做為下一個值。
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);